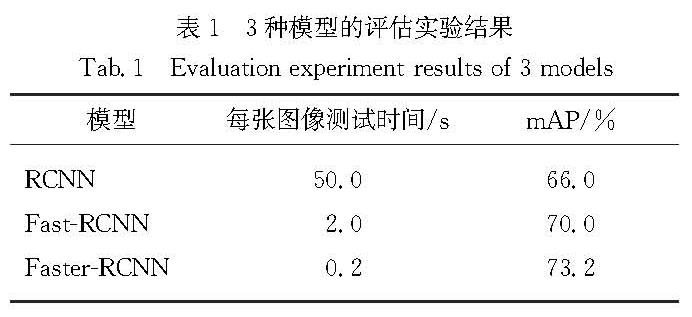
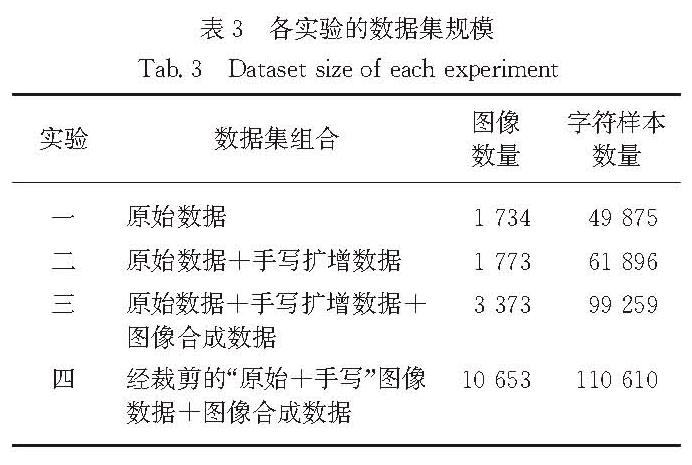
中国非物质文化遗产水书文化面临失传威胁,近年大量深度学习的方法用于手写古籍文字的识别.但水书古籍文字识别面临数据集建立和标注困难、样本不平衡等问题,研究进展不大,且鲜少进行水书古籍页面级的文字检测与识别.首先建立了一个较大规模的水书手写文字数据集,通过几种数据扩增方式,获得包含80个文字类别,共110 610个带标签的字符样本.将Faster-RCNN(faster-region based convolutional neural network)算法应用到水书古籍文字识别研究上,以不同组合的数据集作为输入进行实验,在全部80个目标类别上获得了91.95%的平均识别率,实现了页面级的端到端的水书古籍文字的准确定位与识别.实验结果表明,Faster-RCNN模型在目前的数据集上能很好地实现水书手写文字的检测与识别,文中采用的数据扩增方式能明显提升水书手写文字的识别率,为水书文化的保护和传承提供了新思路,对于解决实际应用场景中的水书文字识别问题具有重要意义.
Objectives: Representing the custom and the language of Shui people in China, the Shuishu (SS) culture has been included in the China's national intangible-cultural-heritage list since 2006. At present, it is facing the threat of extinction. In recent years, a large number of deep learning methods have been used to recognize characters in handwritten ancient books. Despite such efforts, however, these methods are rarely used for character detection and recognition of SS ancient books. In this study, we aim to use the object detection technology to achieve the page-level detection and recognition of Shuishu handwritten characters (SSHC) in SS ancient books.
Methods : Due to the unavailability of the public SSHC dataset, we need to establish one first and then choose a model for the SSHC recognition. We collected images of ancient SS books in areas where Shui people lived, then manually annotated the target classes in the SS images. For classes with small sample sizes, we used several data augmentation methods, such as manual handwriting, image synthesis and image cropping among others. By comparing advantages and disadvantages of three target detection models, including Faster RCNN (faster region-based convolutional neural networks), YOLO (you only look once)and SSD (single shot multi-box detector), we choose Faster RCNN to detect and recognize SSHC.
Results : Finally, we built a well-labelled and sizable SS handwritten character dataset, which contains 80 categories with a total of 110 610 labeled character samples. To verify the detection and recognition effect of Faster R-CNN on SSHC, and to discuss the influence of the data augmentation method mentioned in this study, we carry out experiments with different combinations of datasets as the input. In experiment 1, we use the original dataset, and the average recognition accuracy reaches only 62.21%, and in the case of sparse samples for some classes, the recognition rate even equals 0. In experiment 2, we use the original dataset plus the data by manual handwriting, and the average recognition accuracy increased by 2.26 percentage points. The dataset of experiment 3 includes the dataset of experiment 2 plus the data of image synthesis, which further reduces the gap between the number of samples in each category. In experiment 3, we obtain the average recognition accuracy of 90.91%, which increases by 18.52 percentage points compared to that of experiment 2. The dataset of experiment 4 includes the cropped data plus the image-synthesized data, resulting in an highest average recognition accuracy of 91.95%, and achieving end-to-end accurate positioning and recognition of SSHC at the page level.
Conclusions: Experimental results show that the Faster R-CNN can achieve good detection and recognition of SSHC on the current dataset, and the data augmentation method used in this study can significantly improve the recognition rate of SSHC. Our study provides new ideas for the preservation and transmission of SS culture, and offers a guide for solving the problem of SS character recognition in practical application scenarios.
Methods : Due to the unavailability of the public SSHC dataset, we need to establish one first and then choose a model for the SSHC recognition. We collected images of ancient SS books in areas where Shui people lived, then manually annotated the target classes in the SS images. For classes with small sample sizes, we used several data augmentation methods, such as manual handwriting, image synthesis and image cropping among others. By comparing advantages and disadvantages of three target detection models, including Faster RCNN (faster region-based convolutional neural networks), YOLO (you only look once)and SSD (single shot multi-box detector), we choose Faster RCNN to detect and recognize SSHC.
Results : Finally, we built a well-labelled and sizable SS handwritten character dataset, which contains 80 categories with a total of 110 610 labeled character samples. To verify the detection and recognition effect of Faster R-CNN on SSHC, and to discuss the influence of the data augmentation method mentioned in this study, we carry out experiments with different combinations of datasets as the input. In experiment 1, we use the original dataset, and the average recognition accuracy reaches only 62.21%, and in the case of sparse samples for some classes, the recognition rate even equals 0. In experiment 2, we use the original dataset plus the data by manual handwriting, and the average recognition accuracy increased by 2.26 percentage points. The dataset of experiment 3 includes the dataset of experiment 2 plus the data of image synthesis, which further reduces the gap between the number of samples in each category. In experiment 3, we obtain the average recognition accuracy of 90.91%, which increases by 18.52 percentage points compared to that of experiment 2. The dataset of experiment 4 includes the cropped data plus the image-synthesized data, resulting in an highest average recognition accuracy of 91.95%, and achieving end-to-end accurate positioning and recognition of SSHC at the page level.
Conclusions: Experimental results show that the Faster R-CNN can achieve good detection and recognition of SSHC on the current dataset, and the data augmentation method used in this study can significantly improve the recognition rate of SSHC. Our study provides new ideas for the preservation and transmission of SS culture, and offers a guide for solving the problem of SS character recognition in practical application scenarios.