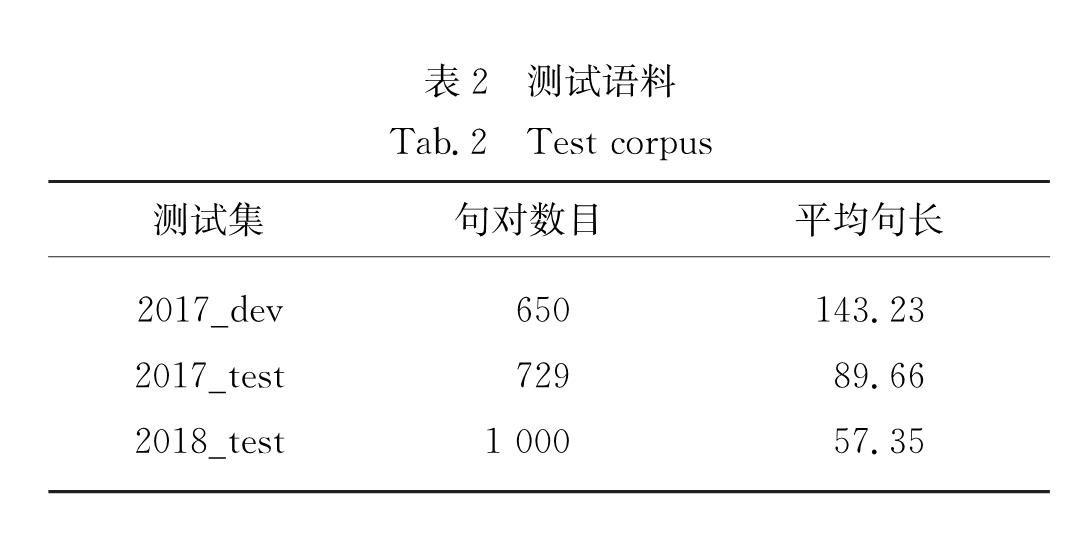
1.1 RNNSEARCH
大多数NMT系统都遵循Bahdanau等[4]提出的注意力机制的编码器-解码器框架.目标是将一种序列转换成另一种序列.基本思想为使用两个网络来处理翻译任务,分别为编码器和解码器,编码器将输入的序列转换成一个固定长度的内部表示向量,解码器则将该向量作为输入用以预测输出的序列.两个网络之间由内部表示向量连接.假设输入句子X={x1,x2,…,xTx},目标端输出句子为Y={y1,y2,…,yTy}.翻译过程实际上就是一个概率求解过程,具体计算形式为式(1):
P(Y|X; θ)=∏Tyj=1P(y< j,X; θ),(1)
其中,θ为参数,y<j为目标端生成词之前的所有词.因为X与Y并不等长,所以一般构造RNNSEARCH模型,即由两个RNN组成的编码器-解码器结构.编码器-解码器网络对源句的语义进行建模,并将源句转换为上下文向量表示形式,解码器从上下文向量表示形式中逐词生成目标词.NMT的一个重要特征是将词汇表中的每个单词映射成一个低维实值向量,连续表示法的使用让NMT能够学习潜在的双语映射,以进行准确翻译,并探索单词间的统计相似性.
1.1.1 编码器
通常的RNN计算式(1)时会从x1依次读取到xTx完成序列X的输入.但是,本研究希望每个单词的注释不仅总结前面的单词,而且总结后面的单词.因此编码器使用m个堆叠的LSTM层生成,隐层向量hkj(k=1,2,…,m),具体计算如下所示:
hkj=LSTM(hkj-1,hk-1j),(2)
其中如果k=1,则hk-1j=xj,xj为词xj的向量表示.
1.1.2 解码器
解码器根据yj上的上下文向量cj计算输出概率p(yj|y< j,X; θ),θ在不同的时间步长使用不同的上下文向量cj,最终yj的输出概率为
P(yj|y<j,X; θ)=softmax([tj-1
dj
cj]),(3)
其中,tj-1是j-1时刻目标词的嵌入,dj为j时刻编码器端的隐藏状态.其中dj的计算公式为
dj=LSTM(dj-1,[tj-1
cj]; θj-1).(4)
注意力机制将上下文向量cj计算为源注释的加权和:
cj=∑li=0αjihj.(5)
其中,hj=[h1j,h2j,…,hmj],注意力机制权重的计算式如下:
αji=(exp(eji))/(∑li=1exp(eji)),(6)
ej=vTatanh(Wadj-1+Uahkj),(7)
其中,va、Wa和Ua是注意力机制的权重矩阵, ej在注意力机制模型中能够平衡dj-1和hkj.使用这种策略,解码器可以处理在给定时间内最相关的源语句.
1.2 Transformer
Transformer模型[10]仅依赖于注意力机制,也采用了编码器-解码器架构,但其结构相比于注意力更加复杂,其中编码端由6个编码器堆叠在一起,解码端也一样.每个编码器包含两层:一个自注意力层和一个前馈神经网络,自注意力能帮助当前节点不仅仅只关注当前的词,从而能获得上下文的语义.每个解码器也包含编码器提到的两层网络,且在这两层中间还有一层注意力层,帮助当前节点获得当前需要关注的重点内容.
1.3 本文RNN模型
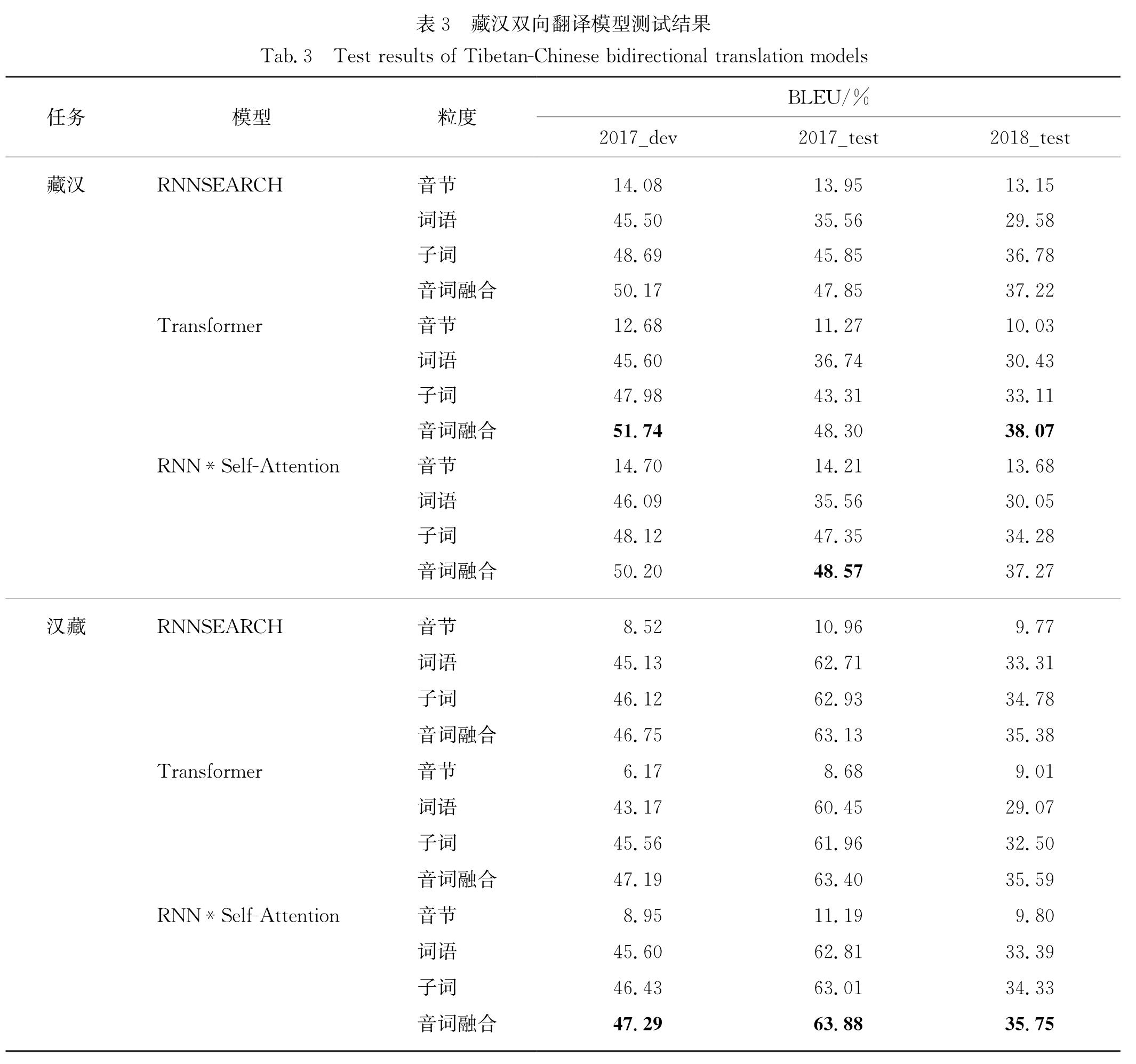
在通用序列建模中,自注意力是一种强有力的机制.本文提出的模型(RNN*Self-Attention)在RNNSEARCH的解码端引入Transformer中解码器的自注意力.解码器完全使用注意力机制不仅能够在不同的神经层之间传递信息,实现一个多层注意力机制的神经网络翻译模型,而且能更好地处理序列过长问题; 并且自注意力能够计算每一个词之间的注意力.捕获更多的原文信息.如图1所示:
混合多策略架构是一个层次结构序列到序列的模型,通过在不同的粒度级别即音节、词语、音词融合上进行训练作为对比实验.
图1 RNN*Self-Attention的编码器-解码器网络模型
Fig.1 Encoder-decoder network model of RNN*Self-Attention