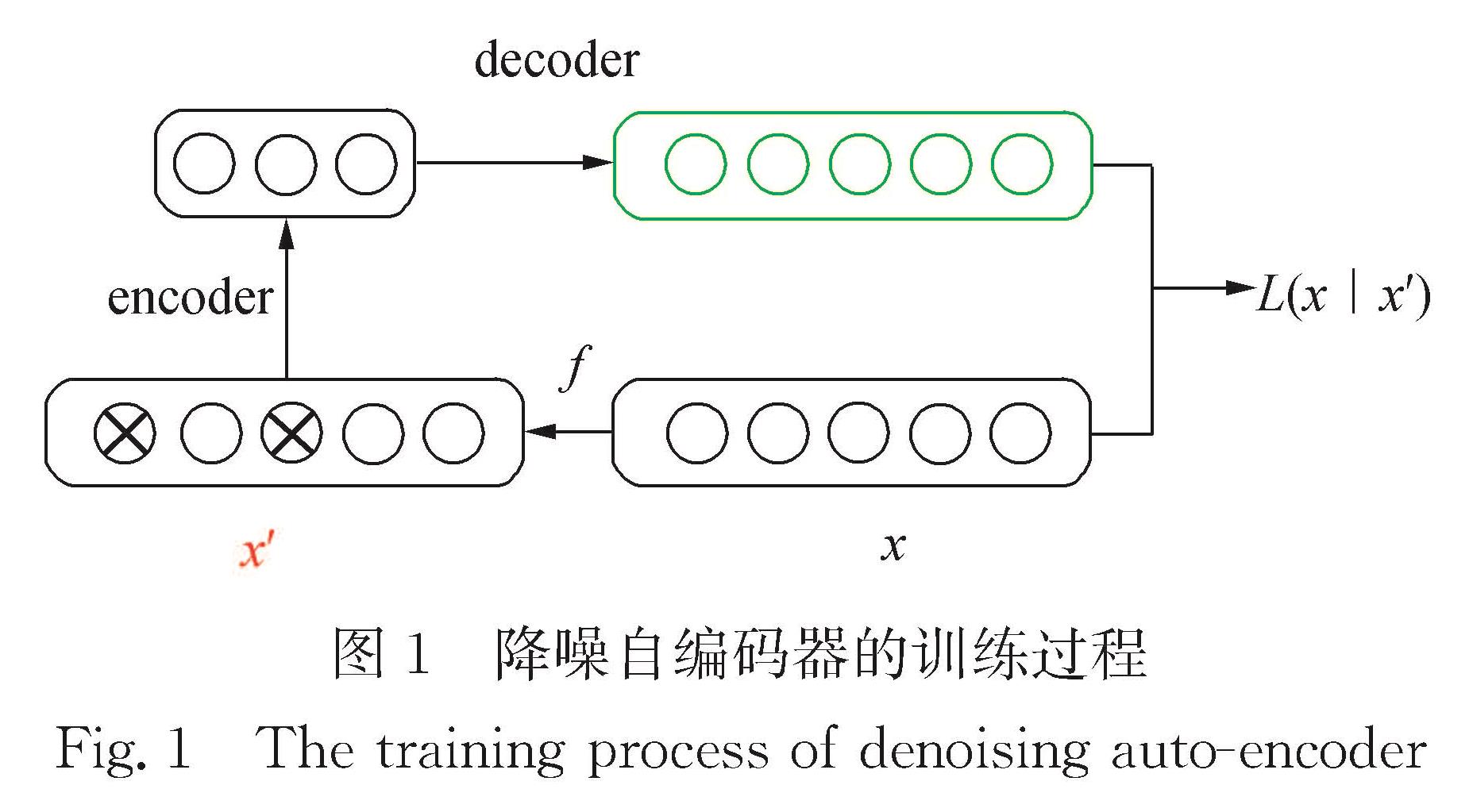
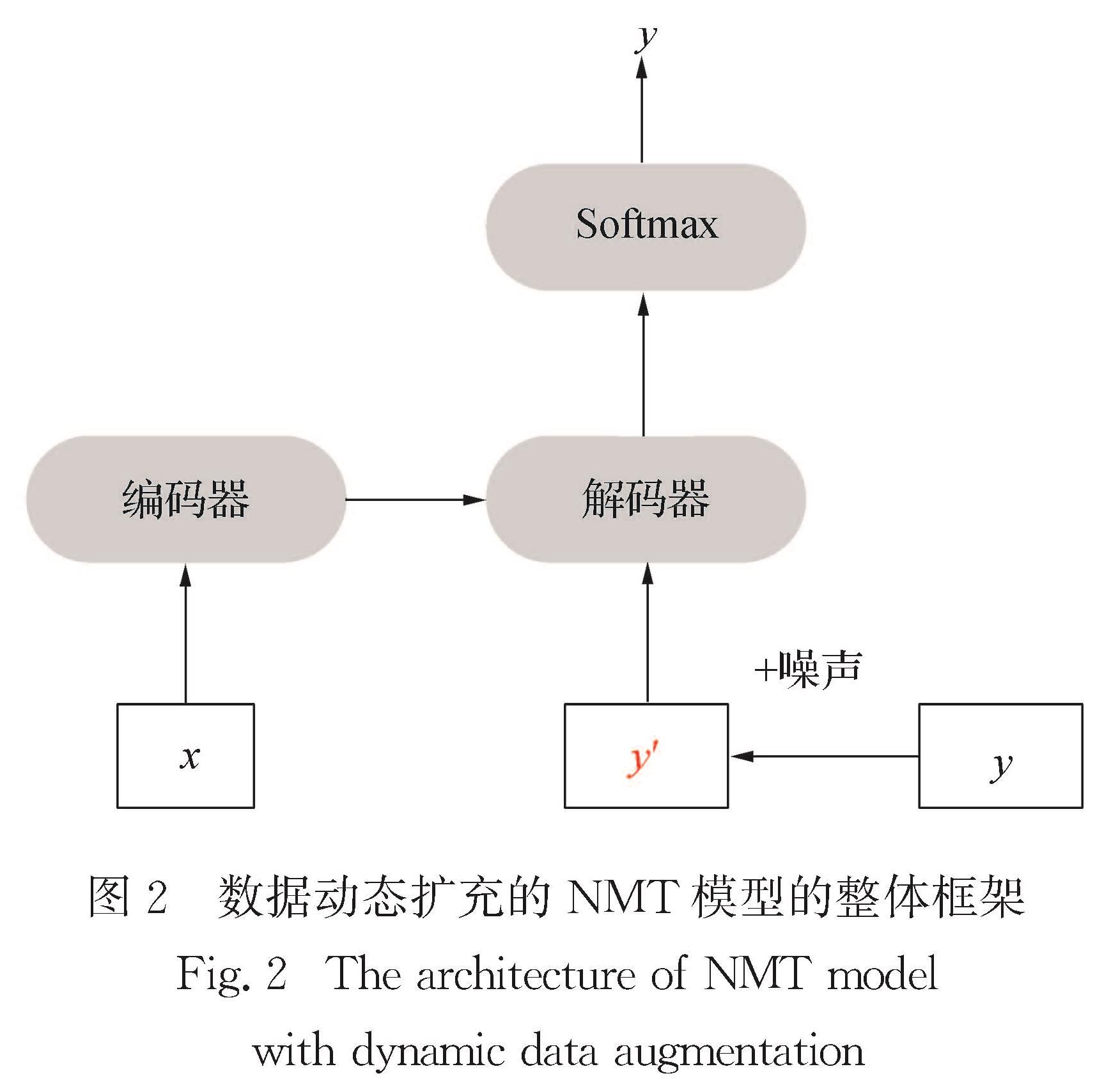
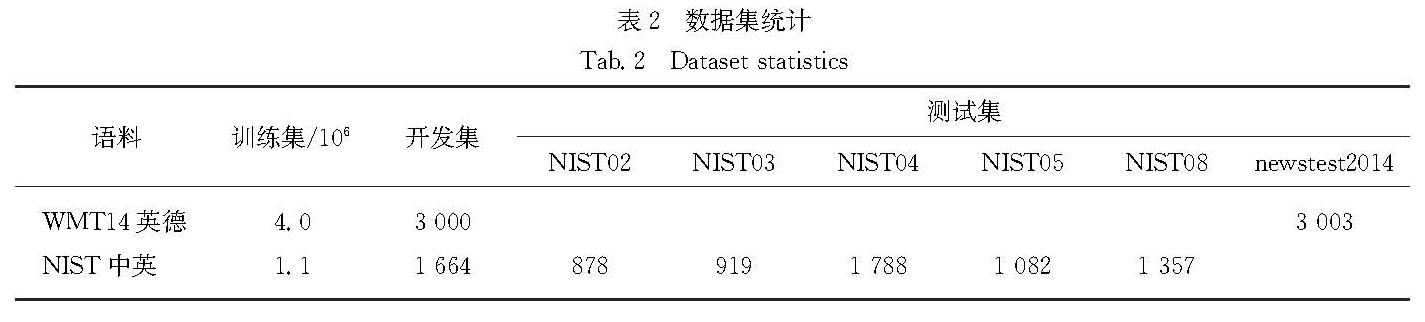
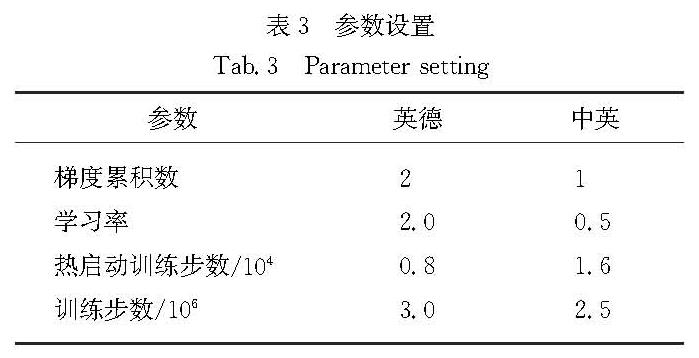
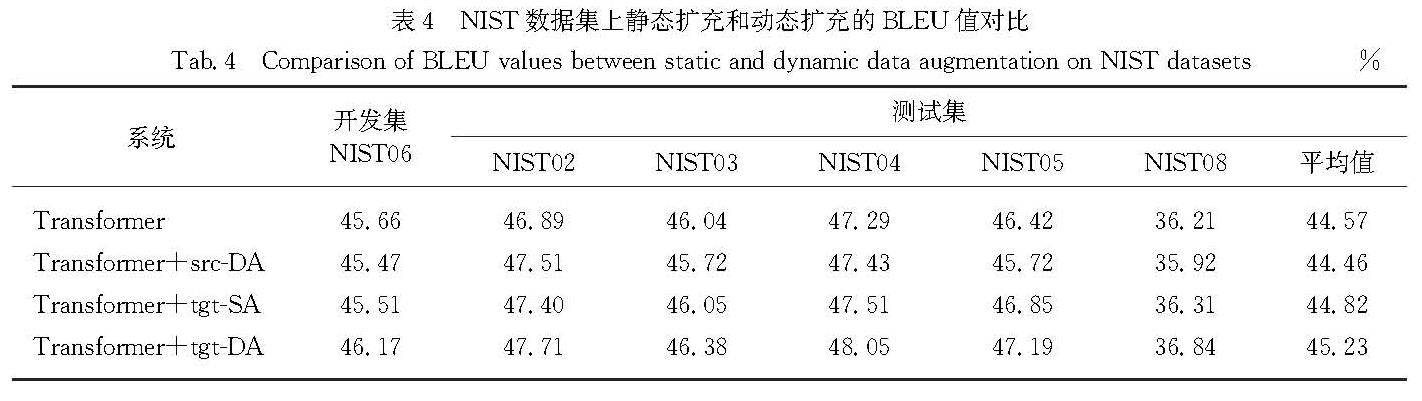
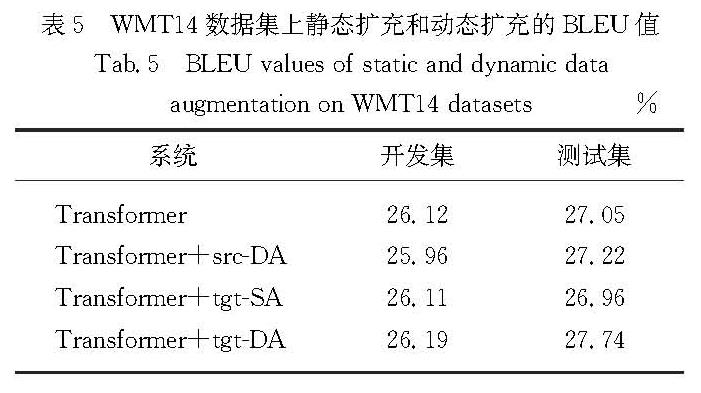
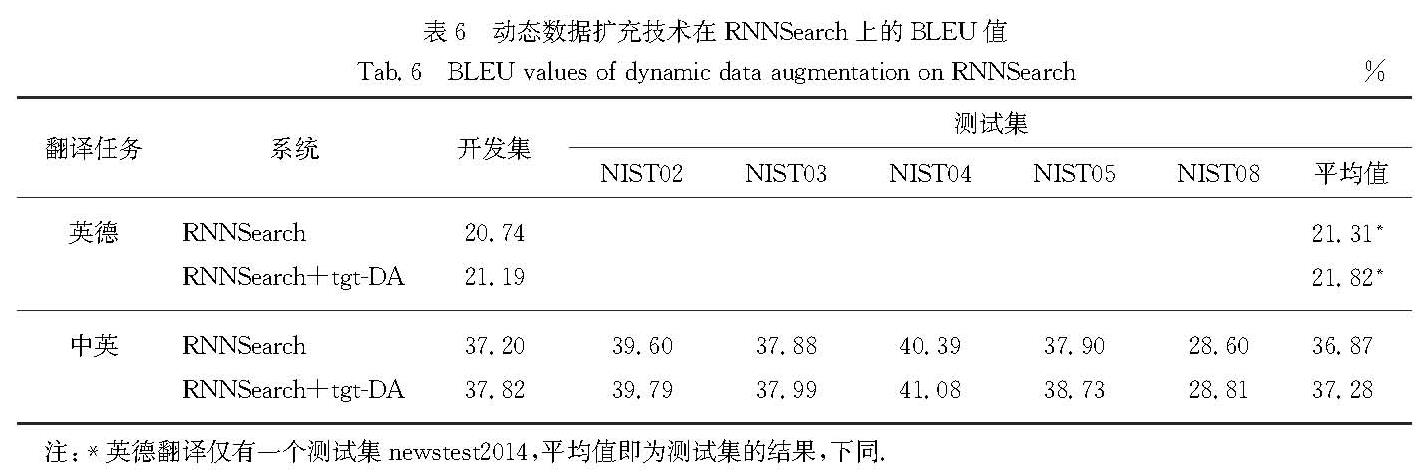
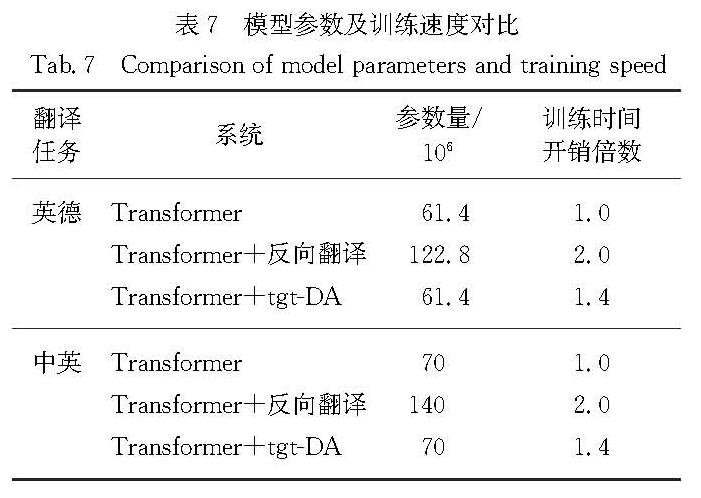
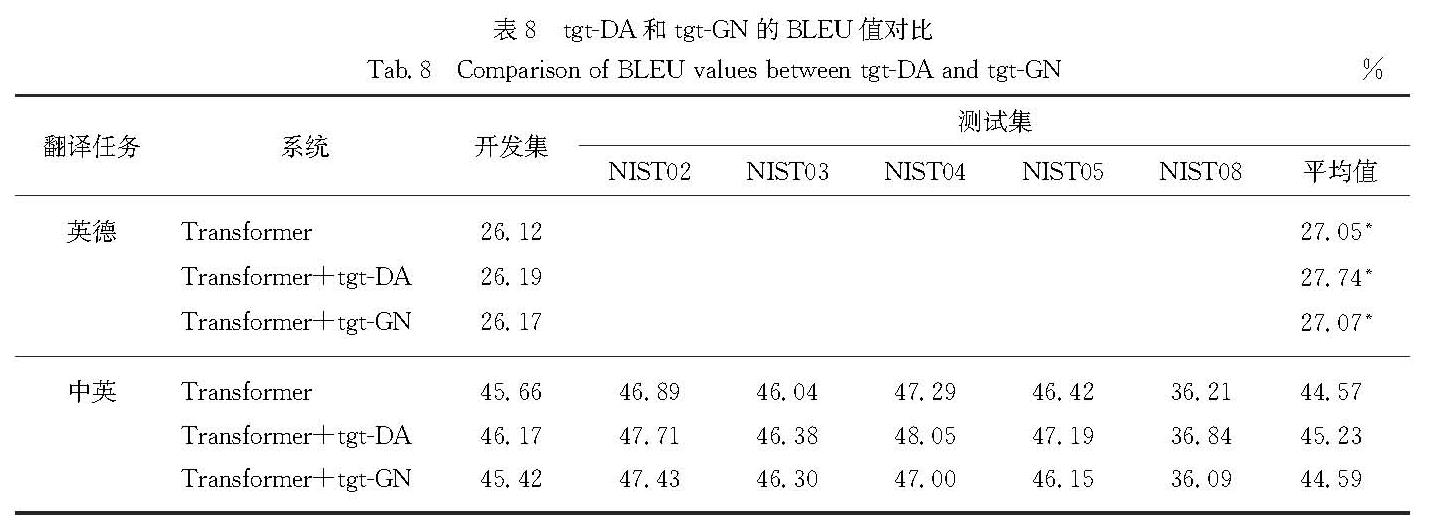
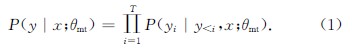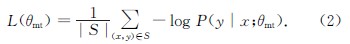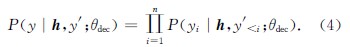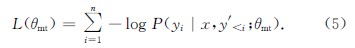反向翻译作为一种用于神经机器翻译的数据扩充方法,被广泛应用于单语数据的训练.然而,这些方法通常需要大规模源端或目标端单语数据、双语词典等.基于此,提出了一种在不引入外部资源情况下的简单数据扩充方法.该方法在每次加载目标端句子时,按照一定策略对句子中单词进行随机噪声化,以实现原始平行数据目标端的动态数据扩充,从而提高目标端语言模型对句子的表达能力.不同于需要大量单语数据的反向翻译,该方法只使用平行语料.这一策略意味着不需要训练额外的逆向模型.在英德和中英翻译任务上的实验结果表明,该方法使标准Transformer系统的双语互译评估(BLEU)值分别提高了0.69和0.66个百分点.
As a type of data expansion method for neural machine translation,back-translation has been widely used to train with monolingual data.However,these methods often require large-scale source side or target side monolingual datasets,bilingual dictionaries and so on.This paper proposes a simple data expansion method without introducing external resources.Each time the target sentence is loaded,the words in the sentence are randomly noised according to a certain strategy to realize the target data dynamic expansion of the original parallel data,so as to improve the expression ability of the target language model to the sentence.Specifically,different from back-translation which requires huge amount of monolingual data,this method only use parallel corpuses.This strategy means that we do not need to train an additional reverse model.Experimental results regarding English-German and Chinese-English translation tasks show that our approach significantly improves the bilingual evaluation understudy(BLEU)values of a standard Transformer system by 0.69 and 0.66 percentage points respectively.