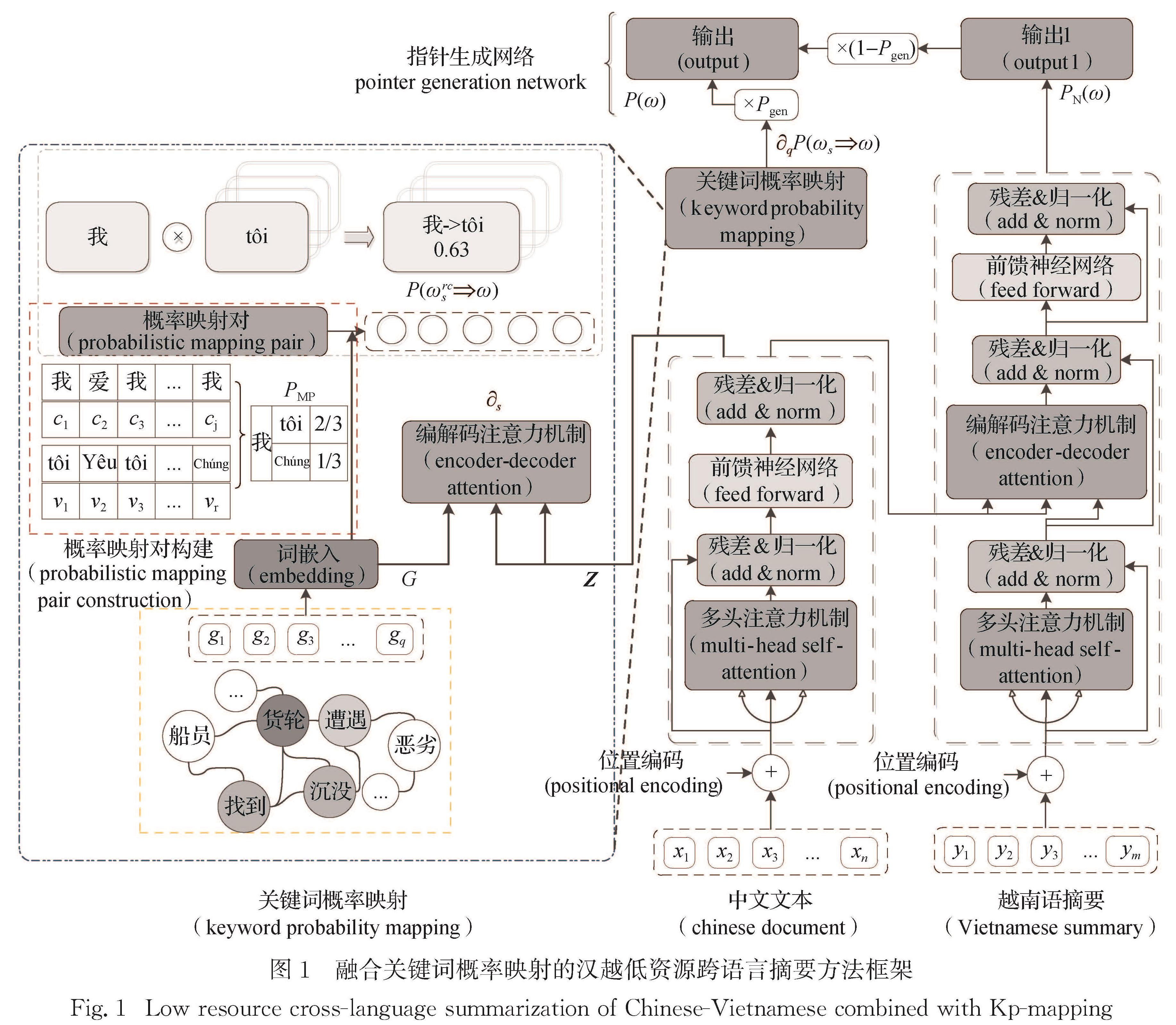
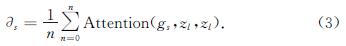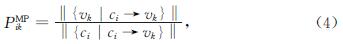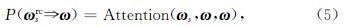2.5.1 实验结果
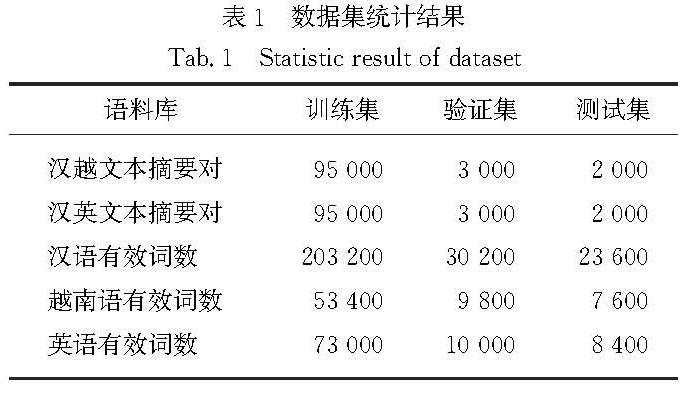
为了证明本文融合关键词概率映射方法在汉越低资源跨语言摘要任务上的优势,将本文模型与现有基准模型在汉越跨语言摘要数据集上进行实验对比,表2给出了本文模型与基准模型在汉越跨语言摘要测试集上的RG-1,RG-2和RG-L的对比结果.
表2 汉越跨语言摘要模型的实验结果对比
Tab.2 The experimental comparison results of the Chinese-Vietnamese cross-language summarization models
由表2可知:TLTran优于TETran,说明先翻译后摘要的方法更容易受MT性能的影响,发生错误传播.C-Vcls模型与传统的TLTran、TETran模型相比,在RG-1,RG-2和RG-L上分别取得了1.10,0.07,1.51和6.03,2.30,4.71个百分点的提升,这也说明了不仅关键词概率映射的策略可以有效缓解越南语MT性能不佳引起的摘要质量差的问题,通过获得源文关键词的联合表征还可以获得更好的上下文表示,使生成的摘要更精准.另外,C-Vcls模型与端到端的NCLS模型相比,在RG-1,RG-2和RG-L上取得了3.85,0.89,2.83个百分点的提升,相较于需要大规模语料的端到端的NCLS模型,本文构建源文关键词的联合表征并融入关键词的概率映射,通过先验知识增强模型的跨语言表征能力,降低了模型对语料规模的要求,从而取得了更优的性能.因此,通过以上分析,可以得出明确结论:本文提出的关键词概率映射方法是一种有效的方法,可以有效提高端到端模型的性能.
2.5.2 融合关键词概率映射方法的有效性分析
在2.5.1节中,融合关键词概率映射方法能有效提高端到端模型的性能.为了进一步证明本文融合关键词概率映射模块在汉越低资源跨语言摘要任务上的合理性,本文设置了多组实验进行验证.
1)关键词融入的有效性
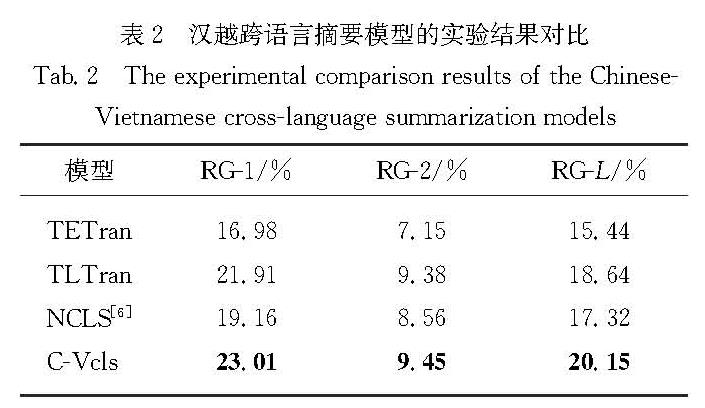
表3中给出了关键词个数q不同时,C-Vcls模型在汉越跨语言摘要测试集上的RG-1,RG-2,RG-L的比对结果.
表3 关键词个数对C-Vcls模型的影响
Tab.3 The influence of the number of keywords on the C-Vcls model
分析表3可知,q=5时,模型取得了更优的性能.随着q从0增加到5,C-Vcls模型在汉越跨语言摘要测试集上指标RG-1、RG-2和RG-L不断增加.与q=0相比,q=5时在指标RG-1、RG-2和RG-L上分别获得了3.85、0.89、2.83个百分点的性能提升.原因可能是随着关键词个数的增多,获得的文本关键信息越多,对摘要的指导性越强,获得的摘要越可靠.综上,表明了关键词等先验知识对摘要模型的指导可以有效提升低资源摘要模型的性能.
2)概率映射策略的有效性
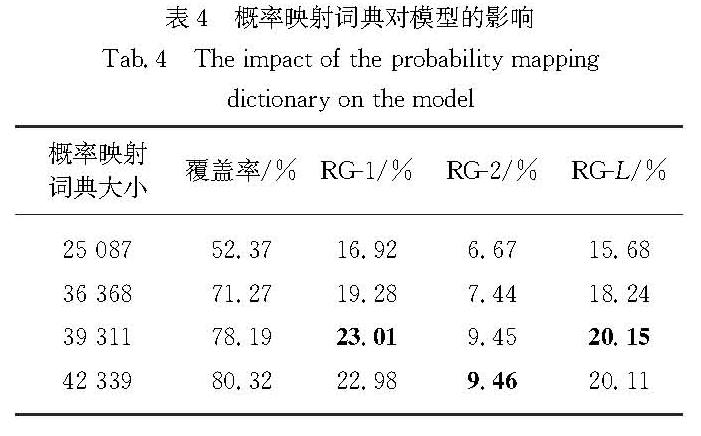
为验证概率映射策略的有效性,本文在概率映射词典的大小上进行相关实验.根据词频设置概率映射词典大小为25 087,36 368,39 311,42 399,表4中给出了本文模型在汉越跨语言摘要数据集上的RG-1、RG-2、RG-L的比对结果,其中覆盖率为概率映射词典相对于关键词词数的占比(此处由TextRank得到的关键词未进行去重,故覆盖率的分母不一样).
表4 概率映射词典对模型的影响
Tab.4 The impact of the probability mapping dictionary on the model
分析表4可知,概率映射词典大小为39 311是性能最好的,在指标RG-1、RG-2和RG-L上,相较概率映射词典大小为25 087,36 368,42 339时分别有6.09,2.27,4.46,3.73,2.01,1.91; 0.03,-0.01,0.04个百分点的提升.概率映射词典大小为25 087时的汉越跨语言摘要效果较差,主要原因可能是覆盖率仅有52.37%,此时词典的噪声较大,覆盖率较低,在进行映射时不能对关键词进行有效映射,导致部分关键词不起作用,相对于其它模型的结果(表2),甚至会降低摘要的效果; 但是在概率映射词典为39 311和42 339时,摘要效果相对于其它模型的结果(表2),仍有提升,但是两者相差不大,这是由于最终生成摘要的单词分布由概率映射词典、翻译概率、神经网络模型生成单词的分布共同决定,可能产生的不确定性较大.综上,说明了概率映射词典这一策略在汉越跨语言摘要任务上的有效性,但是概率映射词典对于关键词的覆盖率在一定程度上影响了模型的性能.
3)概率映射以及指针网络对于C-Vcls模型的有效性
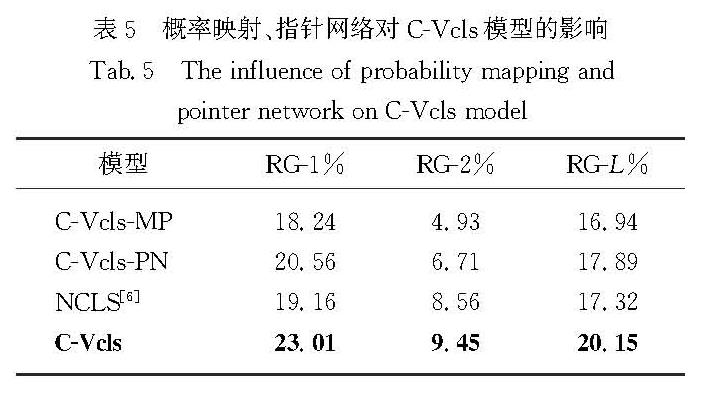
为验证本文所结合的概率映射以及指针网络策略的作用,本文在汉越低资源跨语言摘要数据集上进行相关实验.其中,C-Vcls-MP模型是在C-Vcls模型的基础上减少概率映射模块,C-Vcls-PN模型是在C-Vcls模型的基础上减少指针网络模块而选择直接拼接Pgen∑ssp(wsw)与(1-Pgen)pN(w)的方式进行关键词的融合.
分析表5可知,C-Vcls模型取得了更好的效果.C-Vcls模型较C-Vcls-MP模型在指标RG-1、RG-2和RG-L上取得了4.77,4.52和3.21个百分点的提升,该结果表明当关键词不进行概率映射时,摘要结果下降最为严重且摘要性能低于NCLS模型,可能是由于关键词不进行映射时,会给模型引入更多的噪声,说明关键词概率映射模块在模型中起着至关重要的作用,能够建模关键词映射到目标语言作为先验知识指导跨语言摘要的生成.而C-Vcls-PN模型相对于C-Vcls模型,在指标RG-1、RG-2和RG-L上的性能分别下降了2.45,2.74和2.26个百分点; 但是相较NCLS模型,RG-L指标上仍然取得了0.57个百分点的增幅,这也说明,尽管融合的方式不同,但是融入关键词概率映射信息到端到端的模型中确实对模型性能的提升是有帮助的,而且指针网络的融合方式优于直接拼接的融合方式.综合以上分析,本文所提概率映射以及指针网络进行融合的方式对模型的性能提升是有益的.
表5 概率映射、指针网络对C-Vcls模型的影响
Tab.5 The influence of probability mapping and pointer network on C-Vcls model
4)C-Vcls模型与基准模型在汉英跨语言摘要测试集上的对比
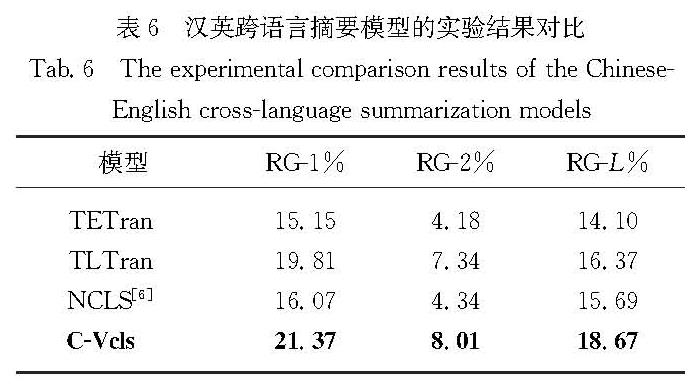
为了验证本文所提模型的泛化性,本文在汉英跨语言摘要数据集上进行实验.表6给出了本文模型与基准模型在汉英跨语言摘要数据集上的RG-1、RG-2和RG-L的比对结果.
表6 汉英跨语言摘要模型的实验结果对比
Tab.6 The experimental comparison results of the Chinese-English cross-language summarization models
分析表6可知,本文模型的指标均优于基准模型.C-Vcls模型较TLTran模型和TETran模型在指标RG-1、RG-2、RG-L上分别有1.56,0.67,2.30和6.22,3.83,4.57个百分点的提升; 较NCLS模型有5.30,3.67,2.98个百分点的提升.根据表2和6可以看出,同样数量级的数据在同样的基准模型上,不同的数据集取得的结果有所差异,且在汉英跨语言摘要数据集上的实验结果低于汉越跨语言摘要数据集.主要原因是因为虽然越南语和英文构造的词典均为1万,但根据越南语和英文文本构造特点及本文数据集的有效词数来看,越南语词典对于测试集文本的覆盖率高于英文词典对于测试集文本的覆盖率,即汉越跨语言摘要的实验结果没有大量未登录词<unk>的出现,进而提高了摘要的准确性.但是,从实验结果依然可以看出,本文提出的引入具有引导性的关键词概率映射的方法对于汉英跨语言摘要任务同样有效,也证明了本文所提模型的泛化性.
2.6 实例分析
为了进一步验证算法的有效性,本文列举了不同模型的摘要结果.具体如表7所示,源语言文本与标准摘要都来自汉越跨语言摘要数据集.本文列举出了所有基准模型的输出结果作为对比,为了便于理解,本文给出了对应汉语的翻译结果.
分析表7可知,源语言文本主要讲述19名前往张家口的驴友被困海坨山,其中15名驴友失去联系的事实.由于模型限制,传统模型TETran模型表达出了19名来自河北石家庄的朋友,但是并没有表述出15名前往张家口的朋友在河北失去联系的关键信息; TLTran模型表现相对较好,但是仍然没有表输出“张家口”的关键事实.而对于端到端的C-Vcls模型和NCLS模型均能表达出“15名驴友”的主要信息,但是NCLS模型,并没有体现出其“失去联系”的关键信息,且内容过于冗杂,而本文提出的融合关键词概率映射的策略,获取源文中的关键词“北京”“失去”“联系”等映射至目标语言,通过有关键词概率映射信息等具有引导性信息的融入增强了模型的跨语言表征能力,提高了摘要的信息覆盖度以及事实性,生成质量更高的文本摘要.