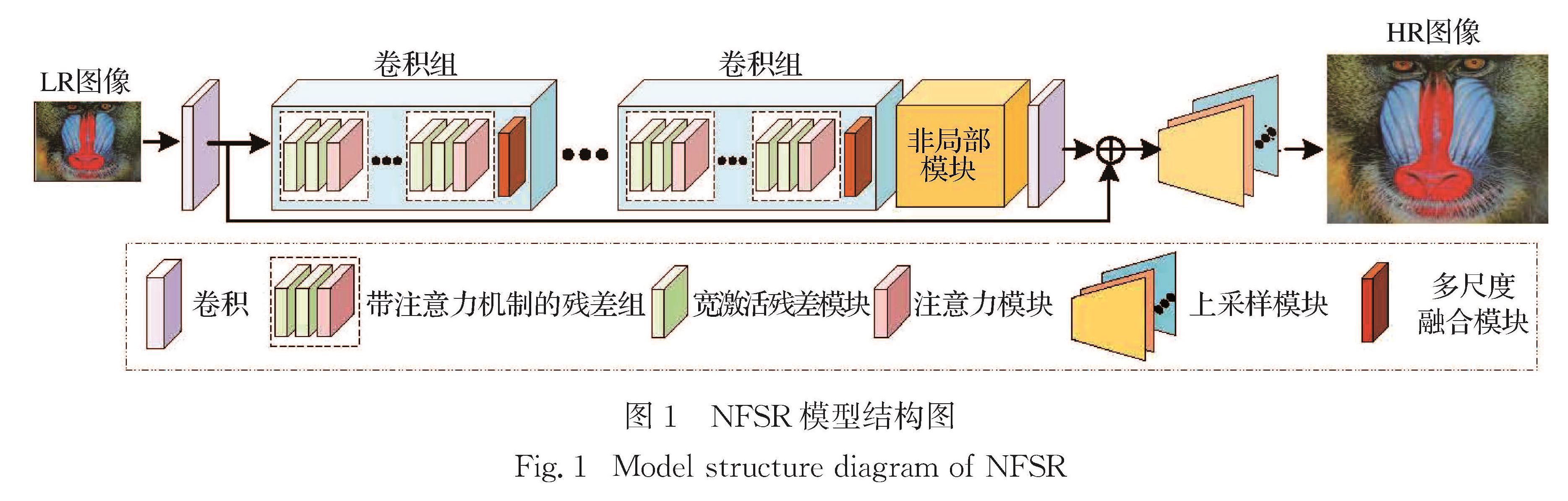
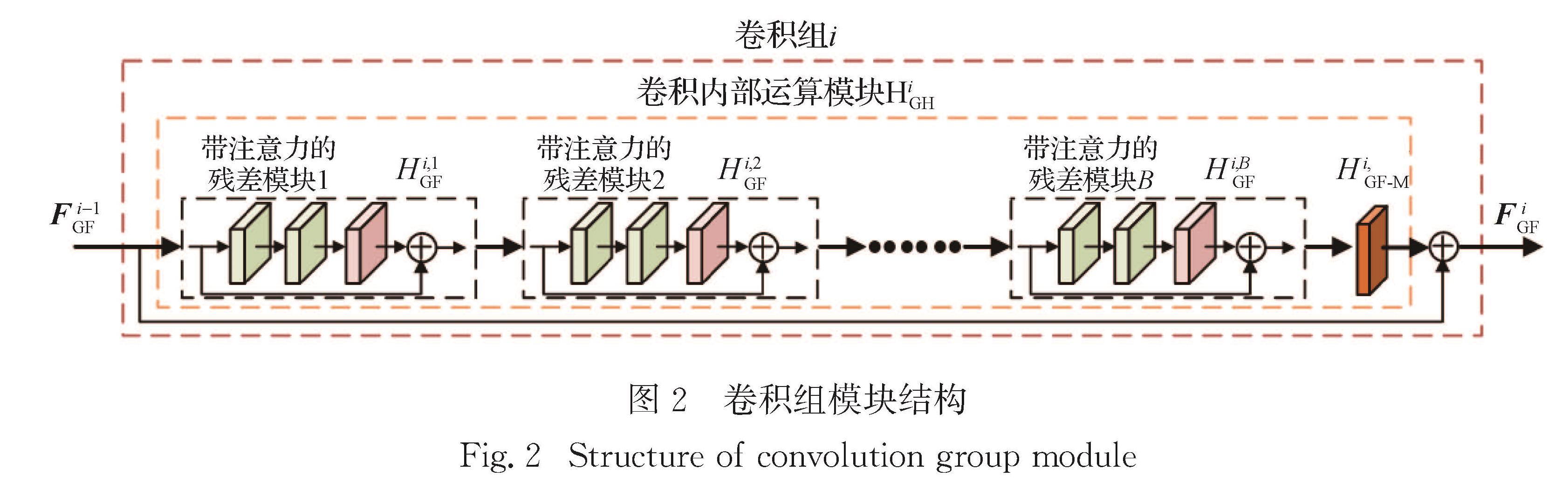
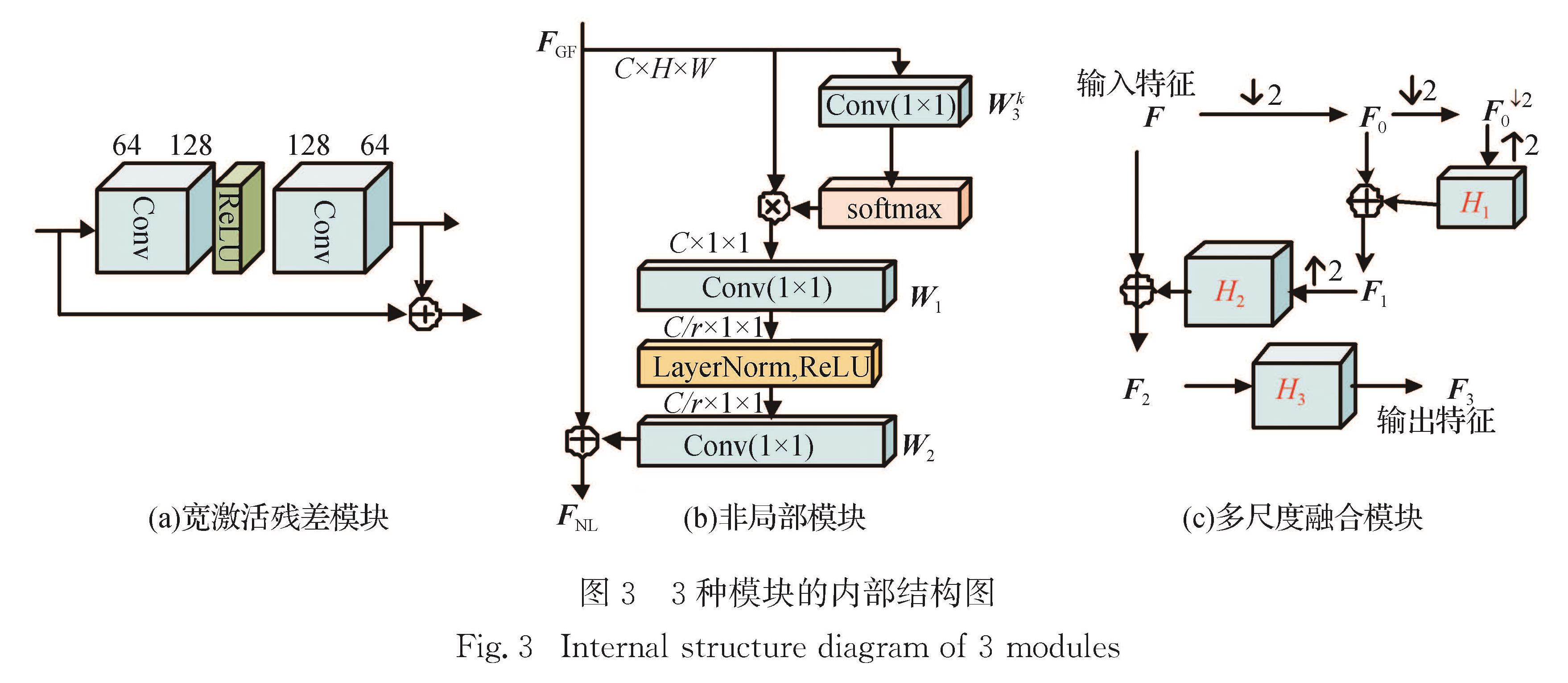
现有的深度超分辨率重建模型, 用堆叠多个相同模块的方式获取具有更高精度的重建结果, 但未能充分考虑各层特征间的上下文关联信息.提出一种基于非局部多尺度融合的图像超分辨率重建模型.该模型采用3种模块:非局部模块、多尺度融合模块和宽激活残差模块.其中, 非局部模块用于获取图像的全局特征, 关注目标的核心区域; 多尺度融合模块用于融合通道特征, 增强特征在空间的上下文关联; 宽激活残差模块替代普通残差模块, 通过扩充激活层前的卷积层输出特征来提升模型的重建精度.在5个基准数据集上的实验结果表明, 该模型取得了较高的重建精度.在图像分割与目标检测任务上, 与几种深度超分辨率模型相比, 该模型也取得了较好的分割和检测精度.
Objectives: As the main source of visual information, images provide the convenience for human communications. For the purpose of measuring the quality of an image, the metric of image resolution is widely used. Cleary, low-resolution images caused by image degradation factors cannot be favorably used for image dissemination, utilization and processing. Realizing the urgent need and using the existing software technology, we attempt to restore clean and clear high-resolution images with rich details. In this study, we use the deep-learning technology to explore how to improve the accuracy of image super-resolution reconstruction.
Methods : The deep convolutional neural network structure is adopted to obtain the image super-resolution model based on non-local multi-scale fusion (NFSR). The data processing flow of NFSR model includes input LR image, shallow feature extraction, multiple convolution group feature extraction, non-local module, convolution, high-level feature and shallow feature addition, and up-sampling module, finally as well as the output HR image. Each convolution group module contains several wide activation residual modules and a multi-scale fusion module. The latter is placed in the last layer to fuse features of the convolution group. The non-local module is used to obtain the global context of the input image feature.
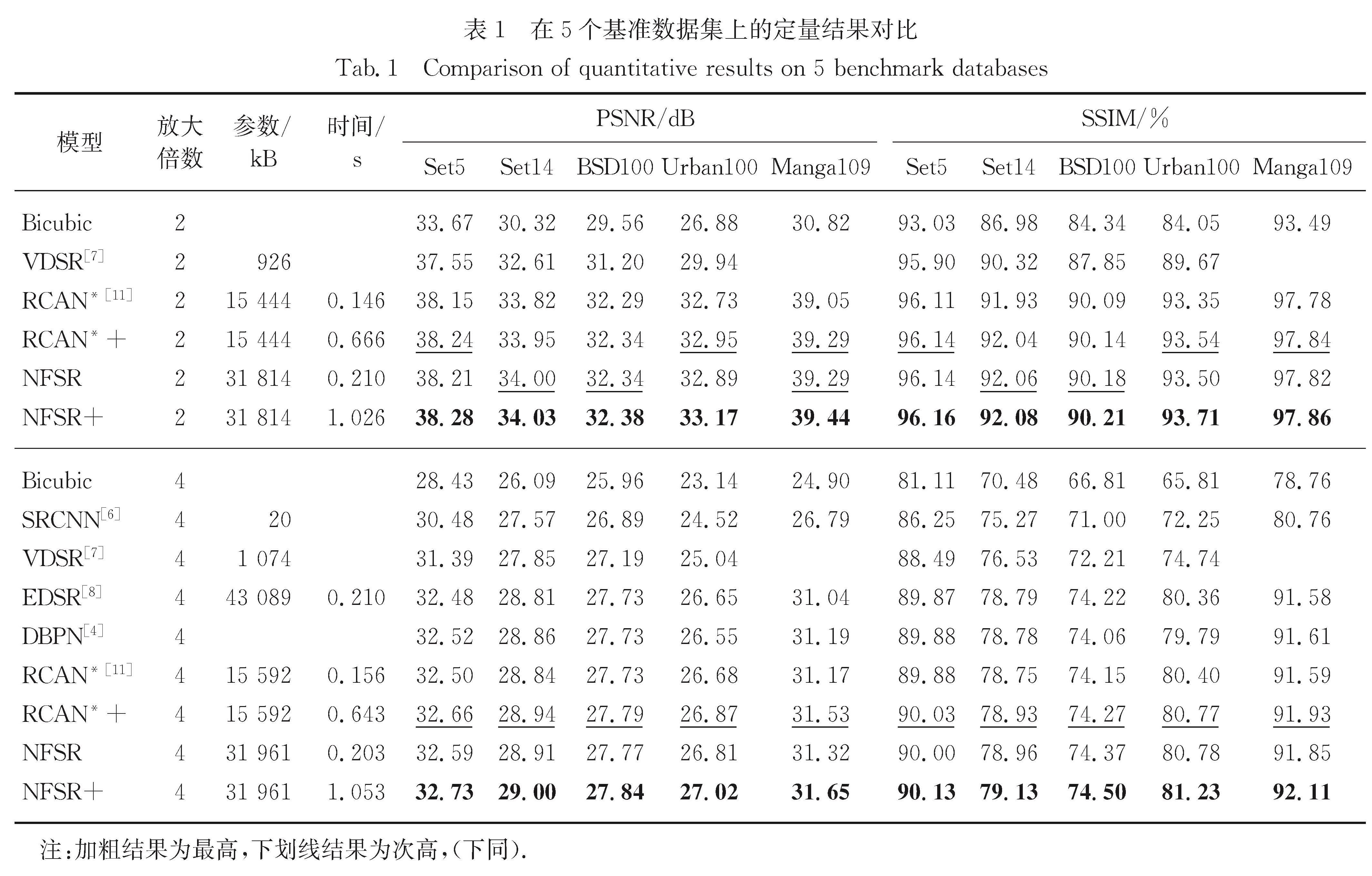
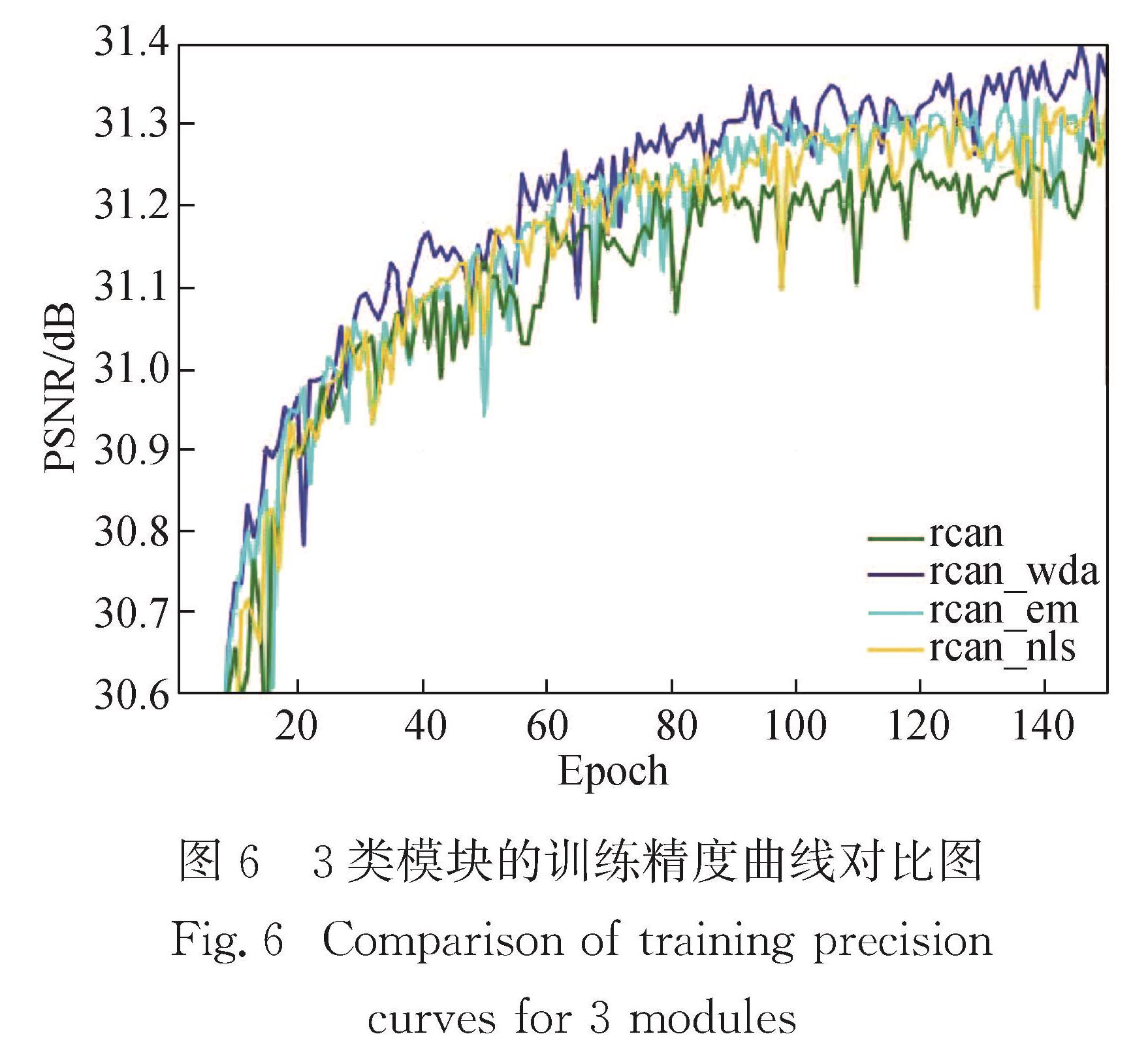
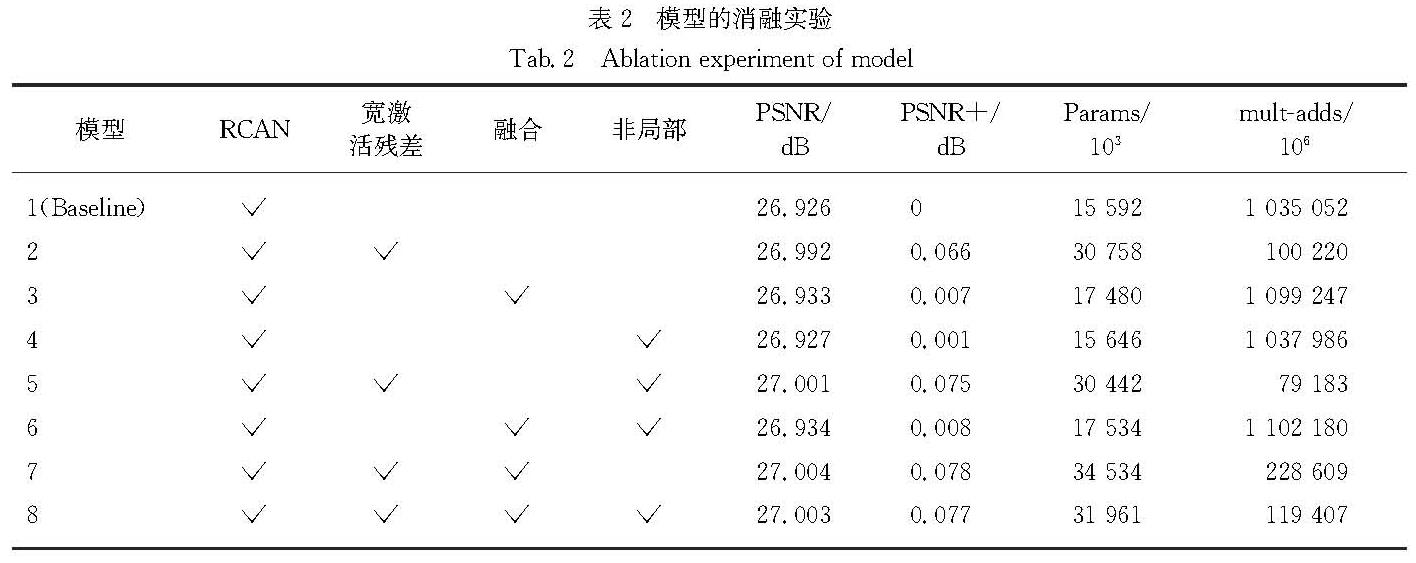
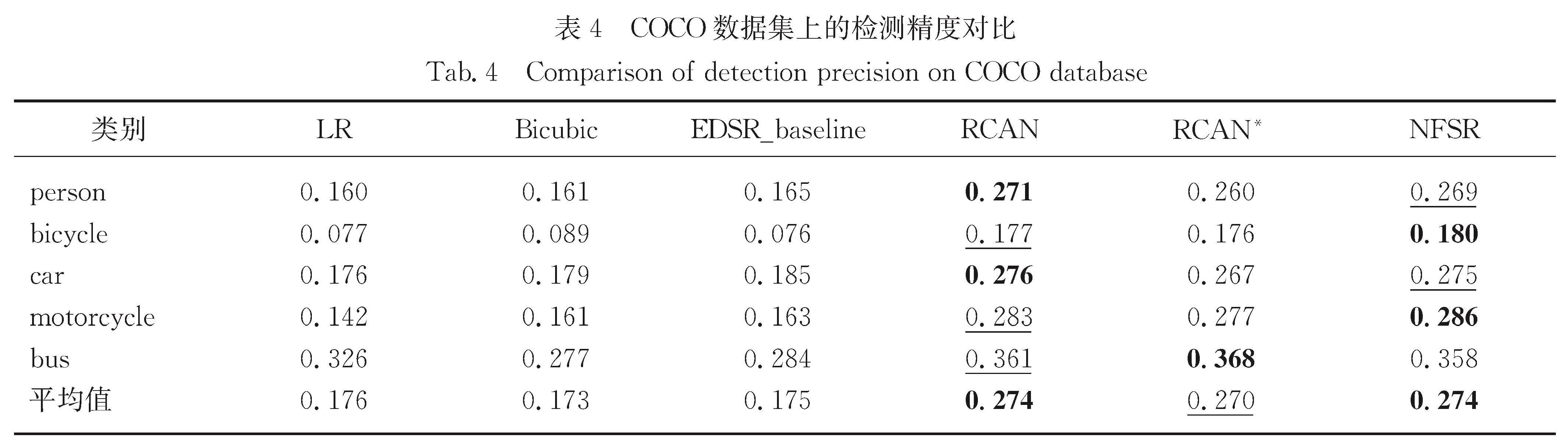
Results : In the external dataset for training image super-resolution reconstruction, we use the bi-cubic interpolation low-resolution and high-resolution image pairs of DIV2K 2017, namely a total of 900 images, including 800 training sets and 100 validation sets. In the test set, 5 benchmark test sets are used. When the model is reconstructed in 4 times magnification, the input size of the LR image and the size of the HR image become 48×48 and 192×192. When the model is reconstructed and enlarged by 2 times, the size of the input LR image becomes 96×96, and the size of the HR image remains unchanged. The code is implemented with the PyTorch deep learning framework with MATLAB R2015b as the evaluation software. During the training, the total number of complete iterations of the NFSR model training reaches 500 times; the PSNR (peak signal-to-noise ratio) is used as the evaluation index, and the model with the highest PSNR value is saved as the best model. The enhancement method of NFSR (it is obtained by averaging the reconstruction results in 8 flip directions) is named NFSR+. The research includes (1) Exploring the impact of three types of modules on image reconstruction performance. The NFSR model uses a variety of modules. Three modules are special: non-local, multi-scale fusion and wide activation residual module. Among them, the non-local module is used to obtain global features of the core area of the target image. The multi-scale module is used to fuse channel features and enhance the contextual correlation of features in space. The wide activation residual module activates through expansion features before the rectified linear unit of the ordinary residual module, and is used to improve the reconstruction accuracy of the model. Ablation experiments demonstrate that they can improve the reconstruction accuracy to a certain extent. (2) Evaluating image reconstruction performance of the entire model NFSR. Quantitative results at 2x and 4x magnification show that NFSR+ achieves the highest accuracy (PSNR value) on the 5 benchmarks compared to several depth image reconstruction models. Corresponding qualitative results of image reconstruction show that the NFSR model exerts a good subjective effect on the reconstruction of the image structure, and the recognizability of the image is higher. (3) Applying to image segmentation and object detection tasks. NFSR can also maintain good segmentation accuracy and detection accuracy.
Conclusions: By learning from others' merits, the deep network model NFSR achieves higher image reconstruction accuracies. Through this network, it can be found that combining some network modules in other fields of image processing, such as non-local modules, can also improve the reconstruction accuracy when this combination is applied to the field of image reconstruction. At the same time, this phenomenon further confirms the excellent performance of the non-local module. The image super-resolution reconstruction task belongs to the low-level computer vision task and can serve as the middle and high-level vision tasks. In turn, excellent modules in mid- and high-level vision tasks can also be applied to image super-resolution reconstruction to improve its performance. This treatment shows that technologies in various fields can be inter-related for mutual learning and mutual promotion.
Methods : The deep convolutional neural network structure is adopted to obtain the image super-resolution model based on non-local multi-scale fusion (NFSR). The data processing flow of NFSR model includes input LR image, shallow feature extraction, multiple convolution group feature extraction, non-local module, convolution, high-level feature and shallow feature addition, and up-sampling module, finally as well as the output HR image. Each convolution group module contains several wide activation residual modules and a multi-scale fusion module. The latter is placed in the last layer to fuse features of the convolution group. The non-local module is used to obtain the global context of the input image feature.
Results : In the external dataset for training image super-resolution reconstruction, we use the bi-cubic interpolation low-resolution and high-resolution image pairs of DIV2K 2017, namely a total of 900 images, including 800 training sets and 100 validation sets. In the test set, 5 benchmark test sets are used. When the model is reconstructed in 4 times magnification, the input size of the LR image and the size of the HR image become 48×48 and 192×192. When the model is reconstructed and enlarged by 2 times, the size of the input LR image becomes 96×96, and the size of the HR image remains unchanged. The code is implemented with the PyTorch deep learning framework with MATLAB R2015b as the evaluation software. During the training, the total number of complete iterations of the NFSR model training reaches 500 times; the PSNR (peak signal-to-noise ratio) is used as the evaluation index, and the model with the highest PSNR value is saved as the best model. The enhancement method of NFSR (it is obtained by averaging the reconstruction results in 8 flip directions) is named NFSR+. The research includes (1) Exploring the impact of three types of modules on image reconstruction performance. The NFSR model uses a variety of modules. Three modules are special: non-local, multi-scale fusion and wide activation residual module. Among them, the non-local module is used to obtain global features of the core area of the target image. The multi-scale module is used to fuse channel features and enhance the contextual correlation of features in space. The wide activation residual module activates through expansion features before the rectified linear unit of the ordinary residual module, and is used to improve the reconstruction accuracy of the model. Ablation experiments demonstrate that they can improve the reconstruction accuracy to a certain extent. (2) Evaluating image reconstruction performance of the entire model NFSR. Quantitative results at 2x and 4x magnification show that NFSR+ achieves the highest accuracy (PSNR value) on the 5 benchmarks compared to several depth image reconstruction models. Corresponding qualitative results of image reconstruction show that the NFSR model exerts a good subjective effect on the reconstruction of the image structure, and the recognizability of the image is higher. (3) Applying to image segmentation and object detection tasks. NFSR can also maintain good segmentation accuracy and detection accuracy.
Conclusions: By learning from others' merits, the deep network model NFSR achieves higher image reconstruction accuracies. Through this network, it can be found that combining some network modules in other fields of image processing, such as non-local modules, can also improve the reconstruction accuracy when this combination is applied to the field of image reconstruction. At the same time, this phenomenon further confirms the excellent performance of the non-local module. The image super-resolution reconstruction task belongs to the low-level computer vision task and can serve as the middle and high-level vision tasks. In turn, excellent modules in mid- and high-level vision tasks can also be applied to image super-resolution reconstruction to improve its performance. This treatment shows that technologies in various fields can be inter-related for mutual learning and mutual promotion.