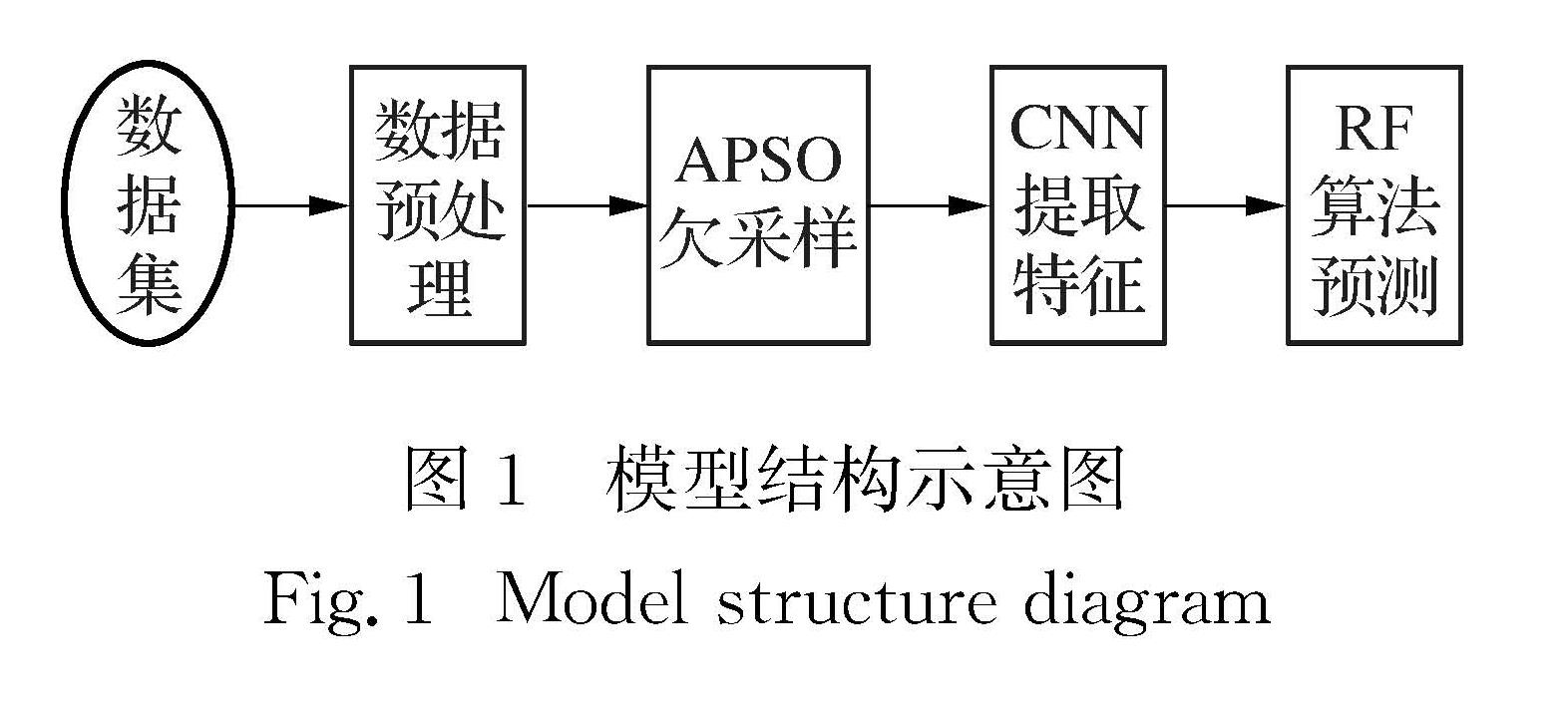
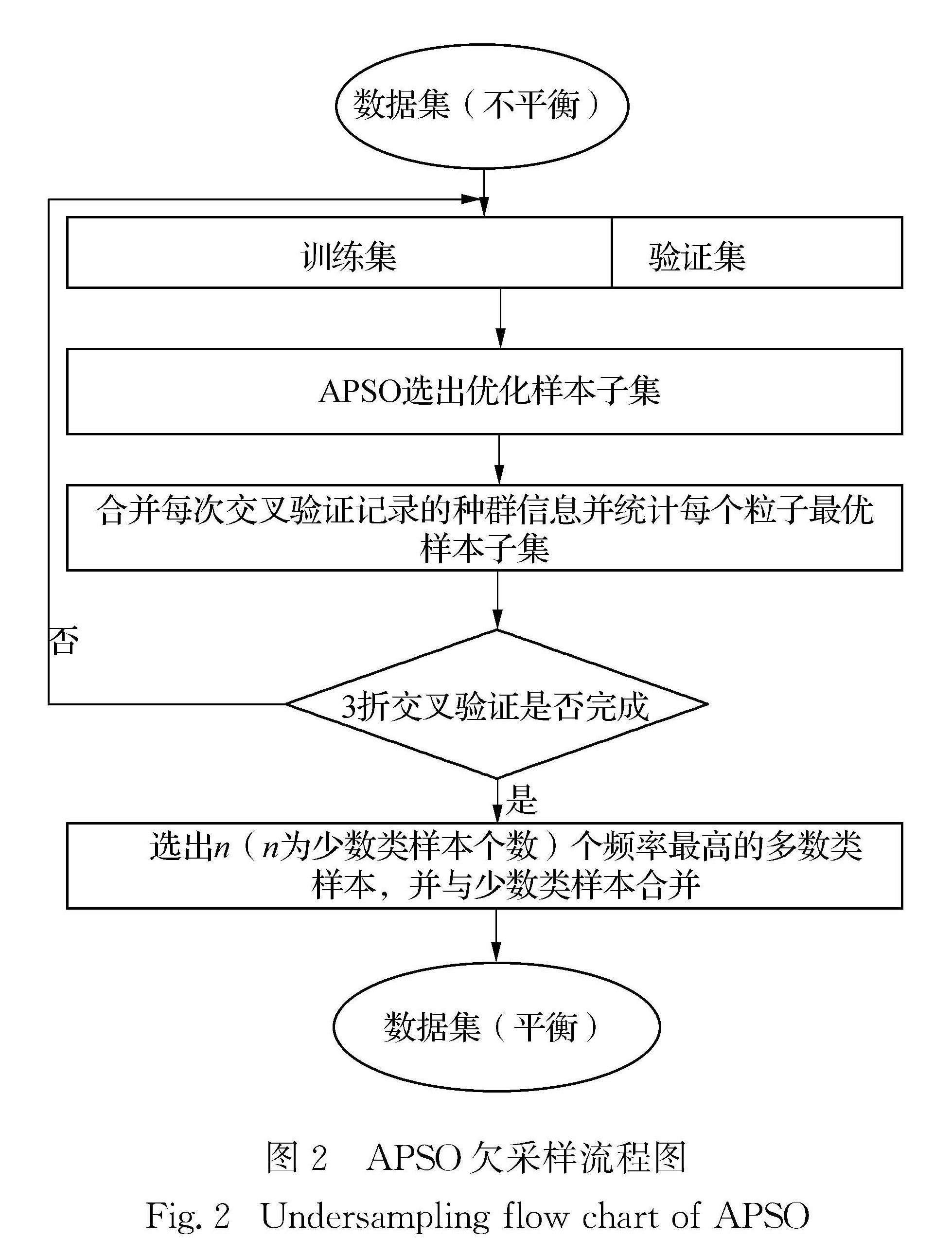
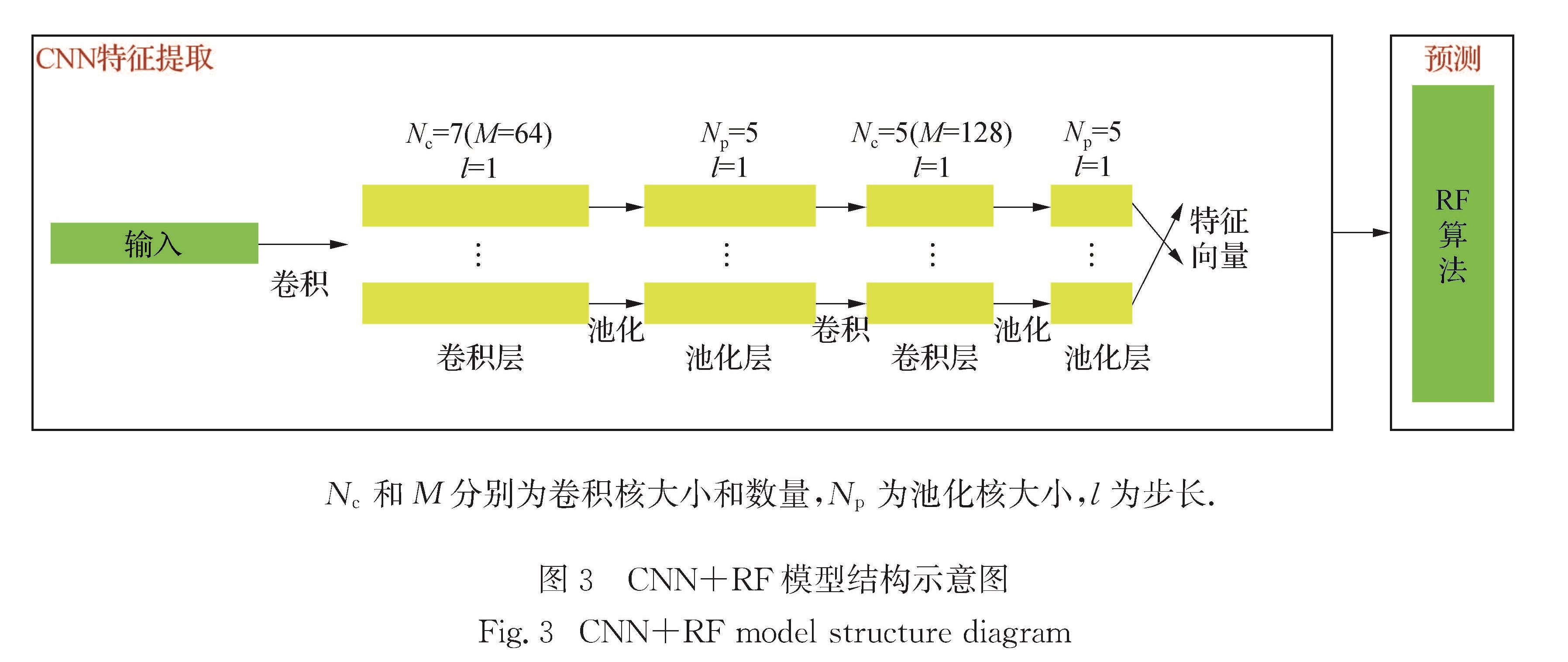
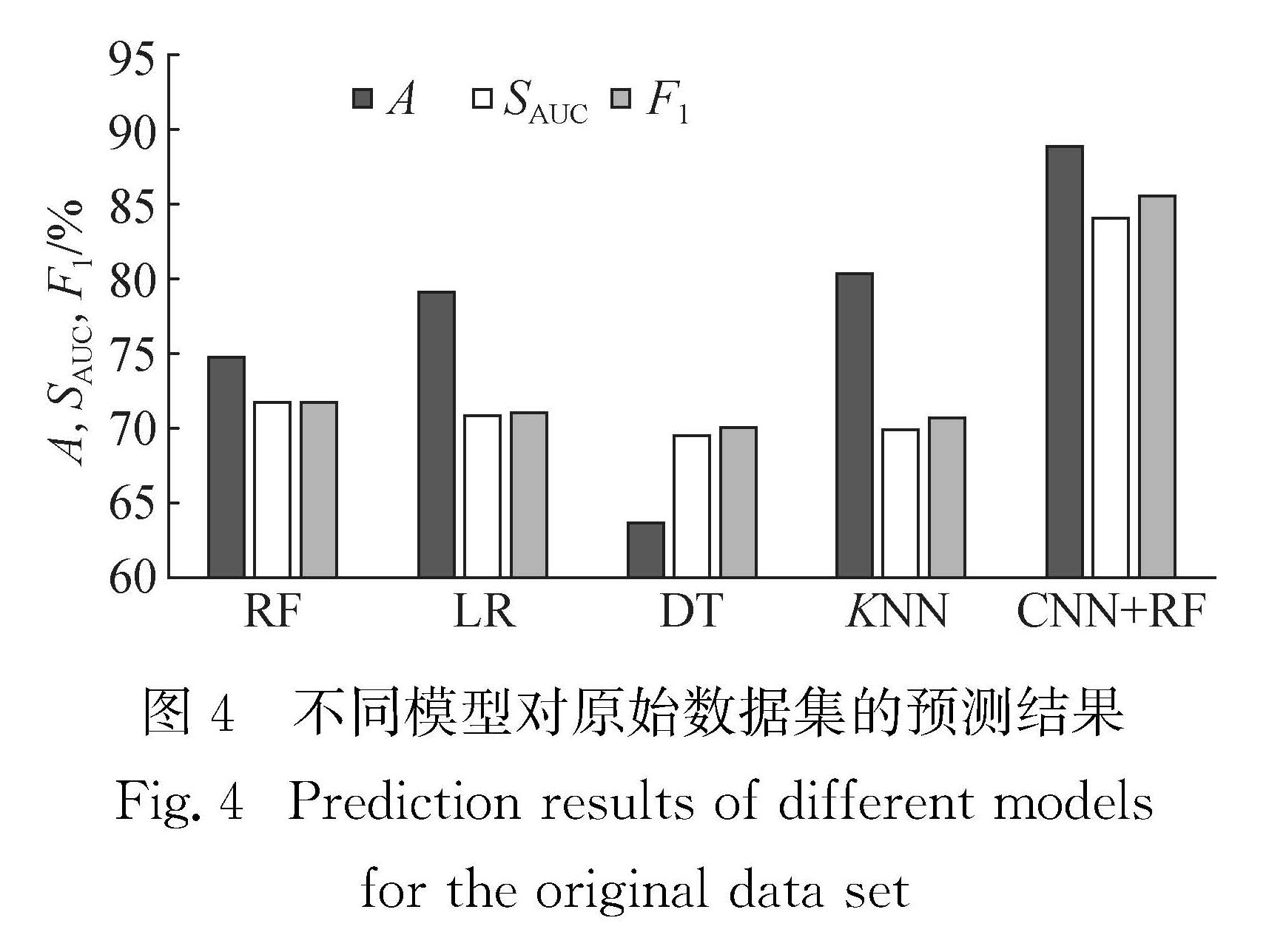
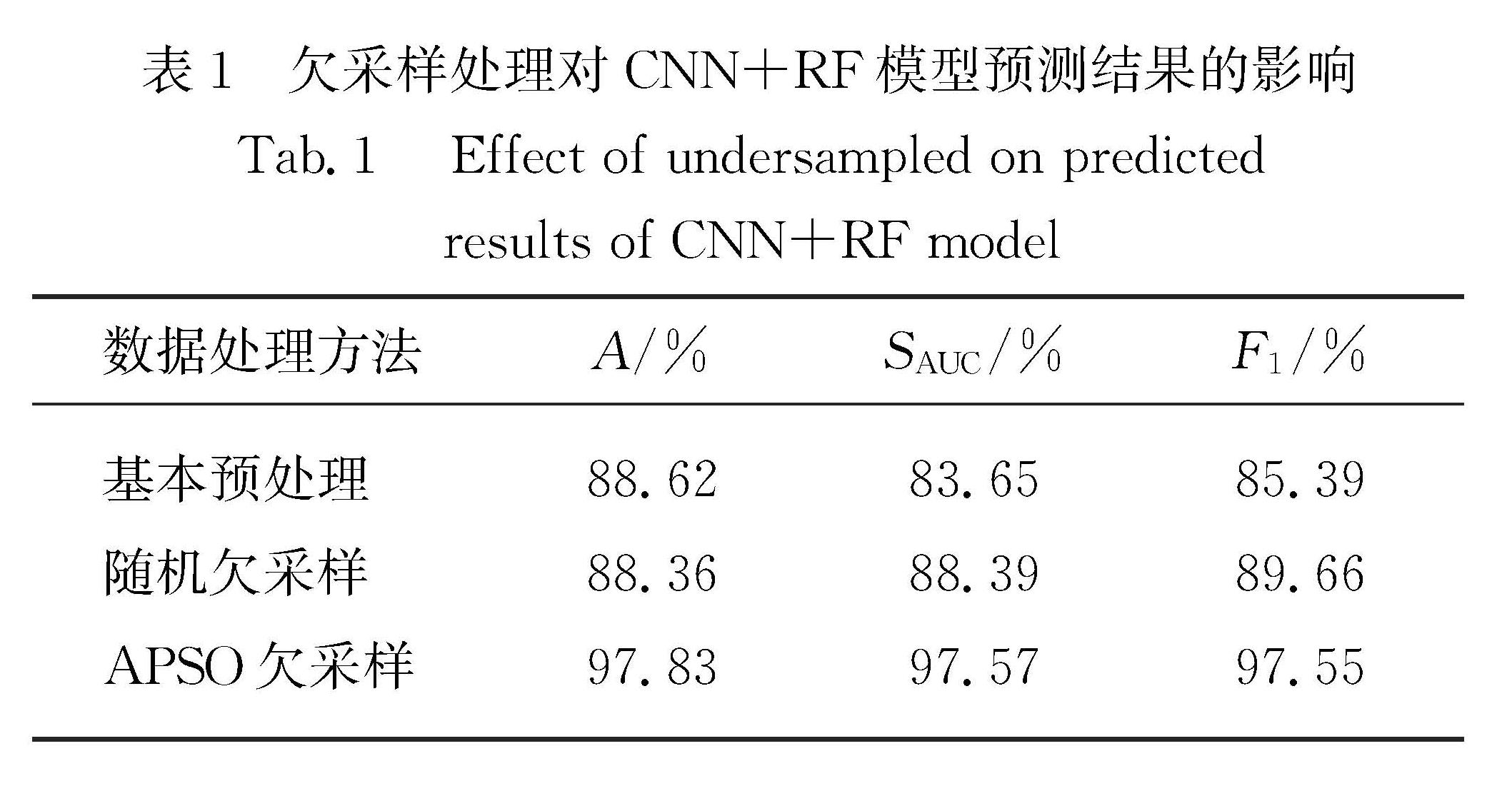
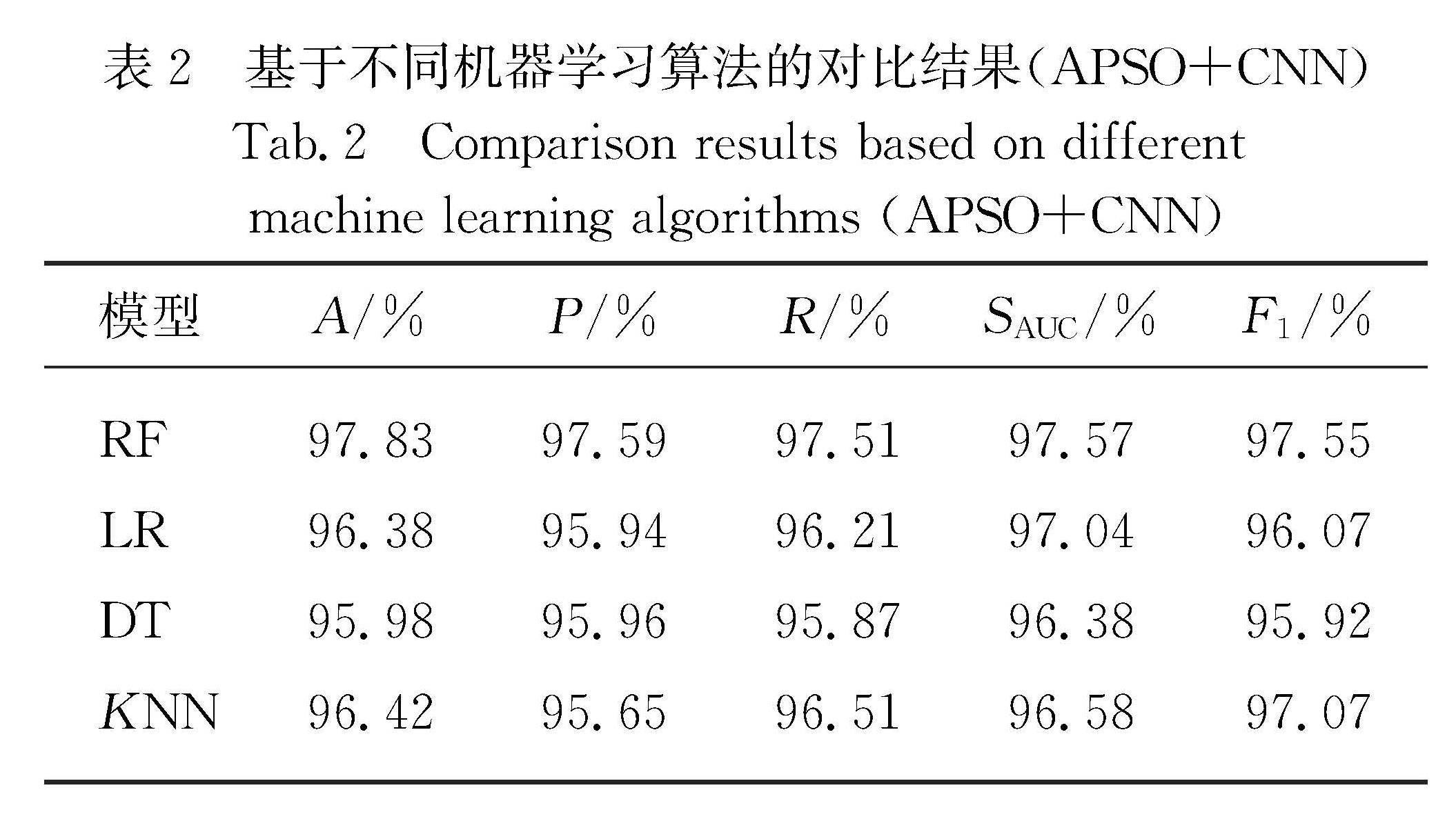
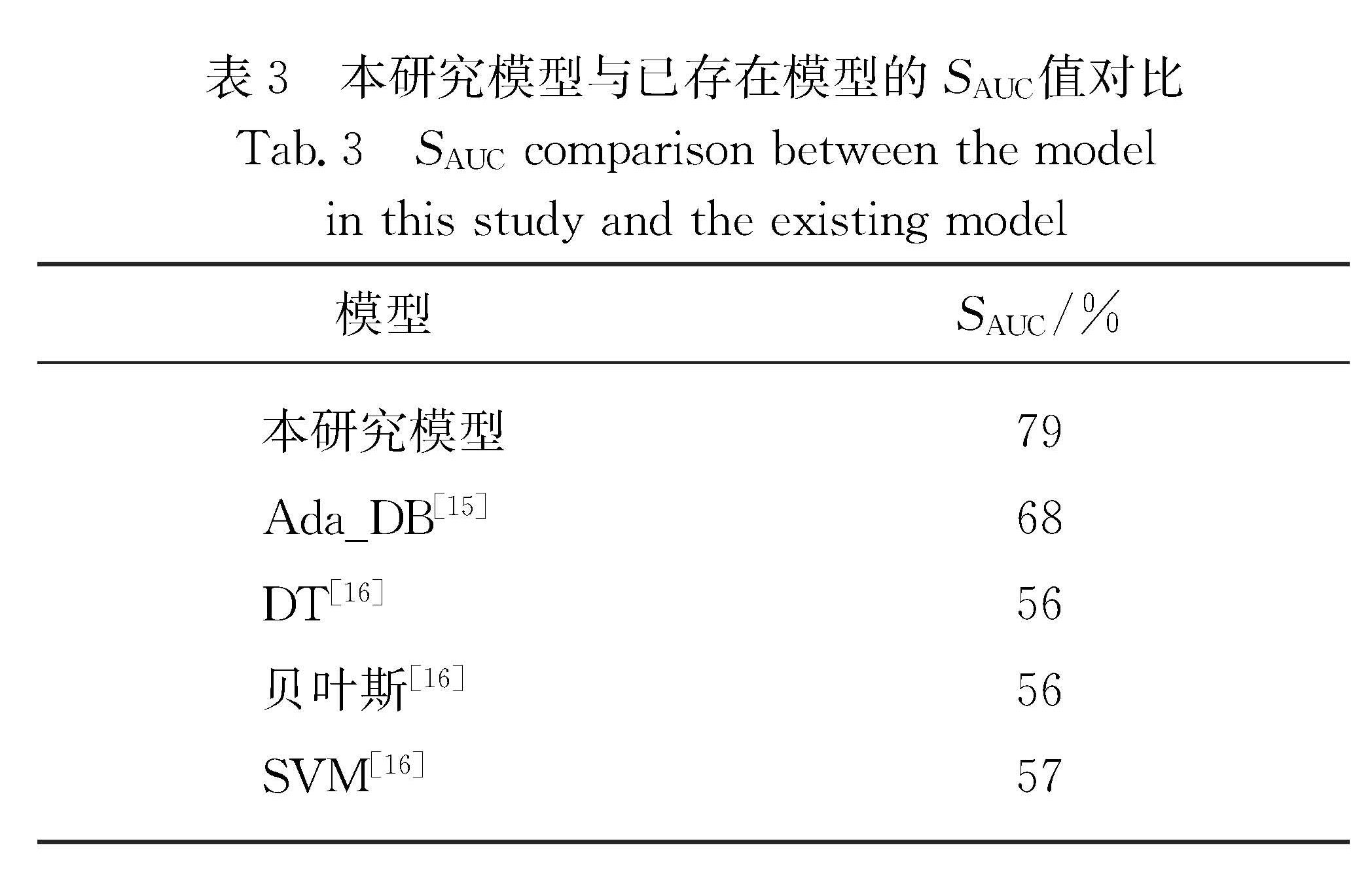
航空业的竞争愈发激烈,高效且准确的客户忠诚度预测模型有利于提高企业竞争力.针对航空数据集存在严重分类不平衡、特征维度多等问题,提出了客户忠诚度预测模型.该模型基于自适应粒子群优化(APSO)算法得到多数类优化样本子集,使用卷积神经网络(CNN)提取得到的平衡数据集特征,将自动得到的特征向量作为随机森林(RF)算法的输入,构建客户忠诚度预测模型.实验结果表明,该方法预测性能优于其他预测模型,可以更好地预测客户忠诚度.
As the competition for customers' patronage in the aviation industry becomes increasingly fierce,an efficient and accurate customer loyalty prediction model is conducive to improving corporate competitiveness.Aiming at the problem of severe classification imbalance and the high feature dimension,we propose a prediction model of customer loyalty.In this algorithm,a majority of optimized sample subsets is obtained by an adaptive particle swarm optimization algorithm(APSO),and then the balanced data set is extracted using the convolutional neural network(CNN).Finally,the automatically obtained feature vector is used as the input of the random forest(RF)algorithm to construct the customer loyalty prediction model.Experimental results show that the proposed model performs more satisfactorily than other prediction models do,and that it can predict the customer loyalty situation more accurately than others can.