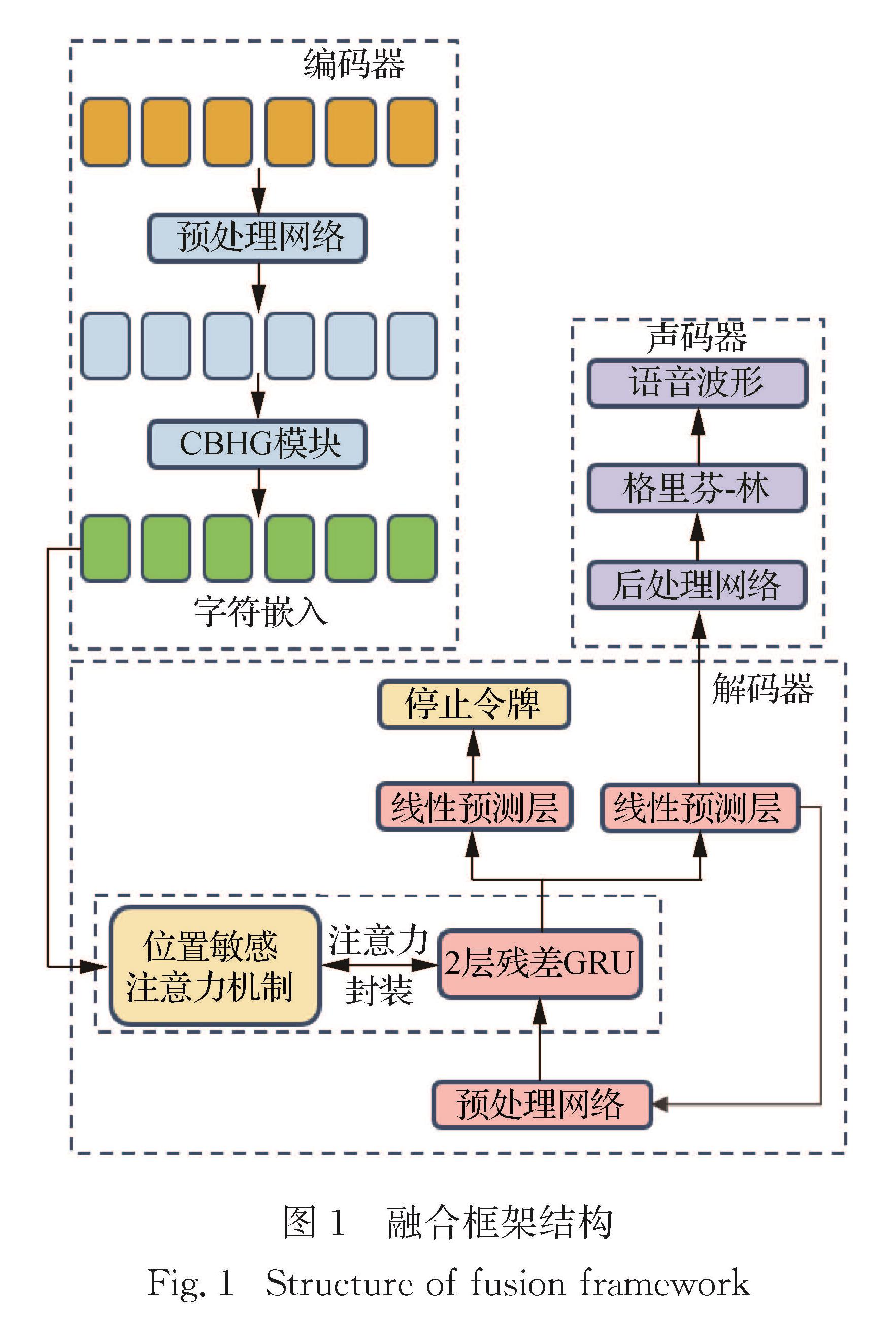
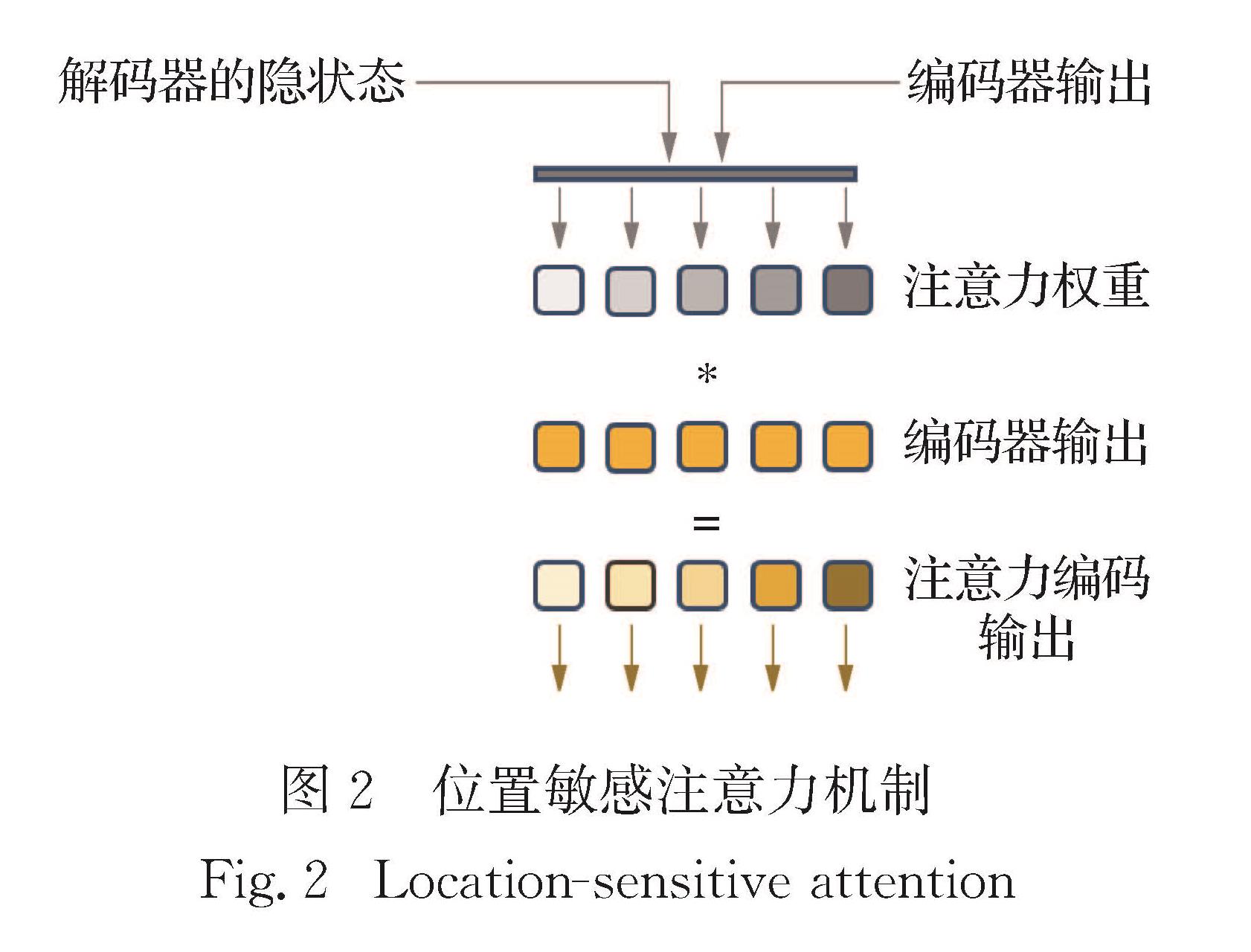
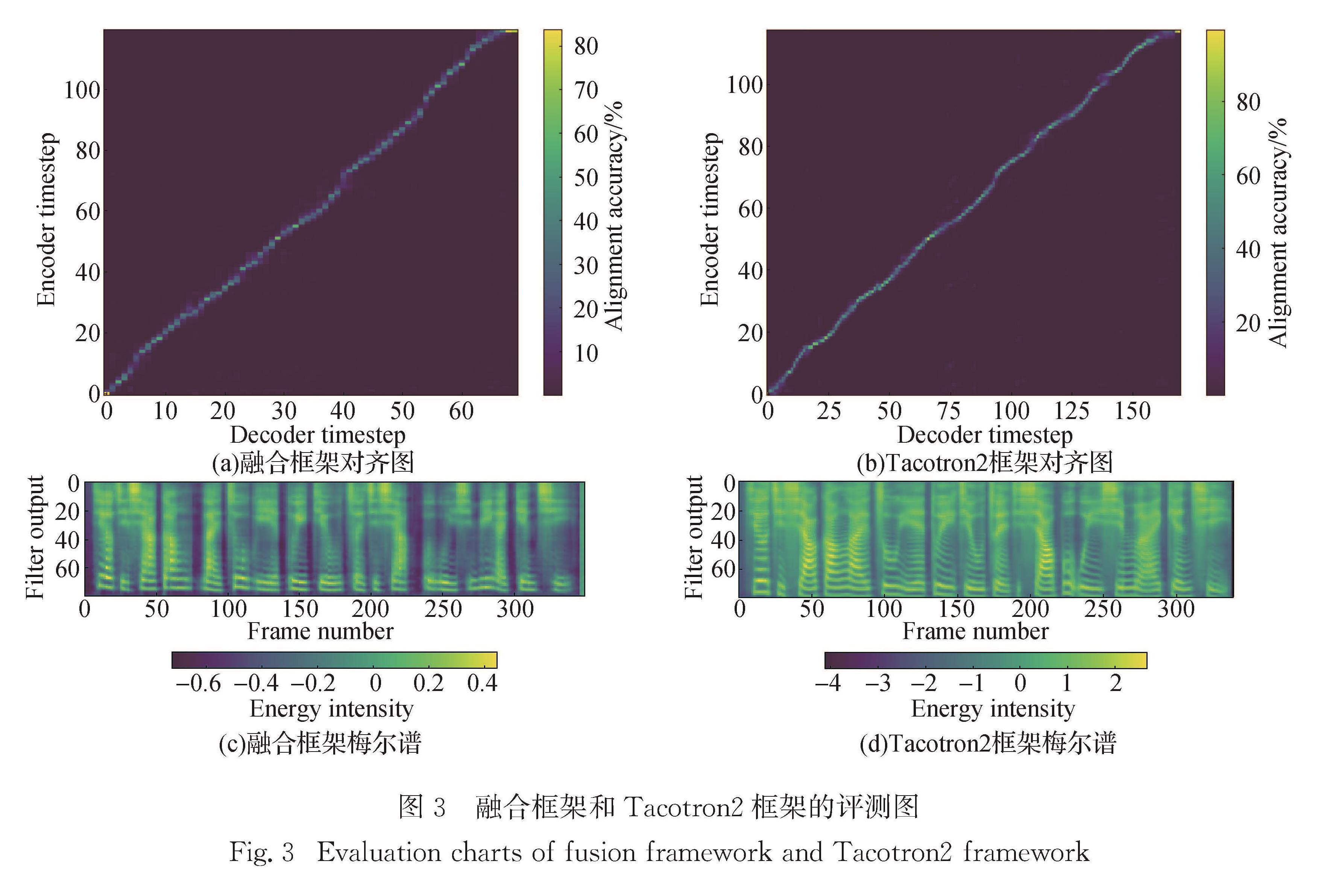
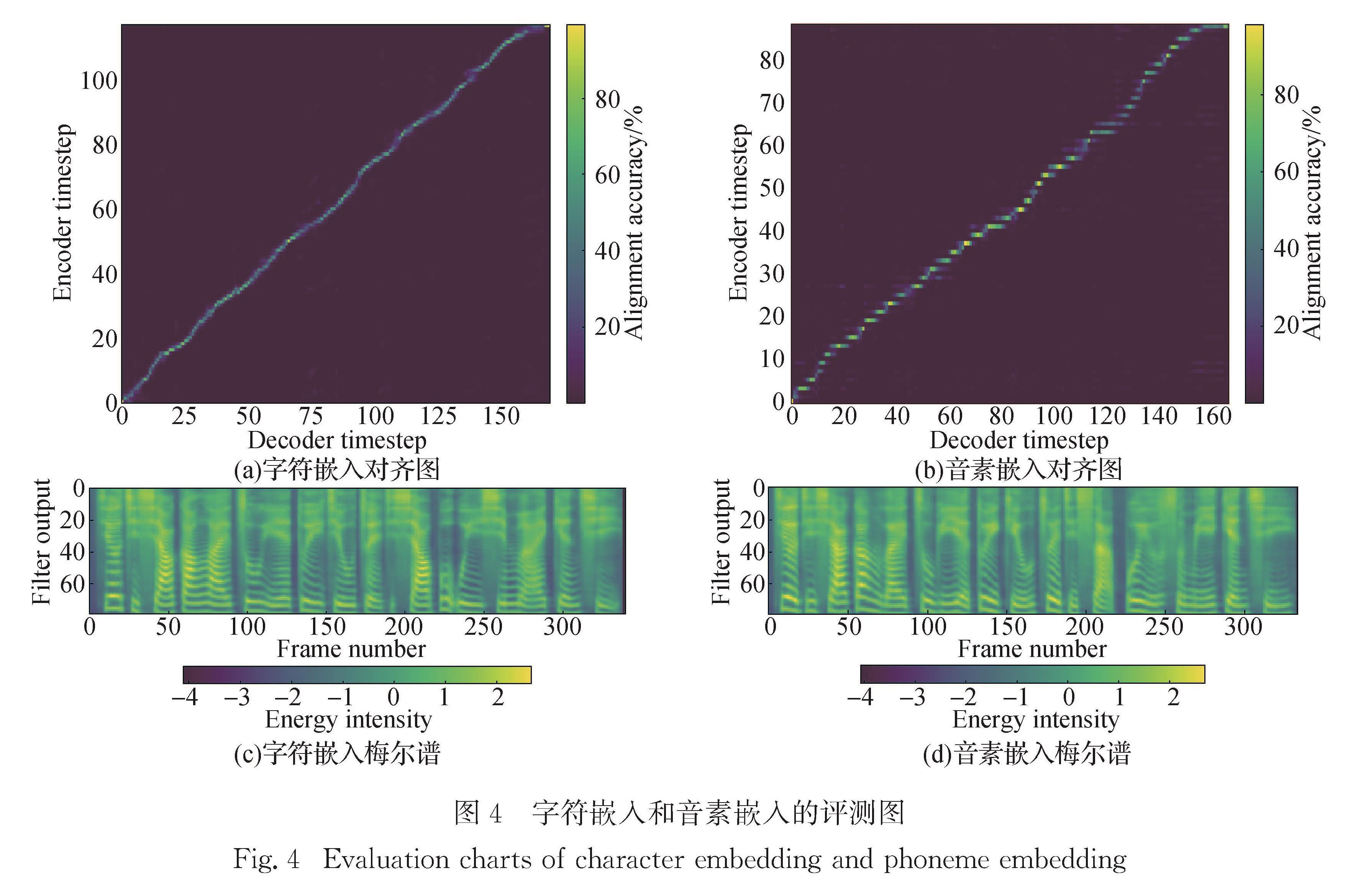
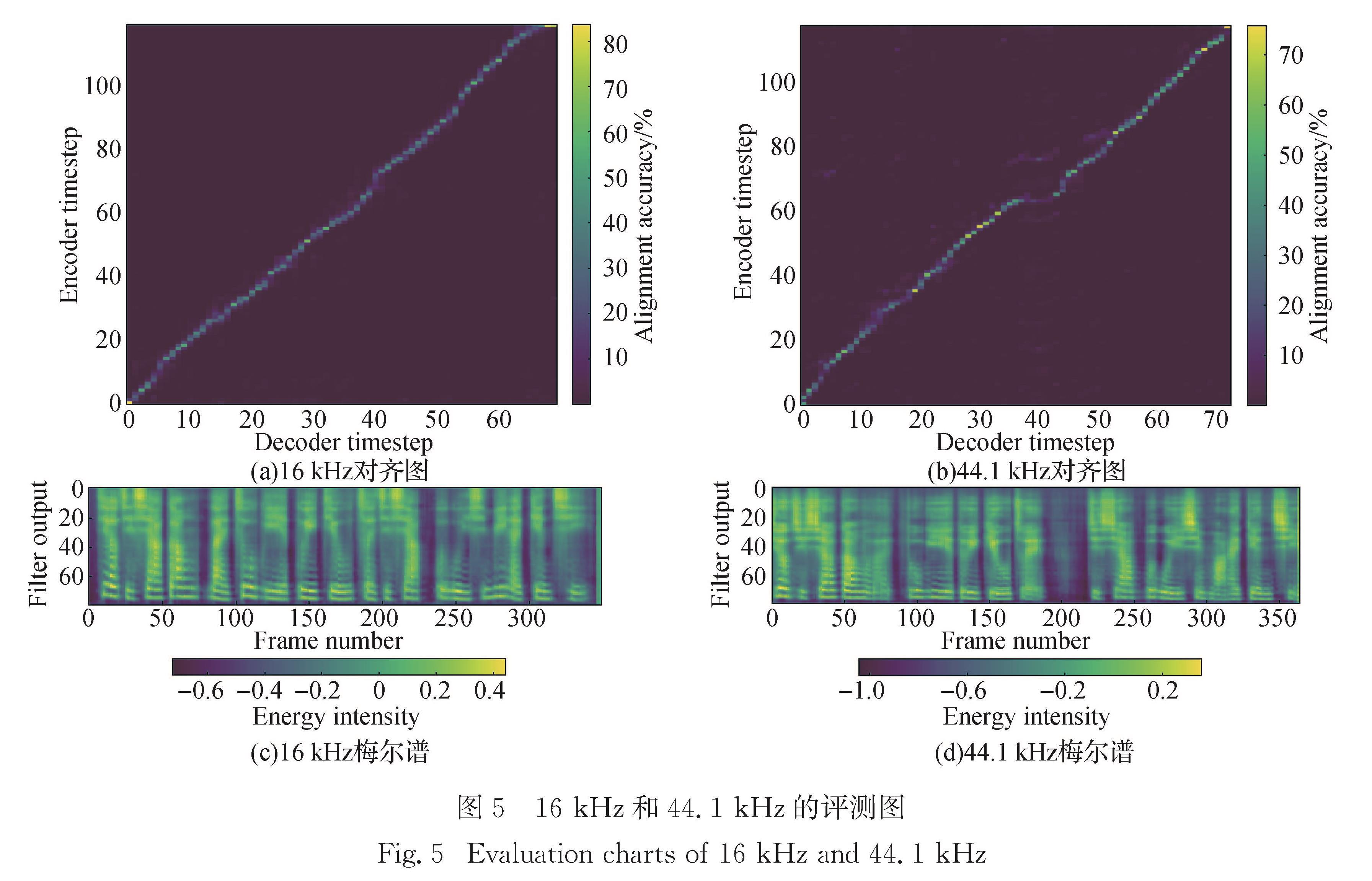
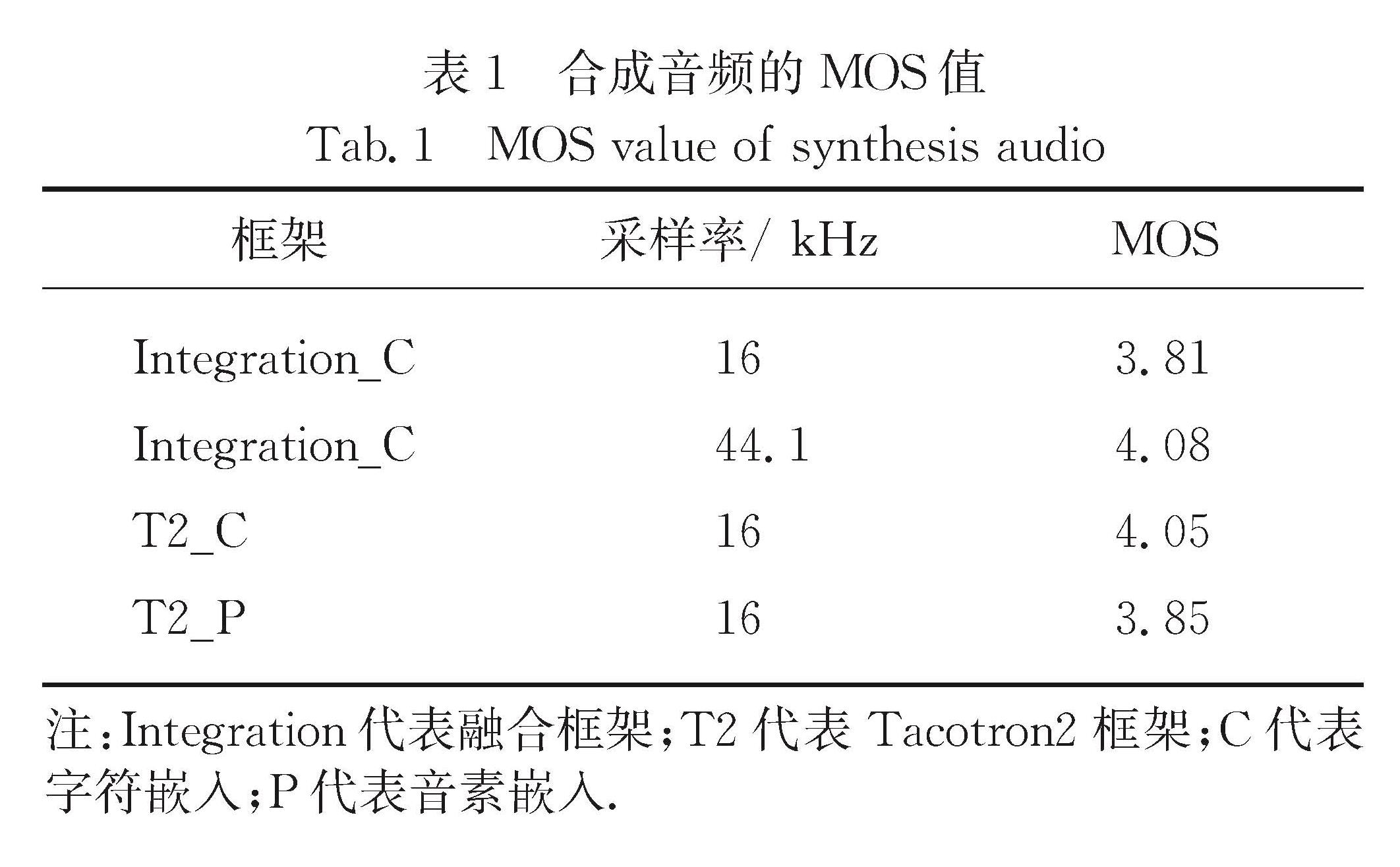
为了更好地研究语音合成在闽南语上的应用,建立了闽南语数据库,并验证了Tacotron2为有效的语音合成模型.数据库方面,建立起地方特色的闽南语词库和音素体系; 模型框架方面,在Tacotron和Tacotron2以及结合了两者不同模块的融合框架上进行实验对比.在厦门大学自主采集的厦门口音闽南语数据集的基础上,使用闽南语识别模型对语音数据进行解码得到对应的带有标点符号的音素序列,通过专业定制的词典建立音素标注体系,进行多组实验,比较采样率、建模方式和模型结构对合成音质以及稳定性的影响,通过梅尔谱和编码解码对齐图等评测标准,得到了三者的最佳搭配方案.
To better study the application of speech synthesis in Hokkien,we have established the database and verified that Tacotron2 is an effective speech synthesis model.For database,the establishment of a comprehensive and localized Hokkien vocabulary and phoneme system is adopted; for the model,in the model architecture of Tacotron and Tacotron2,the integration and optimization of the two models are explored,and the attention mechanism and other modules are optimized.On the data set of Xiamen pronunciation of Hokkien,the corresponding phoneme sequences with punctuation marks are decoded by Hokkien recognition model.A post-phoneme annotation system is established through a specially customized dictionary.A series of experiments are carried out to compare effects of sampling rate,modeling method and model structure on the synthesized phoneme quality and stability.Through Mel spectrum and alignment map of decoding and encoding,the best configuration is obtained.