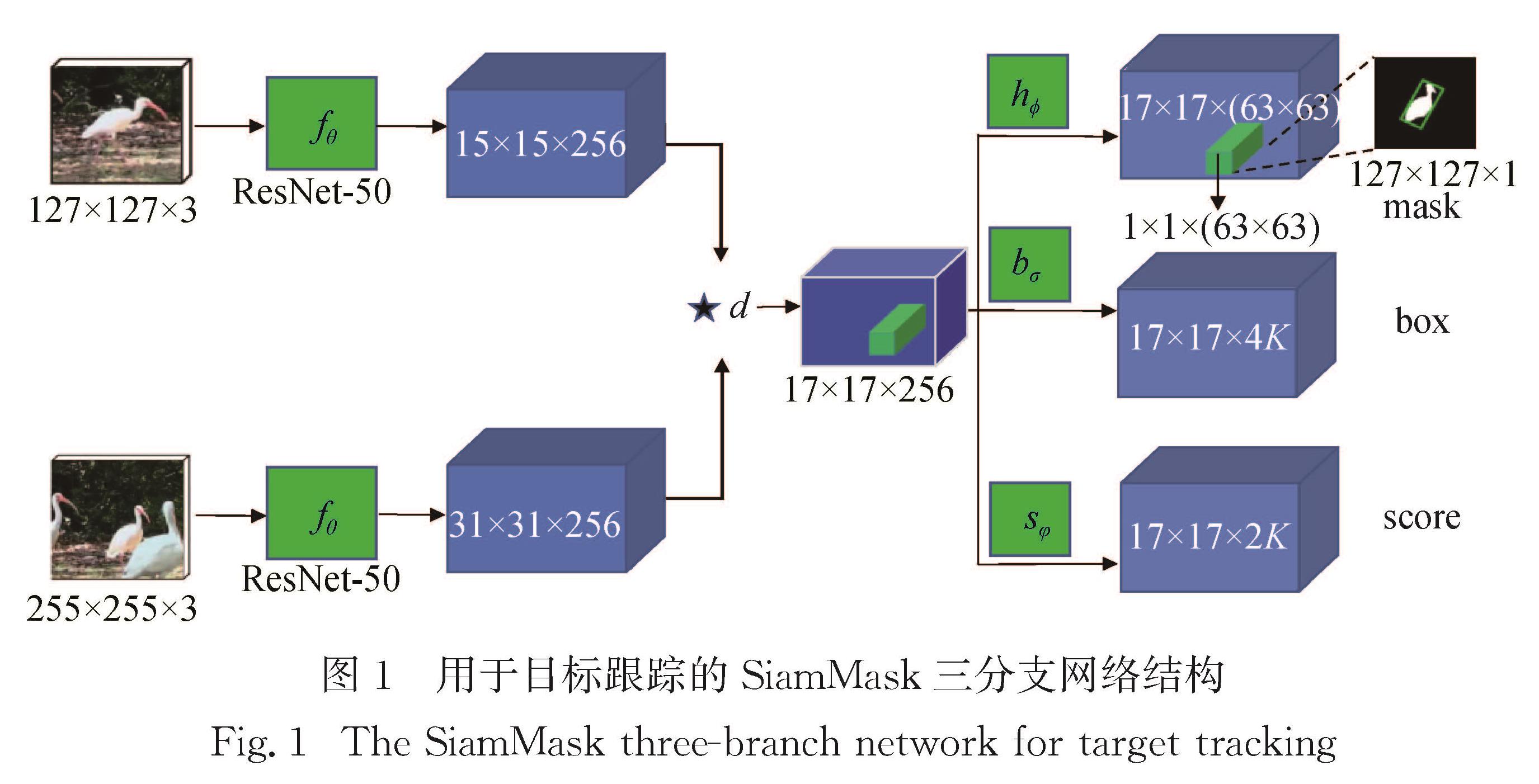
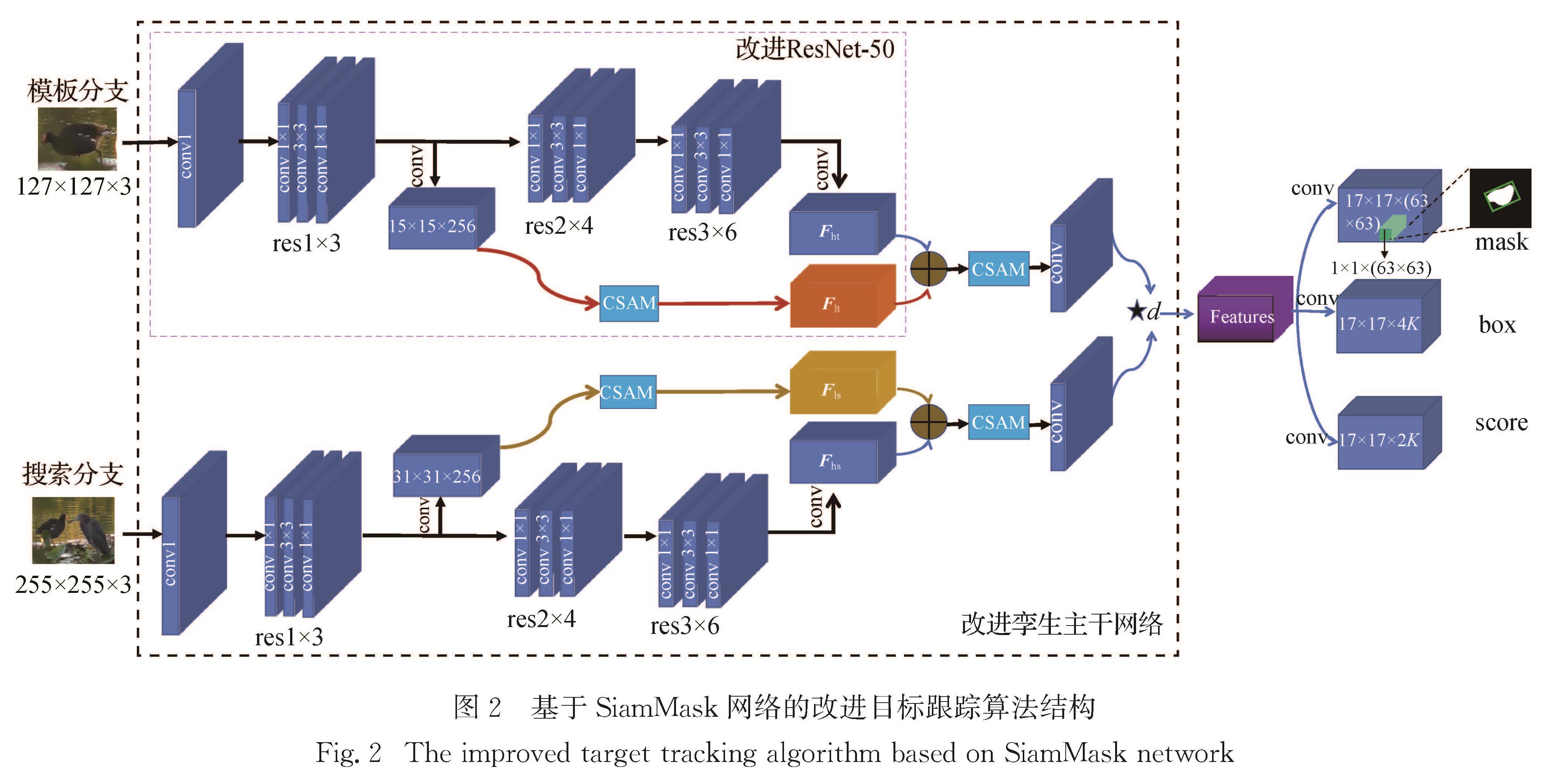
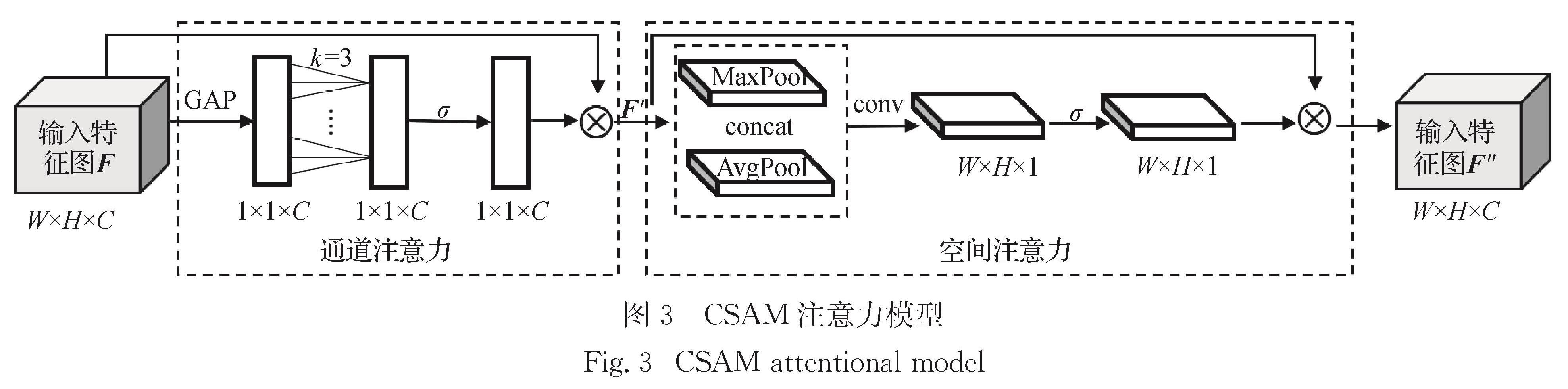
实验平台采用Ubuntu16.04和pytorch深度学习框架,选用NVIDIA GeForce RTX 2080显卡和CUDA11.0对数据集进行训练,训练过程设定15个epoch,其中前5个epoch是预训练阶段,学习率从1×10-3增加到5×10-3,后10个epoch学习率逐渐降低.每批次训练图片数量(batch size)为16张图像对,训练时使用随机梯度下降法对参数进行优化.为了更好地应对目标尺度变化,锚框设置了5种尺度.
本文使用COCO[14]、ImageNet-DET 2015[15]、ImageNet-VID 2015[15]和YouTube-VOS[16]4个数据集对网络进行训练,使用VOT2016[17]、VOT2018[18]数据集作为测试集,每个测试数据集各有60个视频序列,包含多个目标跟踪的挑战因素,如相机运动、运动模糊、运动变化等.
VOT数据集使用跟踪准确率A、鲁棒性R和期望平均覆盖率EAO作为评价指标.
跟踪准确率由真实框与预测框的IOU来定义,第t帧的准确率定义为:
Φt=S(At∩Agt)/S(At∪Agt),(10)
其中,S表示面积,At表示预测框,Agt表示真实框.而对于整个视频序列的准确率可以定义为:
A=N-1valid∑Nvalidt=1Φt,(11)
其中,Φt为第t帧的准确率,Nvalid为有效视频帧数.
R是衡量跟踪器目标跟踪的稳定性的量,定义为:
R=(F/NF)×100%,(12)
其中,F为跟丢帧数,NF为数据集中的总帧数.
EAO用于同时评估跟踪器的准确性和鲁棒性,首先计算第s段长度为Ns的视频序列的平均准确率:
(^overΦ)(Ns)=N-1s∑Nst=1Φs,t,(13)
式中,Φs,t为第s个长度为Ns的视频序列第t帧的准确率.最后在长度范围[Nlo,Nhi]上对所有长度序列的准确率进行平均,得到期望平均覆盖率:
Φ(Nlo,Nhi)=(Nlo-Nhi)-1∑NhiNs=Nlo(^overΦ)(Ns),(14)
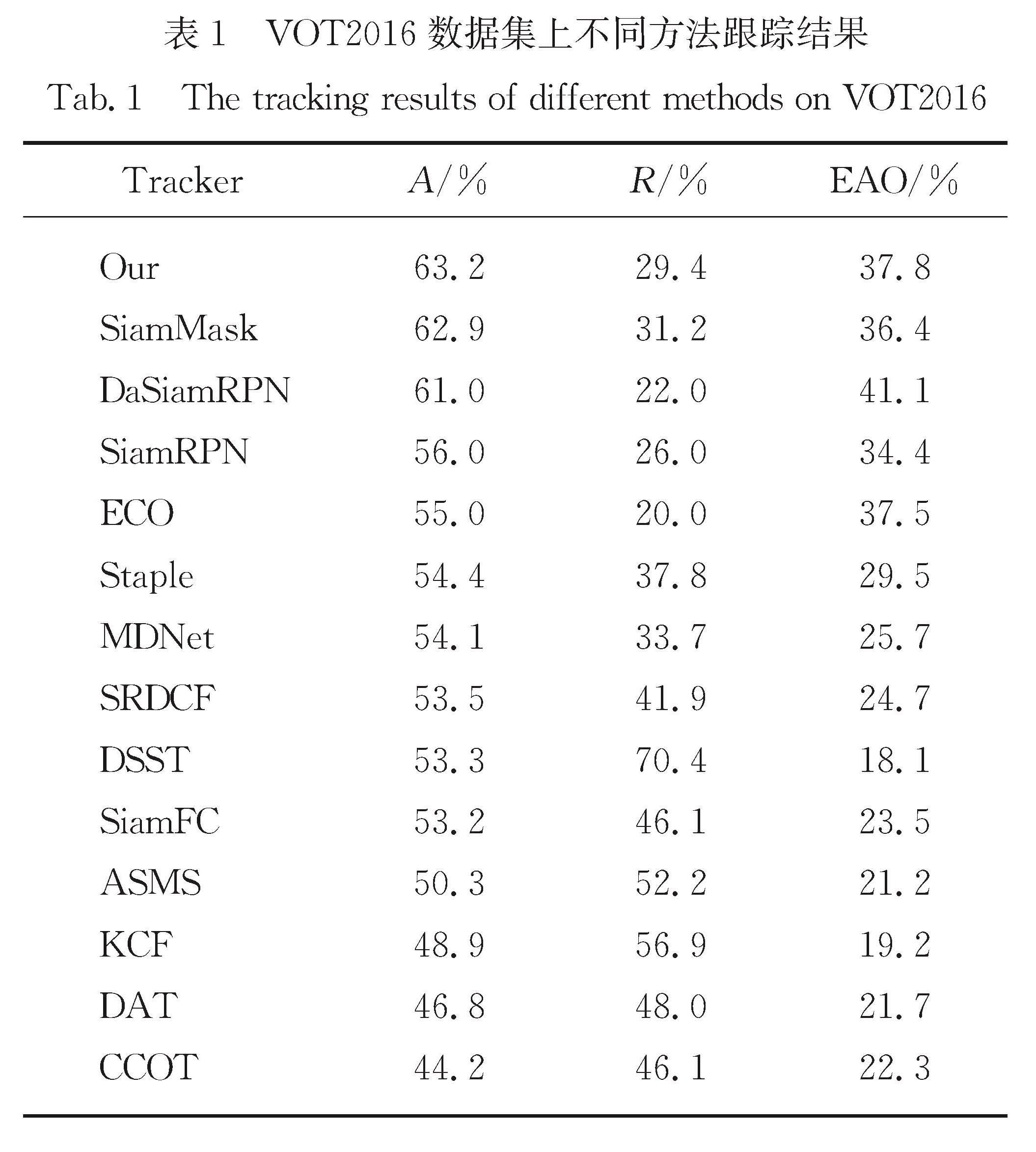
为了充分验证本文方法的性能,对比本文算法和DaSiamRPN[19],ECO[20],SRDCF[21],MDNet[22],Staple[23],DSST[24],ASMS[25],CCOT[26],DAT[27]等算法在VOT2016数据集上的测试结果(表1).由表1可知,本文算法跟踪准确率为63.2%,在所列算法中最高; 而鲁棒性能和期望平均覆盖率分别为29.4%和37.8%,与所列算法具有可比性.具体分析:1)与基准SiamMask算法比较,本文算法准确率略有提升,鲁棒性优化了1.8个百分点,期望平均覆盖率提高了1.4个百分点.2)与SiamFC相比,本文算法使用锚框机
表1 VOT2016数据集上不同方法跟踪结果
Tab.1 The tracking results of different methods on VOT2016
制,能够更好拟合目标位置,在3个指标上都得到较好改进.3)与KCF、ECO等传统相关滤波算法相比,本文方法使用深度学习结合注意力机制,有效提升动态目标运动变化、背景杂乱等场景的跟踪能力.
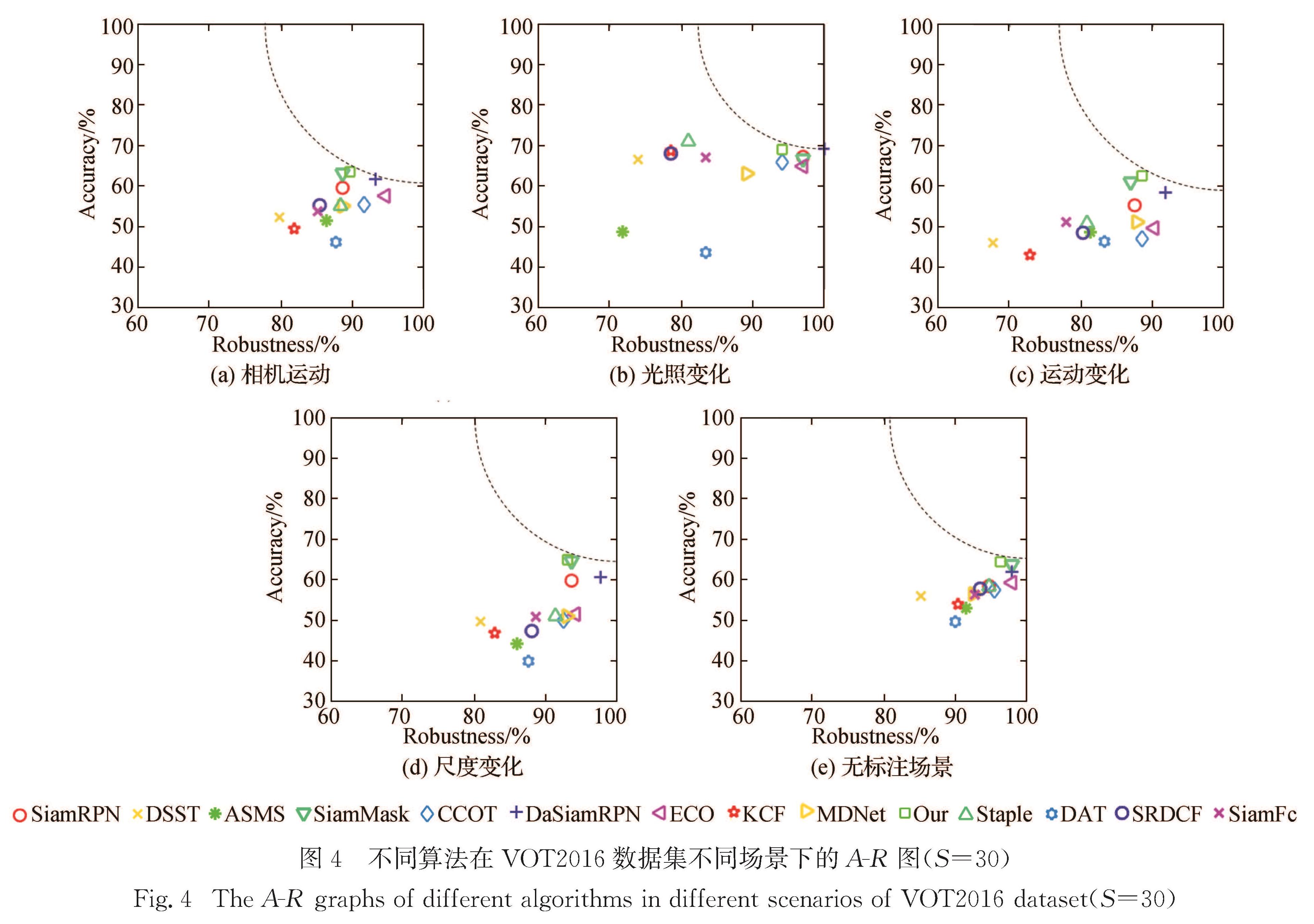
图4 不同算法在VOT2016数据集不同场景下的A-R图(S=30)
Fig.4 The A-R graphs of different algorithms in different scenarios of VOT2016 dataset(S=30)
图4为各算法在VOT2016数据集上相机运动、光照变化、运动变化、无标注场景、尺度变化场景的A-R图(此处的R是根据VOT数据集官方定义的鲁棒性,与上文的R并不一样,文中仅图5与此处R的定义一致),其中,S表示预期可连续跟踪的视频帧.可以看出:本文算法由于使用通道和空间注意力机制,并充分考虑融合浅层特征,在相机运动、目标运动变化场景下的A-R图中相较于基准算法明显更靠近坐标系的右上角,表示性能更好; 在其他场景下,本文算法在准确率上也具有一定优势,与其他算法各场景下的对比结果也具有一定可比性.
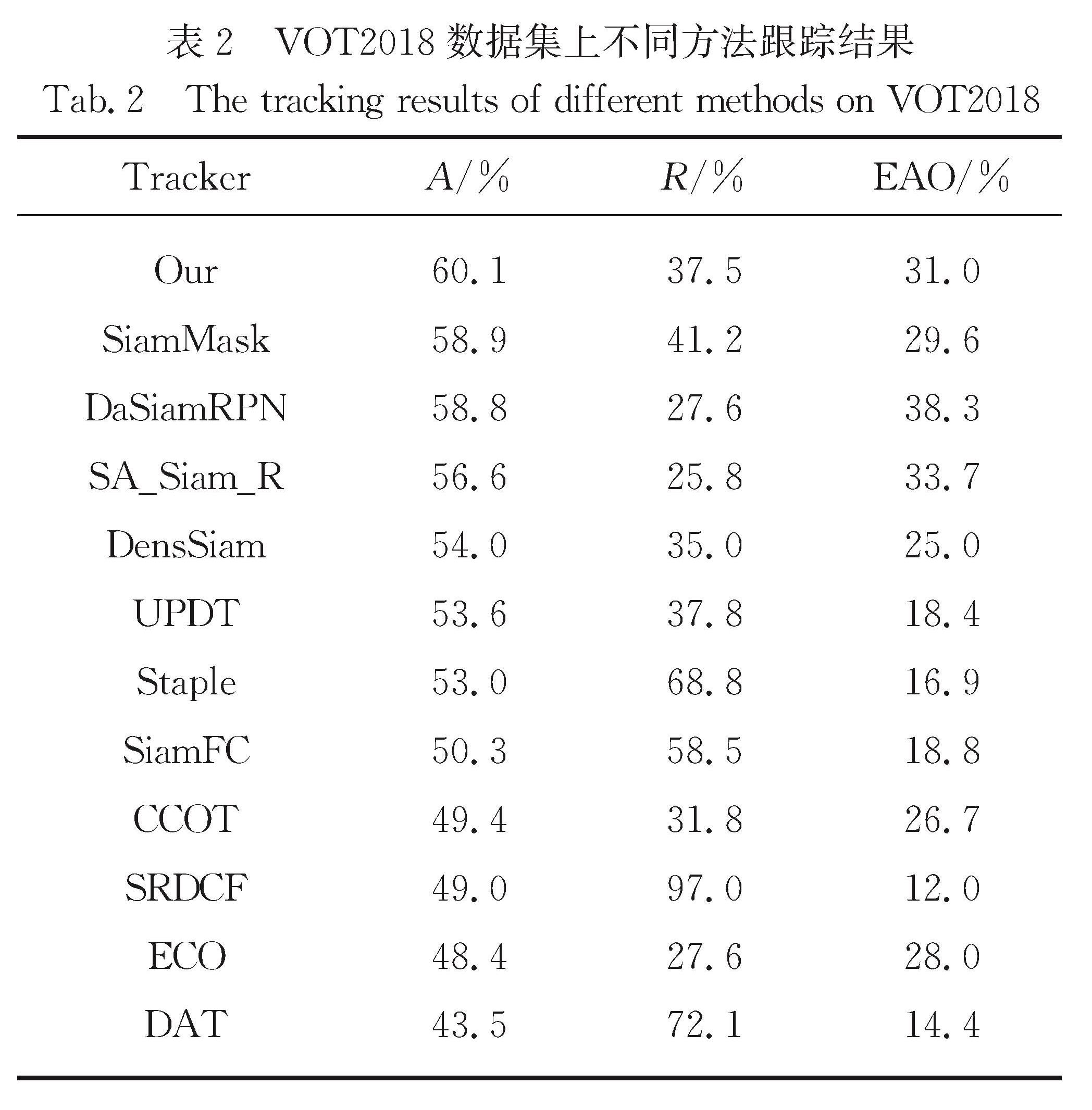
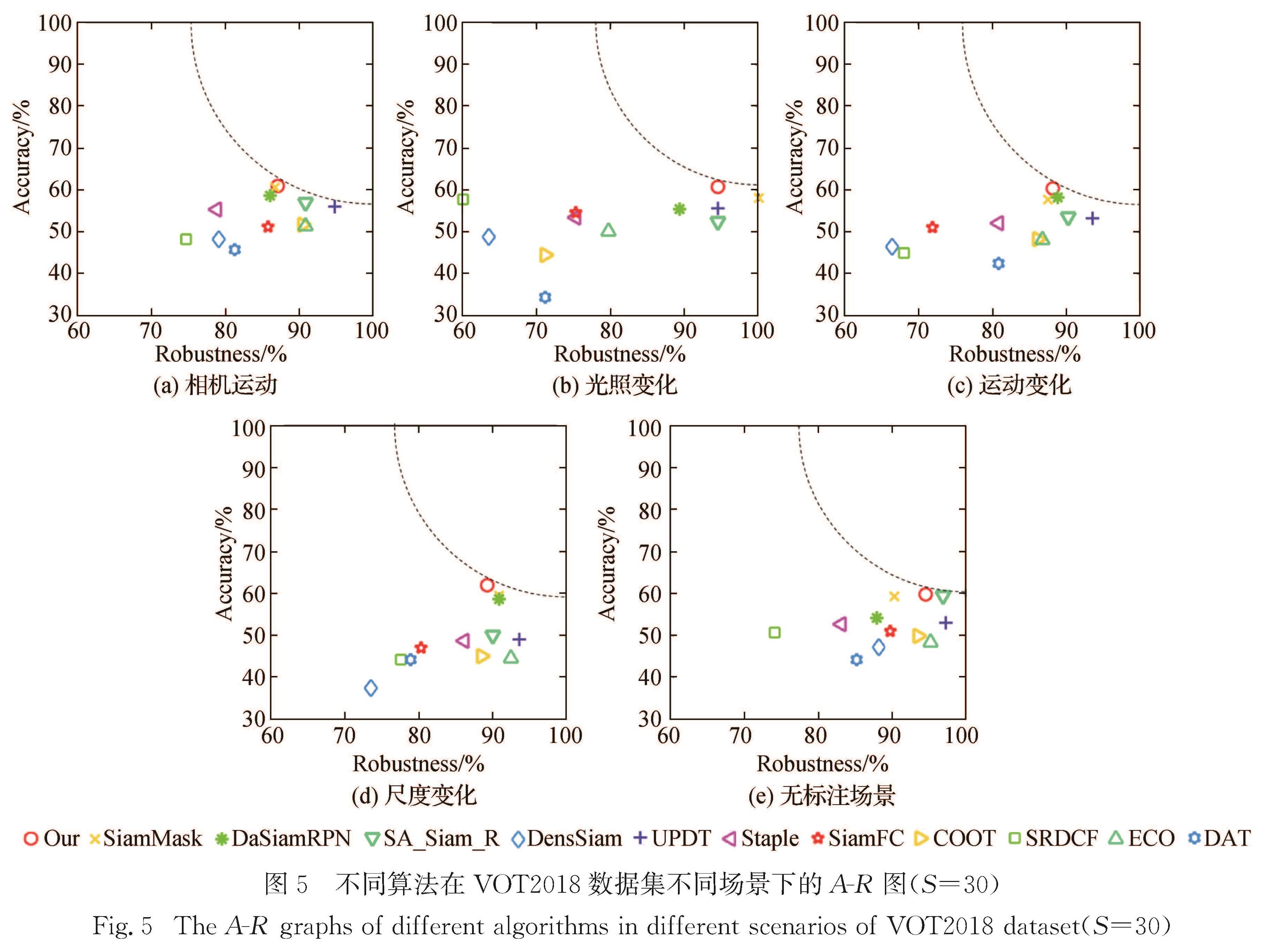
本文算法在VOT2018数据集上与UPDT[28],SA_Siam_R[29],DensSiam[30]等11种算法的对比结果如表2所示,其中本文算法准确率为60.1%,较基准算法SiamMask提升了1.2个百分点,在所有比较算法中结果最优; 鲁棒性为37.5%,较基准算法优化了3.7个百分点; 平均期望覆盖率为31.0%,较基准算法提升了1.4个百分点,在所有对比算法中具有可比性,可看出本文提出的特征融合与注意力机制有利于应对目标跟踪存在的动态不确定性因素.图5为不同算法在VOT2018数据集不同场景下的A-R图,可看出在面对相机运动、运动变化和无标注场景时本文算法相较于基准算法得到较好改善.本文算法从通道和空间维度加强对目标和背景的辨别能力,另外结合轮廓、纹理等浅层特征进一步提升目标跟踪性能,因此与其他跟踪算法相比,本文算法在图5挑战场景下也具有一定可比性.
表2 VOT2018数据集上不同方法跟踪结果
Tab.2 The tracking results of different methods on VOT2018
图5 不同算法在VOT2018数据集不同场景下的A-R图(S=30)
Fig.5 The A-R graphs of different algorithms in different scenarios of VOT2018 dataset(S=30)
为了更清晰对比本文和其他算法,图6可视化了跟踪器在VOT2016数据集上的跟踪结果,分析如下:
1)图6(a)视频序列第26帧,目标与周围环境差异明显,3种算法均能很好跟踪目标; 当后续视频序列出现相似目标时,如第77帧,基准算法跟踪框漂移到相似物上,本文算法由于添加空间注意力机制,通过全局信息辨别相似目标的干扰,实现正确定位; 而第67帧和第78帧,SiamFC算法对目标框的拟合不如本文算法和基准算法.
2)图6(b)视频序列中,目标在人手中被不断旋转,并且背景杂乱,第18帧本文算法最接近真实框; 第79帧SiamFC算法由于目标发生较大变化,同时背景出现相似物体导致目标框发生漂移,跟踪失败; 第116帧由于目标旋转和尺度变化导致基准算法产生漂移,而本文算法可以较好的跟踪目标.
3)在图6(c)视频序列中,SiamFC算法的预测目标框包含较多背景信息,不能很好的拟合真实框; 在第54帧和第88帧目标发生形变,由于本文算法有效结合浅层纹理信息,相比基准算法能更好的跟踪目标.
图6 VOT2016数据集不同场景下不同跟踪算法结果
Fig.6 The results of different tracking algorithms under different scenarios in VOT2016 dataset
4)图6(d)视频序列第2帧中,3种算法均能很好实现目标跟踪; 由于目标运动产生模糊并且背景杂乱,基准和SiamFC算法在第75帧均发生漂移,而本文算法通过加入注意力机制并结合浅层特征,对目标有着更充分的学习能力,可以更好的对背景和目标进行区分.
5)在图6(e)视频序列中,由于相机不断运动,同时伴随目标运动变化、尺度变化和背景光照变化,基准算法和SiamFC算法只识别出目标的一部分,而本文算法能够结合全局信息和多层次特征,实现目标的鲁棒识别.
为了进一步验证注意力机制对目标的辨别能力和对背景信息的抑制作用,图7使用热度图可视化了注意力机制对目标信息提取的作用.在图7(a)和(b)中,面对相似物体干扰和运动变化,注意力机制能对相似背景信息进行有效抑制,聚焦于兴趣目标.在图7(c)序列中,面对目标运动变化、运动模糊、背景杂乱的挑战因素,非注意力对背景区域产生大量响应,而采用注意力机制后模型响应更收敛于兴趣目标区域.
图7 注意力机制作用的目标聚焦结果
Fig.7 The target focus results of attentional mechanisms