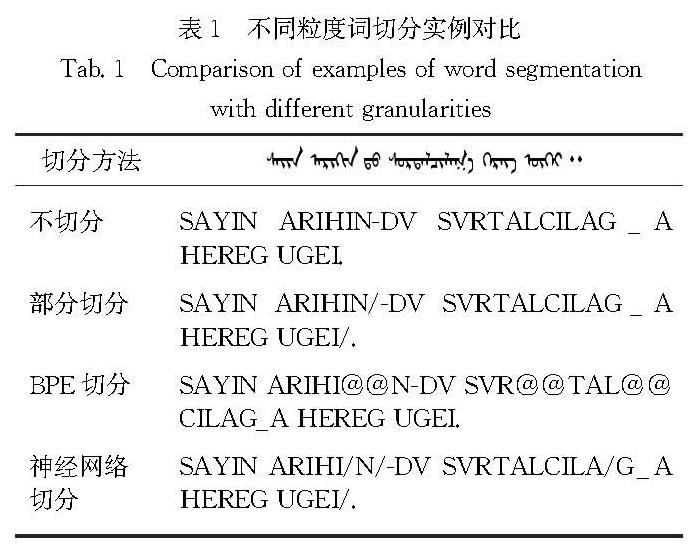
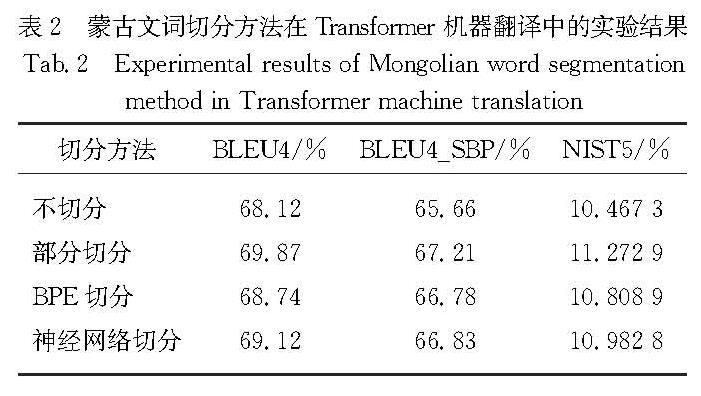
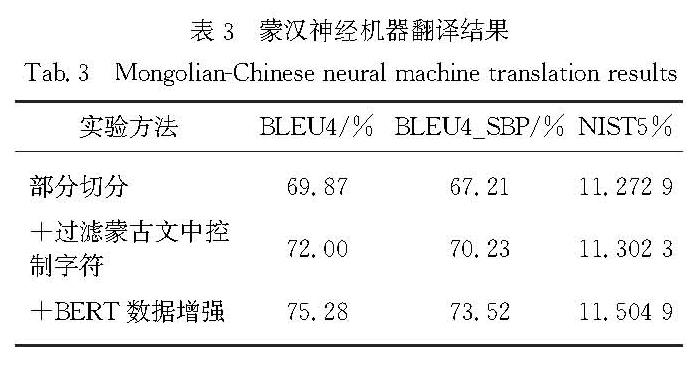
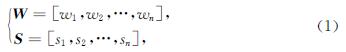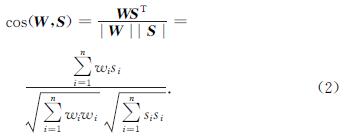蒙汉机器翻译任务属于资源稀缺的少数民族语言翻译任务范畴,这些翻译任务中普遍存在资源匮乏导致的数据稀疏和构词多样性而造成语言特征学习困难的问题.蒙古文形态变化繁杂,而且蒙古文的语序也和汉语语序有所不同,这都成为了蒙汉机器翻译的难题.
自神经机器翻译被提出以来,它就利用大规模的高质量平行语料库来实现端到端的翻译.在数据量充足时,神经机器翻译可以得到良好的翻译结果.但是,在一些资源稀缺的少数民族语言翻译任务中,有时神经机器翻译的性能还不如基于统计的机器翻译.同时,由于训练数据量有限,会导致模型的泛化能力下降.为解决这个问题,一种最直接有效的方法就是通过数据增强方法提高训练数据的多样性,从而提高模型的鲁棒性,避免过拟合.另外,通过改变训练数据,可以降低模型对某些特征或属性的依赖,从而提高模型的泛化能力.
规模庞大的平行语料库是神经机器翻译方法能够获得良好效果的前提.在少数民族机器翻译任务中,平行语料的获取难度是极大的,但单语语料却十分容易获取.合理使用单语语料信息完善翻译模型的翻译能力也成了一种研究课题.其中,数据增强是一个非常重要的研究热点[1].近年来,研究者们尝试使用正向翻译[2]和反向翻译[3]构建伪平行语料库,从而利用相对容易获得的单语数据解决数据资源不足的问题[4].正向翻译的基本思想是训练从源语言到目标语言的翻译模型,将源语言的单语数据翻译成目标语言的句子,与源语言端句子组合成伪双语句对,和真实的双语句对混合作为训练数据用于进一步的训练.反向翻译技术使用目标单语数据来提高模型的翻译质量[5].将目标语言端句子反向翻译后得到源语言端句子,与目标语言端句子组合成伪双语句对,并和真实的双语句对混合作为模型的训练数据,目的是为了采样多样化的训练数据,提升模型的泛化能力.
Sennrich等[6]在机器翻译任务中,最先提出了回译方法来进行数据增强,该方法操作简单、具有很高的实用性.Fadaee等[7]和Sugiyama等[8]使用回译方法,利用对目标端的单语数据进行反向翻译,生成更多的源语言增强版本.Poncelas 等[9]对真实数据、合成数据、混合数据以及回译数据的比例对于翻译效果的影响进行了实证分析,实验数据得出基于采样和加入噪声的束搜索合成数据对翻译效果提升较大.Edunov 等[10]通过实验也同样论证在合成数据中添加噪声数据可以有效提高翻译质量.谷舒豪等[11]在不同领域的语料中利用了数据增强技术,并验证了其方法的有效性.
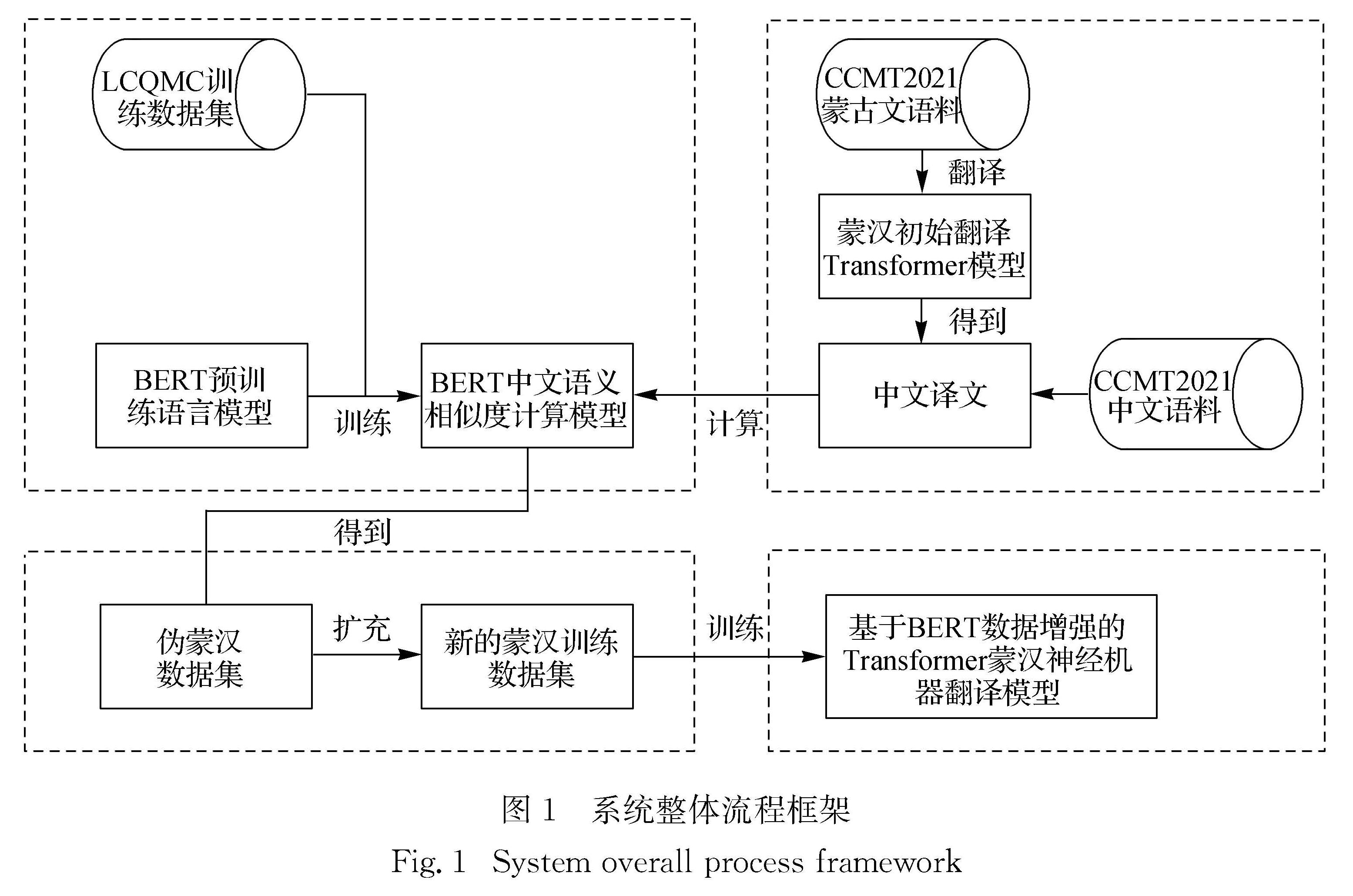
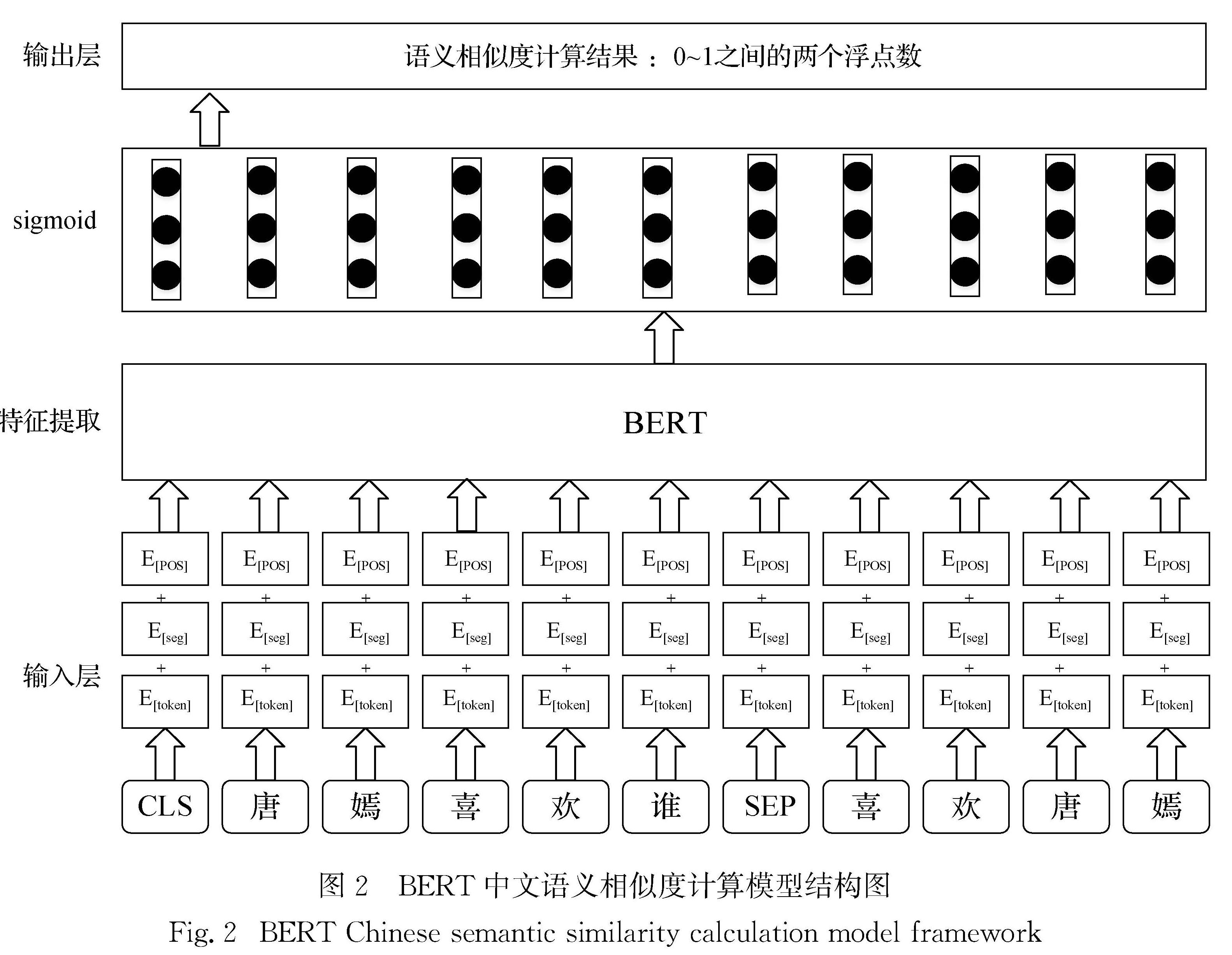
基于回译的方法可以不用修改神经机器翻译模型就能有效地利用单语数据; 但是当平行语料规模较小时,通过回译生成的伪平行语料质量较差,而且大规模的伪数据和较小规模的平行语料混合使得真实的平行语料难以被有效地利用.针对这些问题,本文提出一种针对较小规模平行语料的解决方案.该方法在蒙古文进行词切分的基础上通过BERT数据增强的方法去扩充蒙汉机器翻译训练语料库.该方法利用BERT模型可以通过词的上下文信息去获得更好的词向量表示,从而可以针对多语义词区分表示这一特点,进一步计算句子的语义相似度,提升伪平行语料的质量,有效扩充蒙汉机器翻译训练语料库.