1.2 知识蒸馏与微调
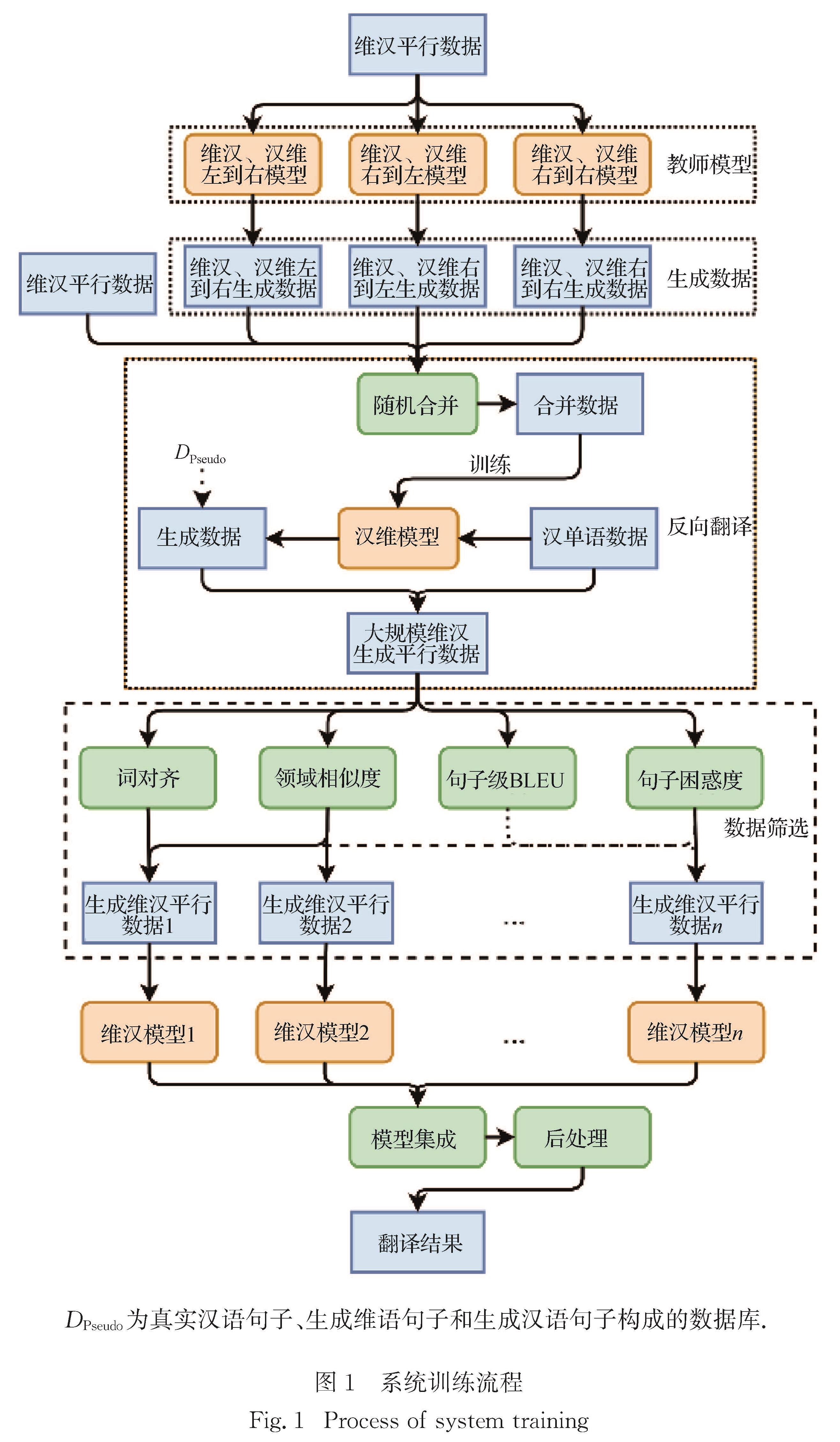
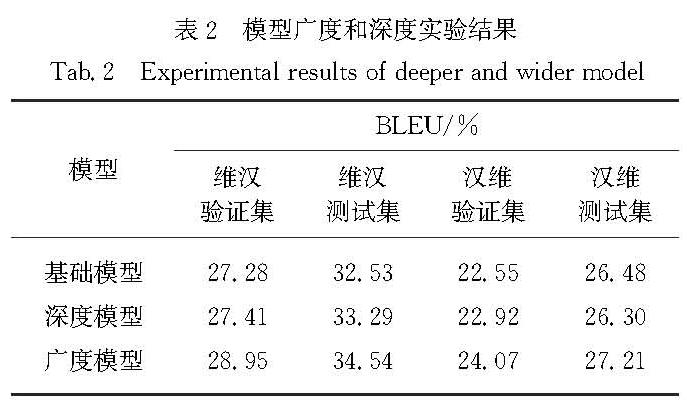
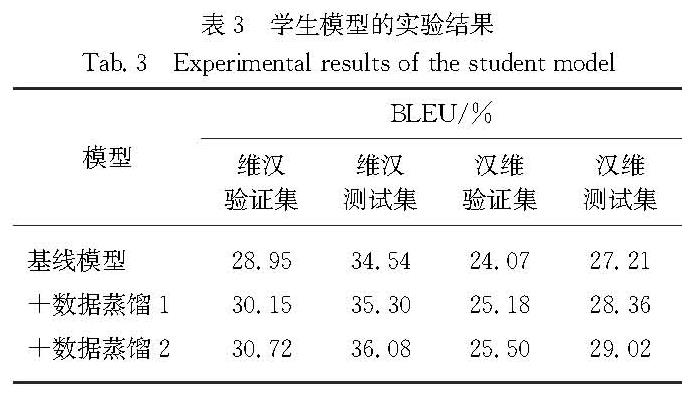
知识蒸馏[16]是一种知识迁移的方法,针对机器翻译任务,本文主要是将一个翻译模型所学的知识通过生成的数据转移到另一个翻译模型里.针对本次评测的特点,采用句子级的知识蒸馏方法,具体的做法如图1中教师模型和数据蒸馏阶段.在训练教师模型阶段,本文针对句子序列是否为逆向,将汉语句子序列和维吾尔语句子序列的方向分为左到右(L2R)、右到左(R2L)、右到右(R2R),并根据这些情况训练了6个教师模型,之后利用这些教师模型对原有的平行语料进行翻译从而得到的6个蒸馏平行语料,将这些蒸馏平行语料与原平行语料进行随机合并,训练得到学生模型,并利用学生模型去翻译汉语单语数据来生成对应的维吾尔语句子.在实验中,由于生成的平行数据的数量远远大于真实数据的数量,为了防止生成的数据分布干扰真实数据,利用原本的平行数据去微调模型,以确保模型生成的结果更遵从原本的平行数据.
1.3 反向翻译与伪造数据选择
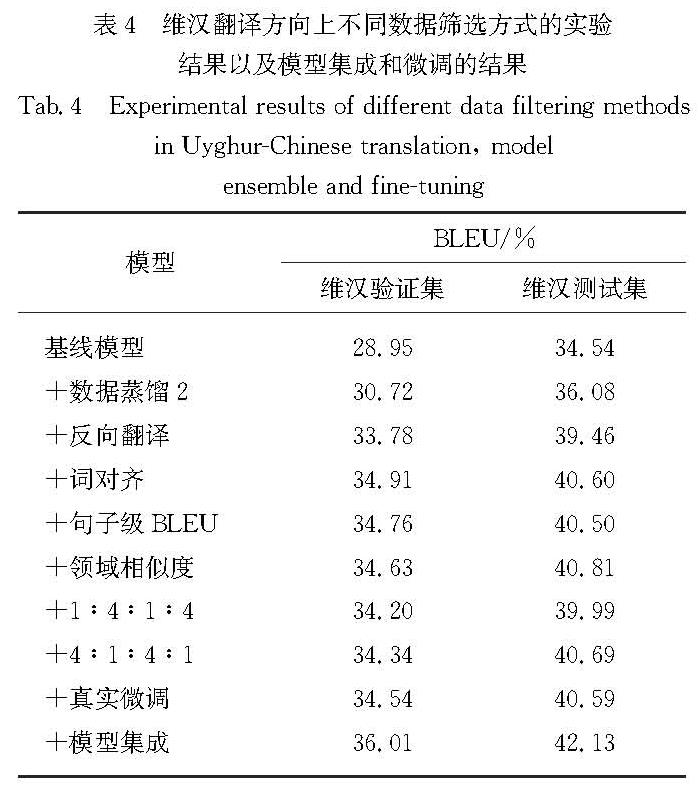
为了充分利用单语数据,本文对测评提供的汉语单语言文本进行反向翻译.该过程主要通过一个汉维方向的翻译模型自动地将汉语单语数据翻译为维语数据,与输入汉语单语数据组成平行数据用于训练模型.具体做法为:本文使用维汉翻译任务提供的维汉平行数据并利用知识蒸馏的方法得到一个性能较好的汉维、维汉翻译模型,并利用汉维和维汉模型循环翻译汉语单语数据从而构建{真实汉语句子、生成维语句子、生成汉语句子}的语料库DPseudo={Y,XPseudo,YPseudo}.为了评价所生成数据的质量,本文利用句子困惑度、Y和YPseudo的相似度、数据的领域相似度、Y和YPseudo的词语对齐值等方式对DPseudo进行评价.
DPseudo为真实汉语句子、生成维语句子和生成汉语句子构成的数据库.
图1 系统训练流程
Fig.1 Process of system training
1)句子困惑度:本文利用平行数据中的维语训练语言模型LM1,反向翻译生成的维语训练语言模型LM2,并使用这两个语言模型对生成的数据计算困惑度Sppl,将利用加权求和的方法得到的结果作为评判句子流畅度的值,其中训练语言模型的工具为KenLM(https:∥github.com/kpu/kenlm).
Sppl=λSppl1+(1-λ)Sppl2,
其中,Sppl1和Sppl2分别为语言模型LM1和LM2计算得到的生成数据的困惑度,λ为权重.
2)句子对齐程度:利用句子词语对齐工具fast_align(https:∥github.com/clab/fast_align)计算生成维汉句对基于对齐率的归一化句子对齐质量Salign.
3)句子级BLEU值:利用sacrebleu(https:∥github.com/mjpost/sacrebleu)计算真实汉语句子Y和生成的汉语句子YPseudo之间的句子级BLEU值SBLEU,并根据所得值进行筛选.
4)领域相似度:本文利用BERT预训练模型[17]来提取生成数据的特征向量,之后将向量输入到两层的全连接网络和softmax函数进行二分类,根据softmax函数输出的值来判断生成数据与训练数据的领域相似度.该过程的公式为:
Xf=BERT(XPseudo),
Ssimi=softmax(tanh(W1Xf+b1)W2+b2),
其中,BERT为预训练模型,Xf为预训练模型提取的特征向量,W1和W2为全连接的参数,b1和b2则为全连接的偏置.本文将验证数据作为领域内数据,通过计算训练数据与验证数据的相似度来筛选领域外数据,相似度是通过BERT提取的特征向量利用余弦相似度来表示.领域相似度的值为该分类器其对汉语单语数据进行分类的概率.
5)数据筛选方法融合:本文希望通过融合筛选后得到的数据更加流畅、语义和领域更加相近,因此对生成句子通过不同的数据筛选方法得到的评分进行差值化.差值化的公式如下:
S=α·Sppl+β·Salign+γ·SBLEU+ρ·Ssimi,
其中,α,β,γ,ρ为权重,且和为1.
本文将筛选后的生成数据与真实数据随机混合后训练新的翻译模型,发现即使经过了筛选,生成数据与真实数据之间仍存在差距.因此,本文使用Caswell等[9]提出的添加标签的方法,让模型学习到所输入数据的来源.
1.4 后处理
在通过模型集成的方式得到数据结果之后,对测试集进行分析,发现某些结果中只存在数字等非汉语字符的句子.因此本文对这种翻译结果进行了处理.具体流程为:1)搜索翻译结果中汉语句子未包含汉语字符,但是对应的维语句子中有维语字符的结果; 2)将这些维语句子中的非维语数据删除,之后将句子重新输入到模型中进行翻译; 3)将非维语的字符替换到翻译的结果中.处理结果前后对比如表1所示,因为出现该问题的句子仅占测试集的0.005,该后处理对于结果的提升并不明显.
表1 后处理举例
Tab.1 Post processing example