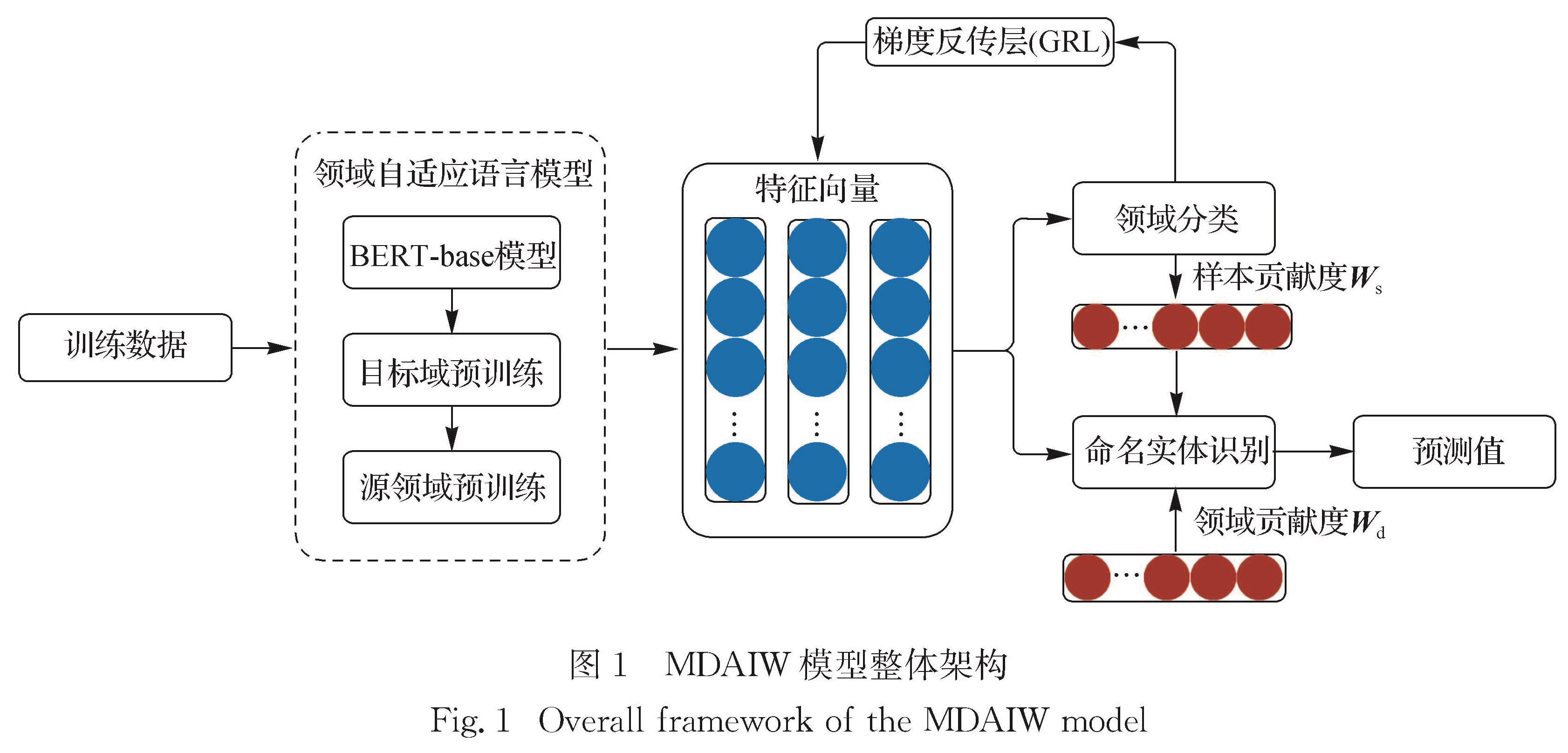
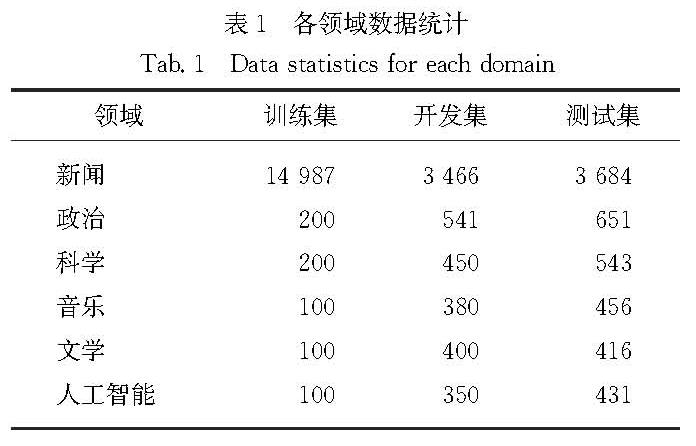
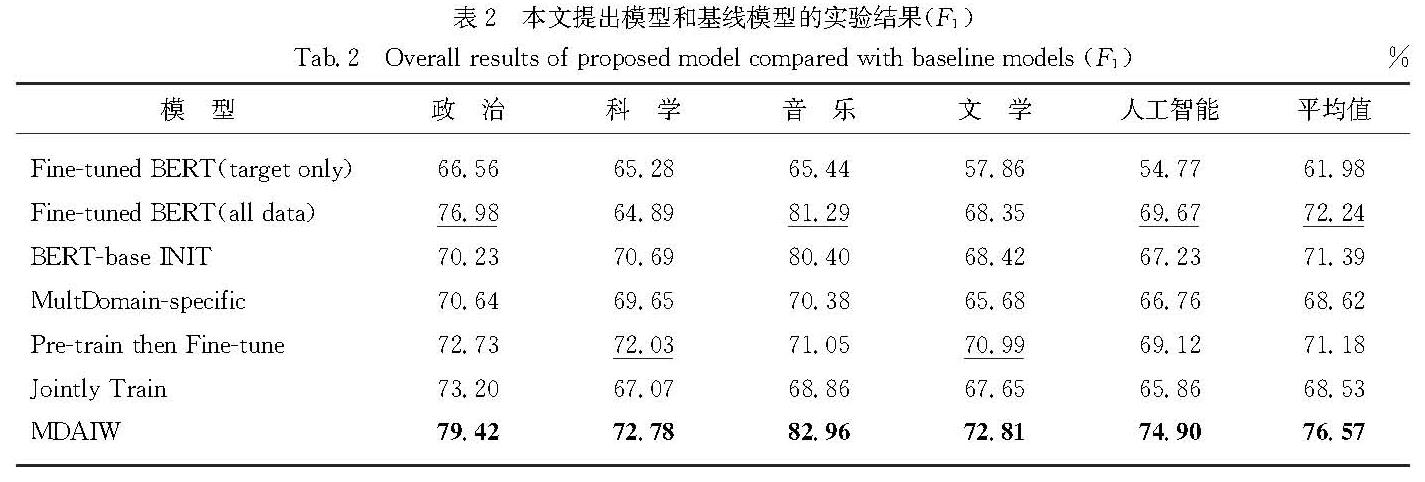
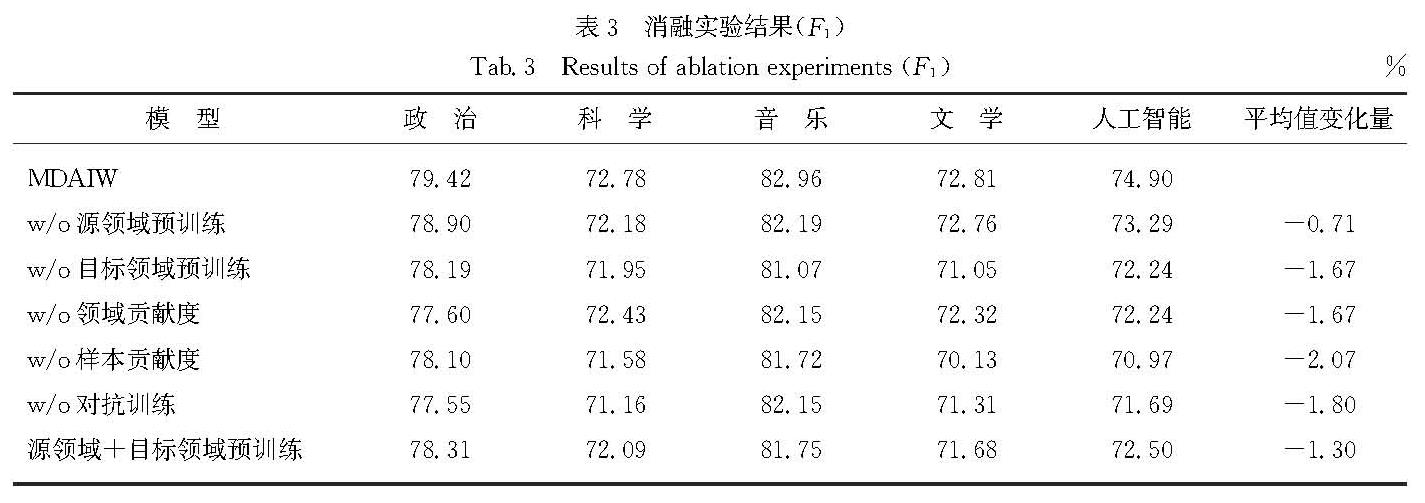
考虑到不同的源领域以及领域内样本对目标领域的重要程度可能存在差别,设计了一种融合贡献度加权的迁移方法,以此来缓解源领域和目标领域间的领域偏移问题,同时利用对抗训练策略进一步增强模型性能.融合多源领域贡献度加权的迁移模型如图1所示,输入语料首先通过领域自适应语言模型获取特征向量,语言模型应用1.1节中经过领域自适应后的BERT模型,训练过程包含NER和领域分类两个训练任务,在NER任务中应用领域层级和样本层级的贡献度加权,帮助模型更好地进行多源领域迁移,领域分类任务通过GRL与NER任务连接进行共同训练.
在1.2.1节中,详细介绍了领域层级和样本层级贡献度的建模计算方法,以及如何将加权应用于NER损失函数中.在1.2.2节中介绍了对抗训练策略.
1.2.1 贡献度加权
贡献度加权的目标是量化不同领域和领域内样本对目标领域的重要程度,并将计算后得到的贡献度参数引入到NER模型中,以缓解在采用多源领域数据进行训练时,不同的领域分布导致的负迁移问题.本文中分别设计了领域层级和样本层级的贡献度参数建模方法.
1)领域层级贡献度建模 领域层级贡献度的建模目标是计算不同源领域对目标领域的贡献程度.基于Aharoni 等[10]在研究中得出的预训练语言模型获取的向量表示能够捕捉到领域信息这一结论,本文中提出通过两阶段自适应预训练后的语言模型获取特征向量表示,利用两个领域的向量表示来计算领域距离,并将其作为这两个领域相似性的量化表示.在具体实现过程中,首先通过BERT-base模型得到句子级别的向量表示,然后通过计算某一领域内句子向量的平均值作为该领域的向量表示,并计算两个领域向量的余弦相似度来表征领域距离.领域的向量表示qSi和领域距离dSa,b的计算方法为:
qSi=1/(mi)∑mij=1BERT(xij),(1)
dSa,b=cos<qSa,qSb>.(2)
2)样本层级贡献度建模 样本层级贡献度的建模目标是计算领域内的不同样本对目标领域的贡献程度.本文中设计了一个领域分类任务来实现这一目标.具体来说,通过一个领域二分类器预测样本是否属于目标领域.二分类器的输出为某一样本被预测为目标领域样本的概率值,如果某一源领域样本被预测为目标领域样本的概率值较低,则代表其对目标领域的重要程度比较低,相反,如果概率值较高,则意味着样本对目标领域的重要程度较高.因此,通过领域分类器即可得到源领域样本对于目标领域的贡献度权重.该过程可表示为:
[PT,1-PT]=softmax(classifier(xj)),(3)
其中,PT表示被预测为目标领域样本的概率,即为样本层级贡献度参数.
3)贡献度加权 在得到贡献度权重后,将其引入到NER模型的损失函数中.训练数据由少量的目标领域数据和多个源领域数据集构成.NER的损失函数可被分为源领域损失LS和目标领域损失LT两部分,将贡献度权重作为LS的权重因子,每个样本的权重w由领域贡献度权重dSa,b和样本贡献度权重PT点乘得出,可表示为式(4).
w=dSa,b·PT.(4)
贡献度加权的目标是体现源领域样本对于目标领域的重要程度,根据贡献度的高低来分配权重.因此,需要对权重进行归一化,归一化权重为
wnorm=(exp w)/(∑iexpwi),(5)
其中,wi为每个样本的贡献度权重.
对多个源领域内的样本加权后,MDAIW模型的整体损失函数可表示为:
LNER=-1/n∑nj=1yTjlgy ^ Tj-
1/m∑mj=1wnormjySjlgy ^ Sj.(6)
其中m为k个源领域的总样本数.
1.2.2 对抗训练
通过贡献度加权可以提高模型对不同领域和样本的鉴别能力,在此基础上,结合对抗训练可以进一步提高模型对多个不同的领域间通用知识的获取能力.受到GRL的启发[11],本研究在模型中加入GRL层来实现对抗训练.其实现方法是在反向传播的过程中反转梯度方向,使GRL前向和后向的网络训练目标相反,以此来实现对抗的效果.具体来说,特征向量输入模型后分别进行领域分类任务和NER任务,对两个任务的损失函数求和后进行梯度回传实现联合训练,通过训练对BERT分类器token([CLS])中的隐层状态hCLS进行参数优化.
加入对抗训练后,应用隐层向量hCLS获取领域分类器的输出值的过程可表示为:
[P'T,1-P'T]=softmax(WdhCLS+b).(7)
领域分类器的损失函数可以表示为:
LTC=-1/(m+n)∑m+nj=1djlgd^j.(8)
联合训练的损失函数可以表示为:
Ltotal=LNER-LTC.(9)