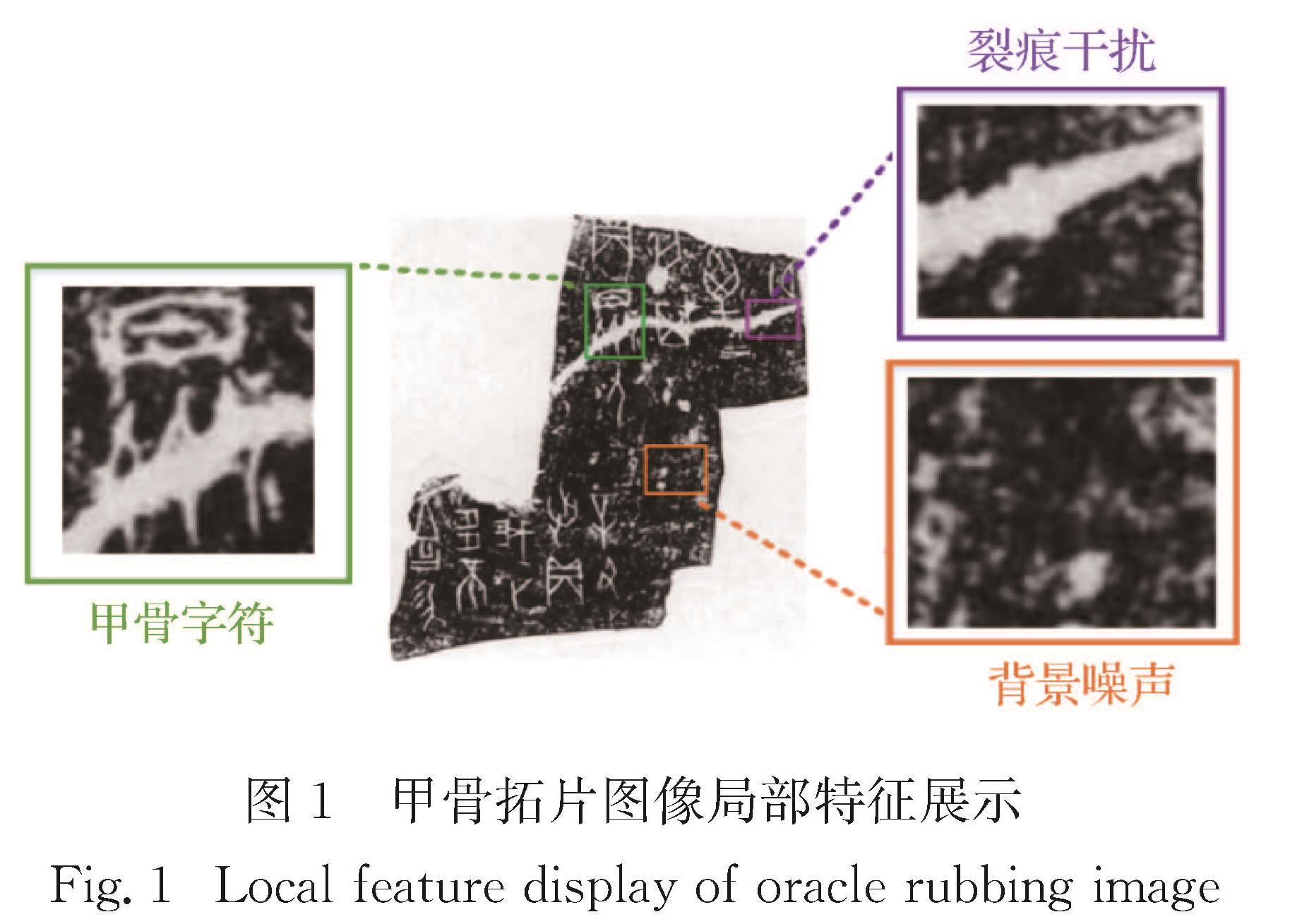
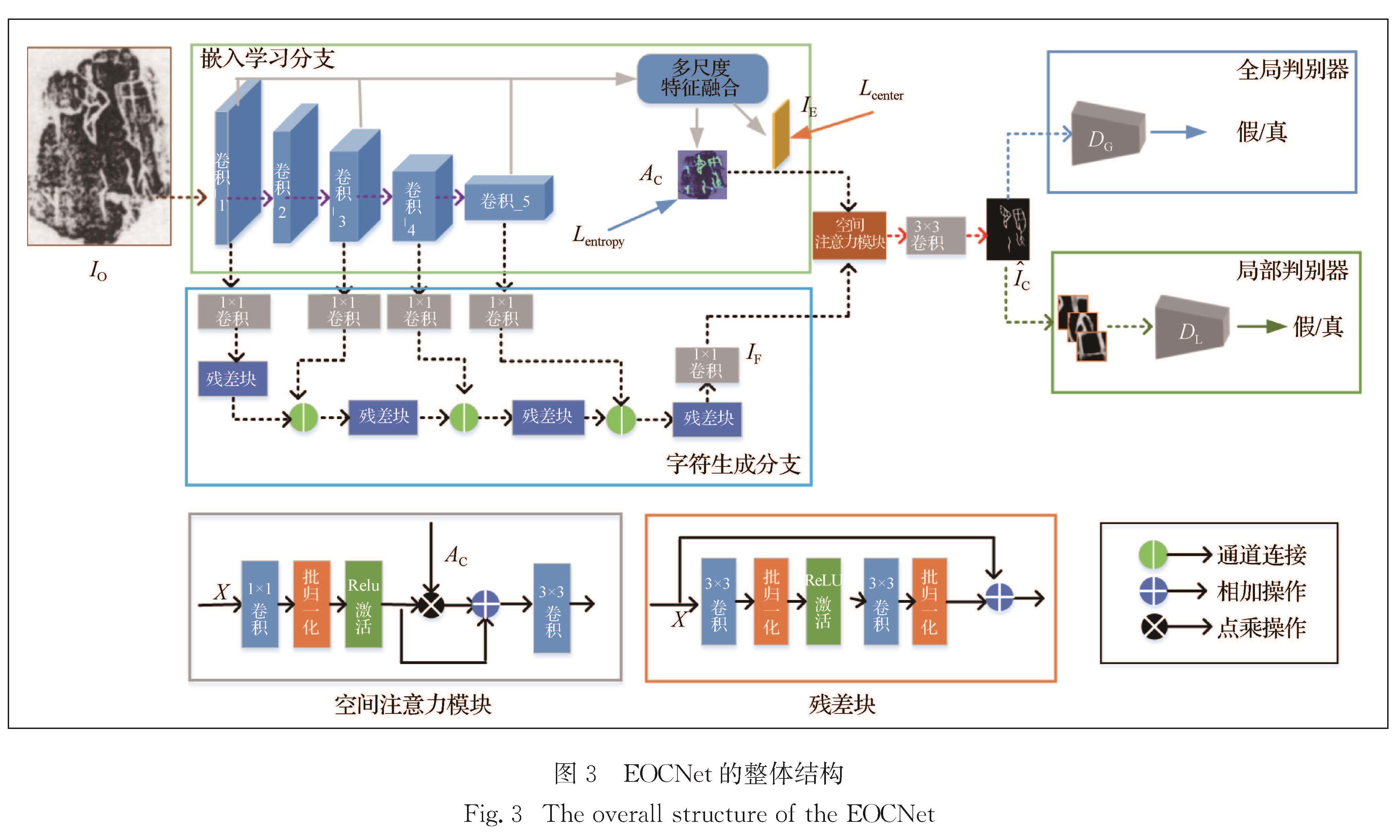
为了从甲骨拓片图像中自动提取甲骨字符信息,本文基于深度神经网络构建了一个甲骨字符提取的双分支融合网络(dual-branch fusion network for extracting Oracle characters,EOCNet).EOCNet包含3个基本特点:首先,为了能够利用生成网络较强的结构信息描述能力,EOCNet以对抗生成网络(generative adversarial network,GAN)为基本骨架,将甲骨字符提取问题视为图像到图像的转换任务; 其次,为了能利用语义分割网络较强的拓片图像背景和甲骨字符的区分能力,EOCNet将语义分割网络融入生成器网络,并通过空间注意力模型(spatial attention module,SAM)来提高甲骨字符区域特征在生成甲骨字符图像中的作用; 再次,为获取内容完整且细节清晰的生成结果,EOCNet结合全局判别器网络和局部判别器网络对生成的甲骨字符图像进行一致性判别.实验结果表明,相比于主流的基于深度学习的图像生成和分割方法,本文模型能够生成更高质量的甲骨字符图像.
Objectives: As an important carrier of Oracle Bone Inscriptions (OBI), the surface of oracle bone rubbings endures serious degradation, such as noise and cracks, which seriously interferes with the visibility and the readability of OBI, and brings great obstacles to the research and activation and utilization of OBI. In this paper, we construct a dual-branch fusion model based on deep neural network to extract oracle bone characters from high noise rubbing images, and indirectly improve the visibility of characters.
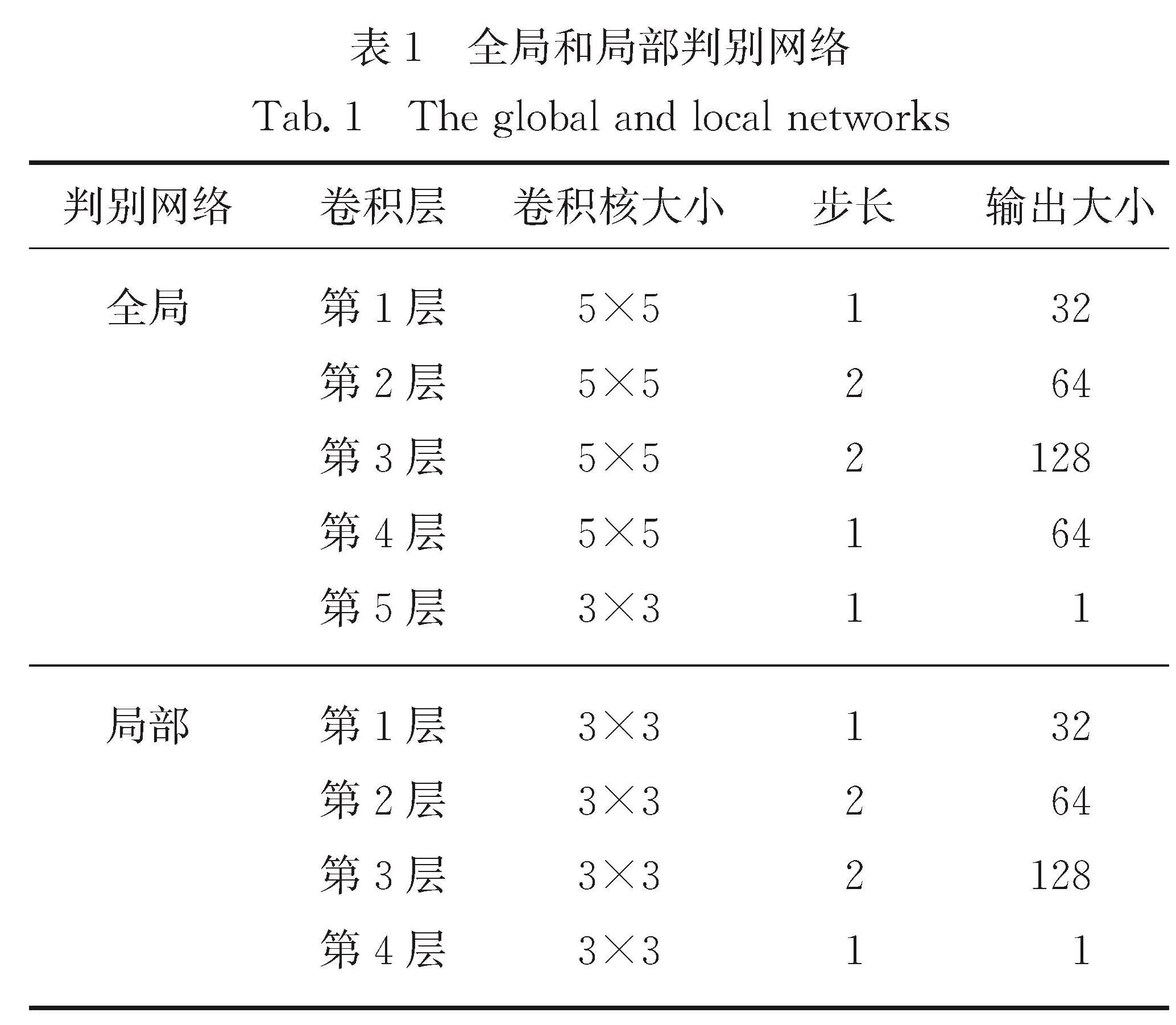
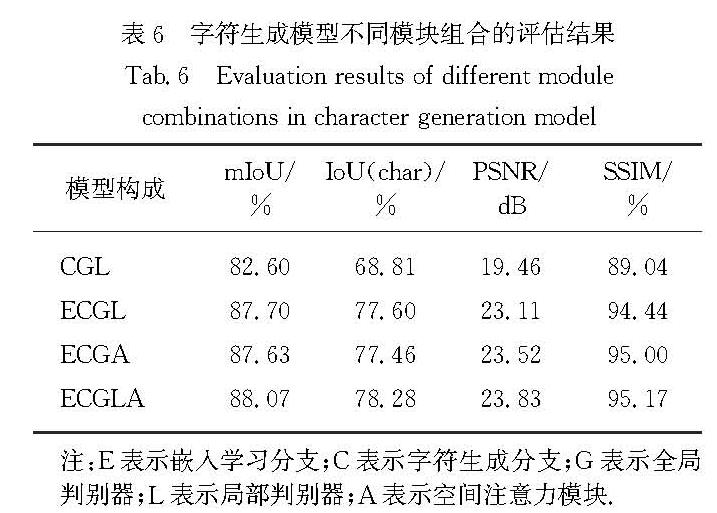
Methods : Three basic characteristics are included in this model. First, for the purpose of utilizing the powerful ability of generative networks to describe structural information, the proposed model takes generative adversarial network (GAN) as its backbone, regarding the task of OBI character extraction as a kind of image-to-image conversion. Second, employing the strong capacity of semantic segmentation networks to distinguish the background and OBI character in rubbing images, we integrate a semantic segmentation network into the generator part of the model, and improve the role of OBI characters in the generation of OBI character images through a spatial attention module (SAM). Third, for obtaining a complete and detailed result, the proposed model combines a global discriminator network and a local discriminator network to judge the consistency of the generated OBI character image.
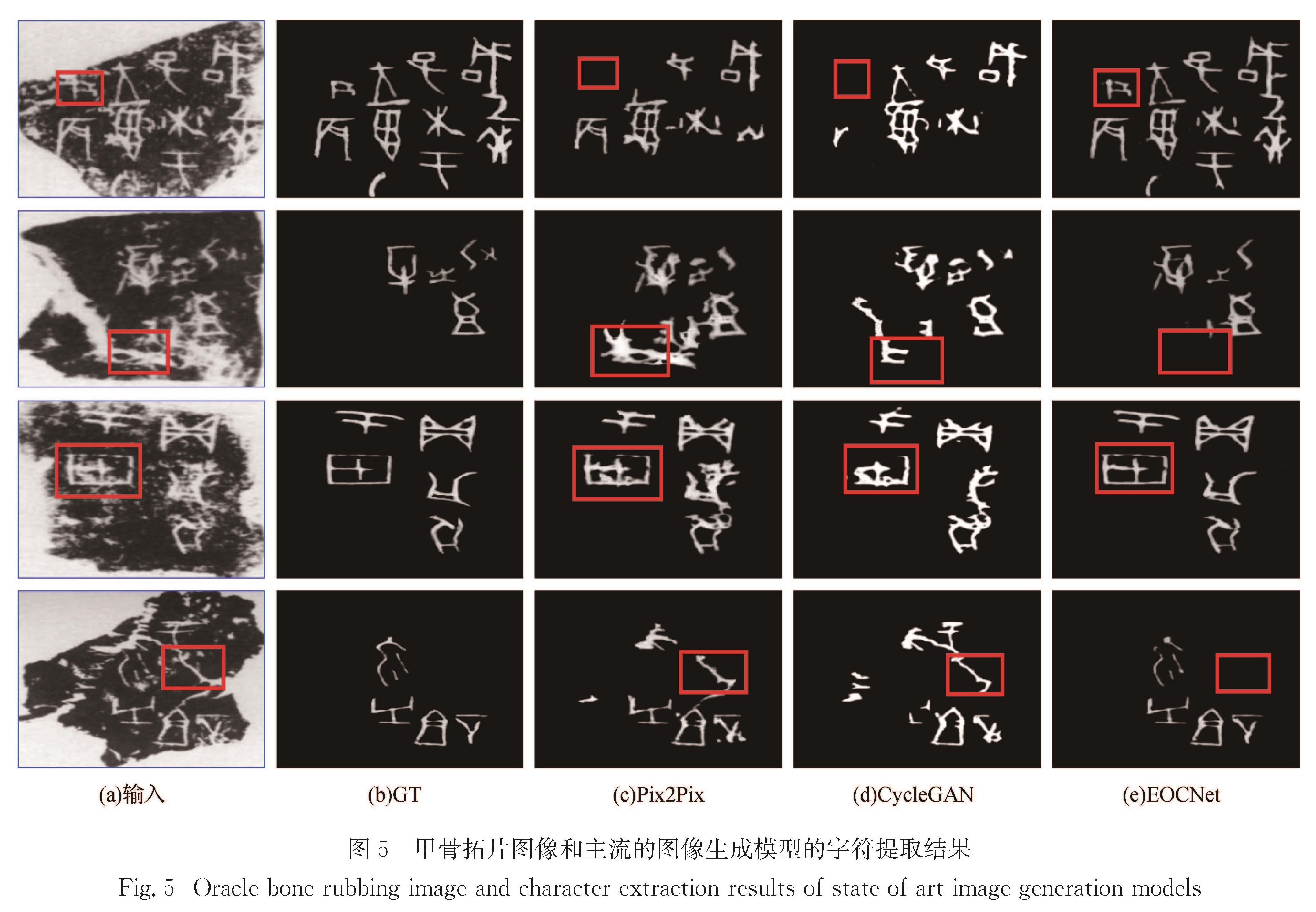
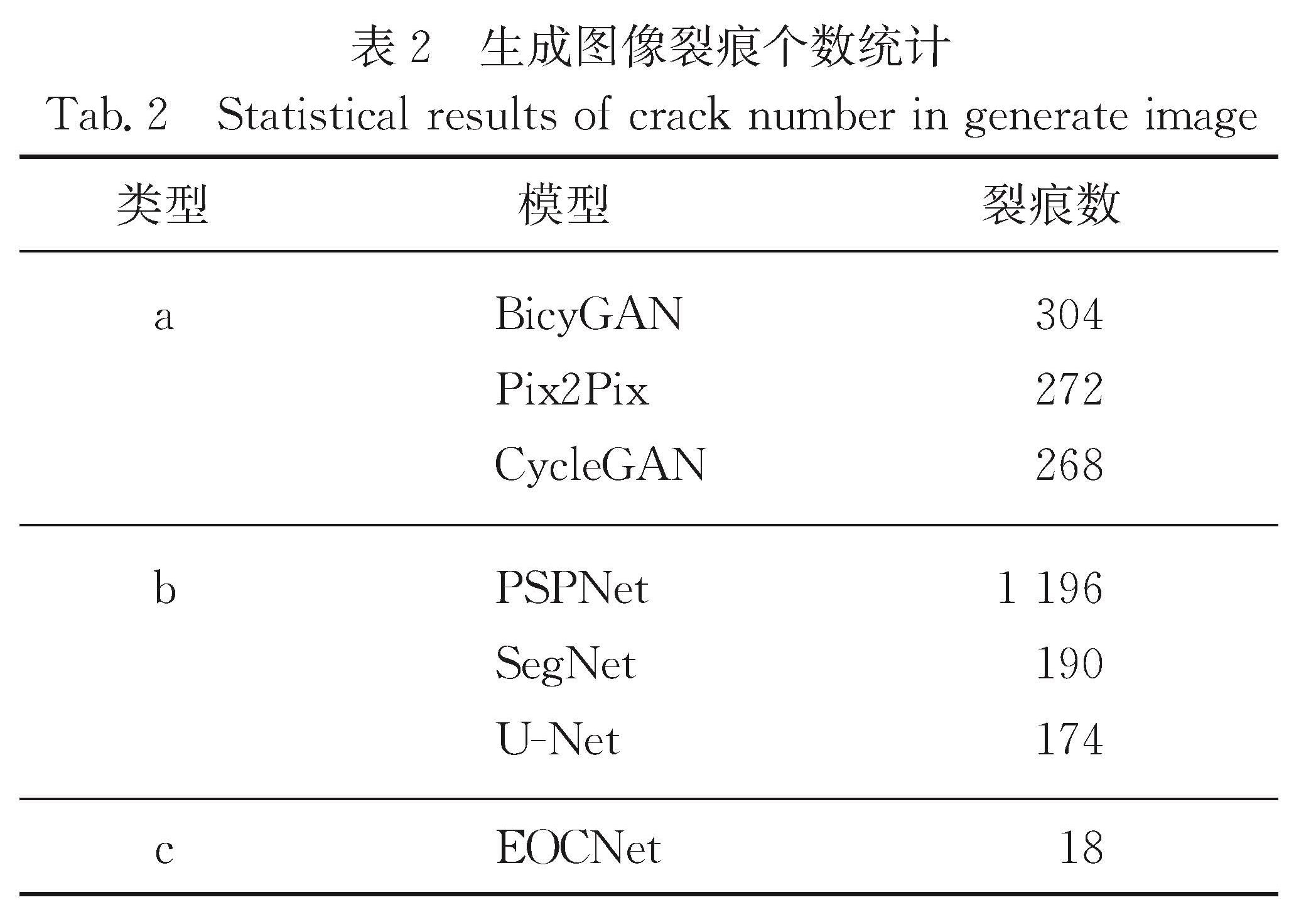
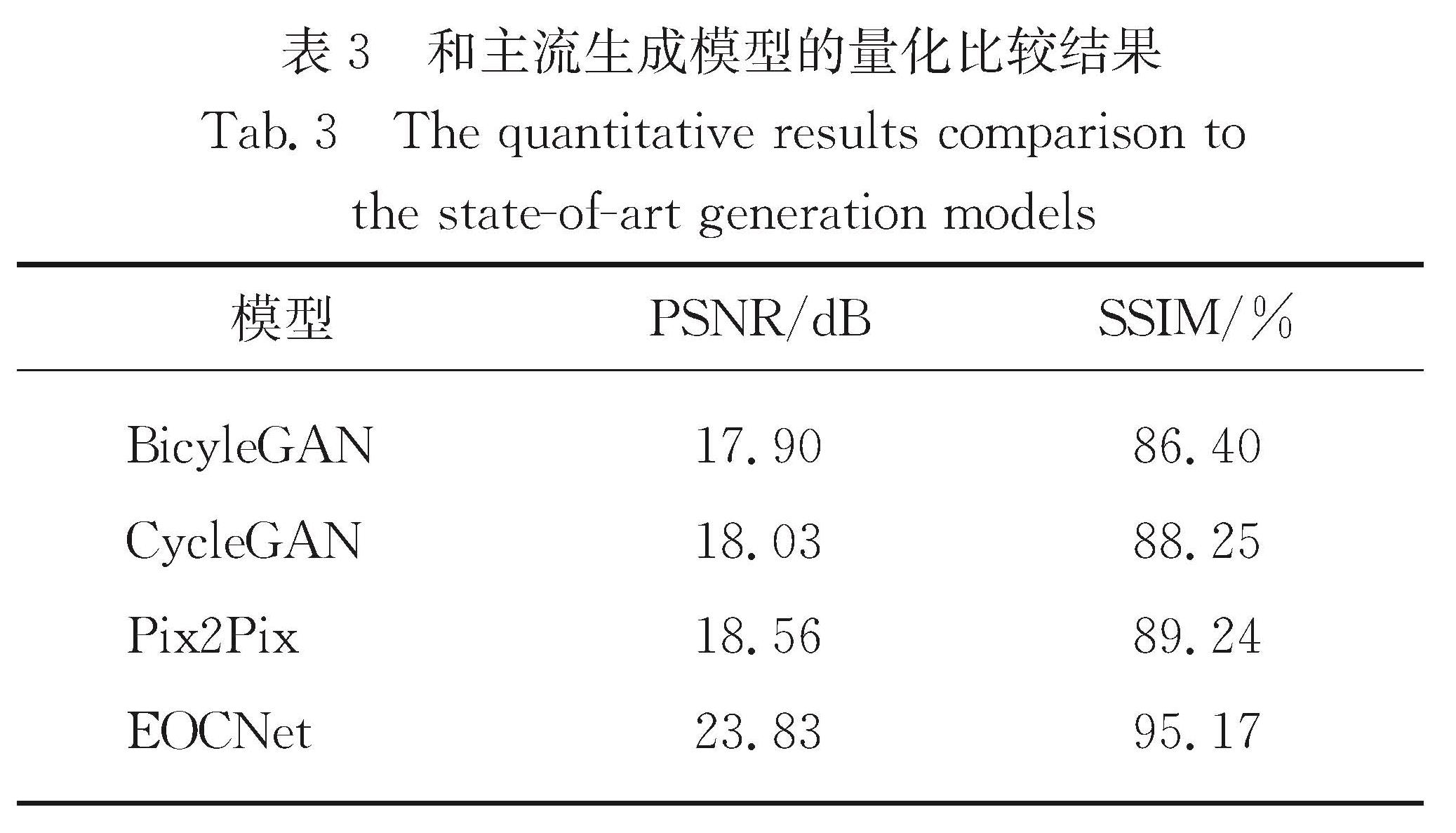
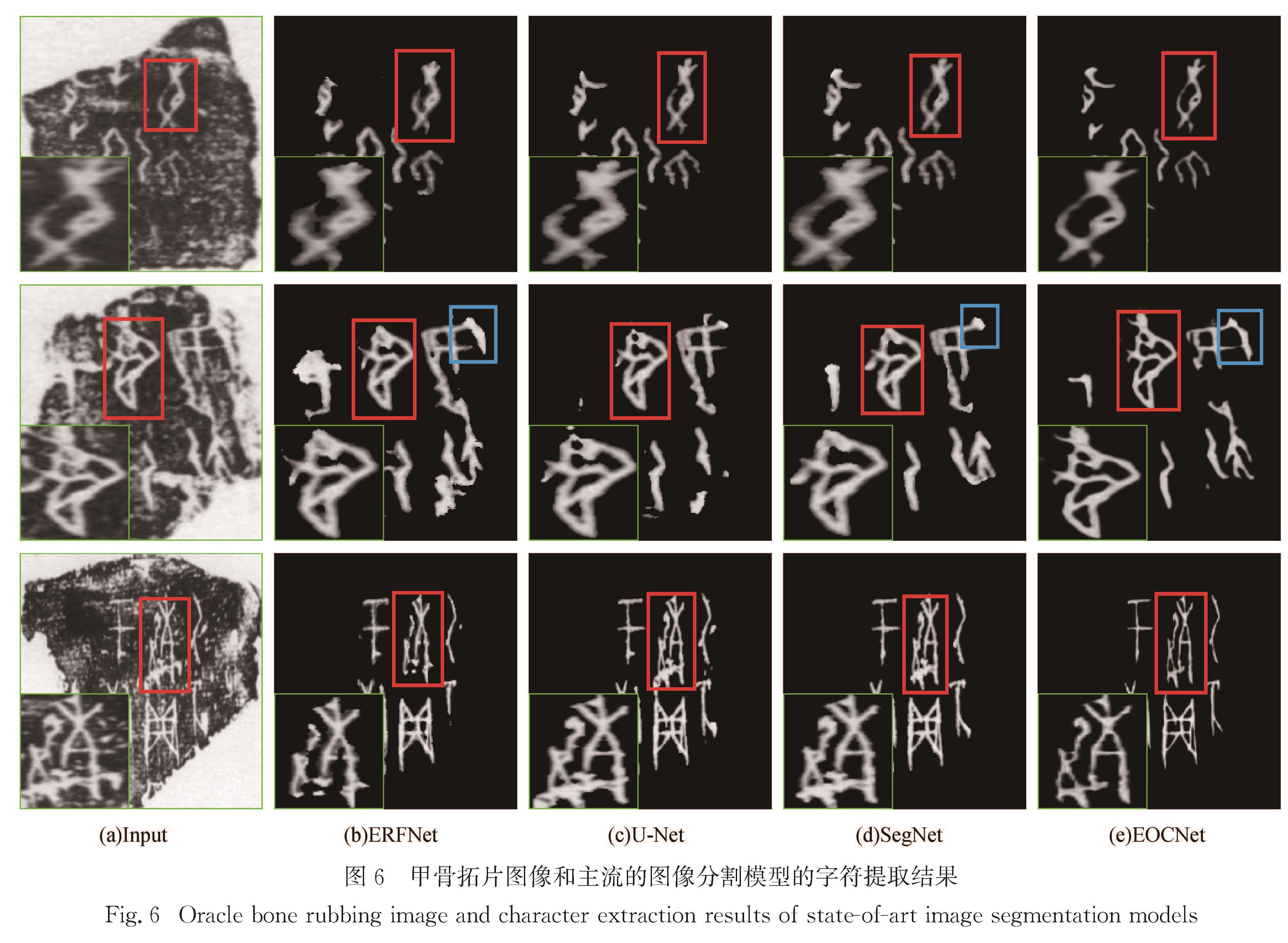
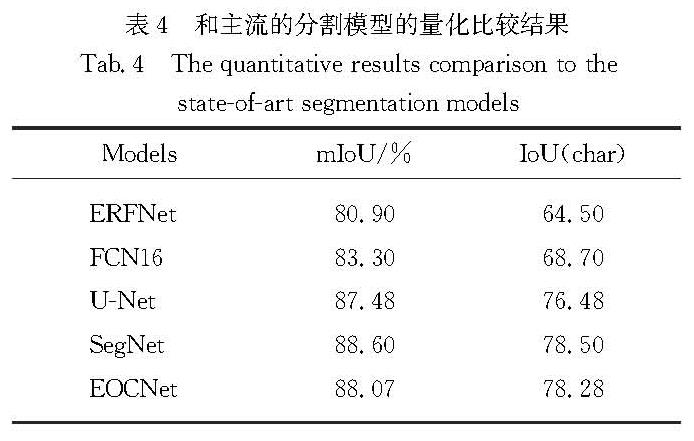
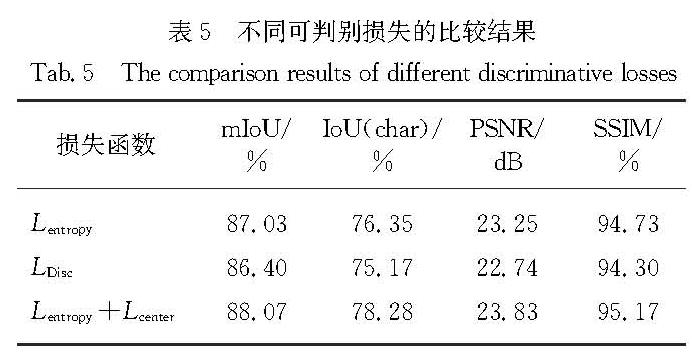
Results : From perspectives of image generation, we compared the performance of the model with that of several mainstream generation-based methods(Pix2Pix, CycleGAN, BicycleGAN). The model secures stronger abilities to deal with noise and crack interference. Generated character images can not only maintain complete and clear stroke details, but also endure almost no additional noises or crack interferences.In addition,on PNSR and SSIMquantitative metrics commonly used in generation algorithms, themodeloutperforms the suboptimal result Pix2Pix by a large margin (PSNR and SSIM are improved by 5.27dB and 5.93 percentage points, respectively).From the perspective of segmentation, our model is compared to several mainstream segmentation-based methods(ERFNet, U-Net, and SegNet).Visually, the character strokes generated by the segmentation method are relatively rough and some strokes are missing. However, local details of those characters generated by our proposed method appear obviously clearer and more natural. On the IoU quantitative metrics commonly used in segmentation algorithms, the proposed model exhibits segmentation capabilities equivalent to mainstream segmentation methods, with mIoU and IoU(char) reaching88.07% and 78.28%.
Conclusions: Based on deep-learning technology, we construct a special oracle bone character extraction model, which can automatically extract the character information in the rubbing image and generate the oracle bone character image, significantly accelerating the research and promotion of OBI. Furthermore, for a long time, complex noises and all kinds of crack interferences in rubbing images become notable obstacles that hinder solving oracle-related visual tasks. Our results show that discriminable features of rubbing images in the embedded space can be simply and effectively learned. Finally, this method can not only effectively avoid the direct processing of complex noises, cracks and other interferences in the rubbing image, but also become conducive to the implementation of end-to-end method.
Methods : Three basic characteristics are included in this model. First, for the purpose of utilizing the powerful ability of generative networks to describe structural information, the proposed model takes generative adversarial network (GAN) as its backbone, regarding the task of OBI character extraction as a kind of image-to-image conversion. Second, employing the strong capacity of semantic segmentation networks to distinguish the background and OBI character in rubbing images, we integrate a semantic segmentation network into the generator part of the model, and improve the role of OBI characters in the generation of OBI character images through a spatial attention module (SAM). Third, for obtaining a complete and detailed result, the proposed model combines a global discriminator network and a local discriminator network to judge the consistency of the generated OBI character image.
Results : From perspectives of image generation, we compared the performance of the model with that of several mainstream generation-based methods(Pix2Pix, CycleGAN, BicycleGAN). The model secures stronger abilities to deal with noise and crack interference. Generated character images can not only maintain complete and clear stroke details, but also endure almost no additional noises or crack interferences.In addition,on PNSR and SSIMquantitative metrics commonly used in generation algorithms, themodeloutperforms the suboptimal result Pix2Pix by a large margin (PSNR and SSIM are improved by 5.27dB and 5.93 percentage points, respectively).From the perspective of segmentation, our model is compared to several mainstream segmentation-based methods(ERFNet, U-Net, and SegNet).Visually, the character strokes generated by the segmentation method are relatively rough and some strokes are missing. However, local details of those characters generated by our proposed method appear obviously clearer and more natural. On the IoU quantitative metrics commonly used in segmentation algorithms, the proposed model exhibits segmentation capabilities equivalent to mainstream segmentation methods, with mIoU and IoU(char) reaching88.07% and 78.28%.
Conclusions: Based on deep-learning technology, we construct a special oracle bone character extraction model, which can automatically extract the character information in the rubbing image and generate the oracle bone character image, significantly accelerating the research and promotion of OBI. Furthermore, for a long time, complex noises and all kinds of crack interferences in rubbing images become notable obstacles that hinder solving oracle-related visual tasks. Our results show that discriminable features of rubbing images in the embedded space can be simply and effectively learned. Finally, this method can not only effectively avoid the direct processing of complex noises, cracks and other interferences in the rubbing image, but also become conducive to the implementation of end-to-end method.