收稿日期:2019-08-30录用日期:2019-12-19
基金项目:教育部人文社会科学研究青年基金(19YJC740107); 辽宁省重点研发计划(2019JH2/10100020)
通信作者:yena_1@126.com
基金项目:教育部人文社会科学研究青年基金(19YJC740107); 辽宁省重点研发计划(2019JH2/10100020)
通信作者:yena_1@126.com
(Human-Computer Intelligence Research Center,Shenyang Aerospace University,Shenyang 110136,China)
DOI: 10.6043/j.issn.0438-0479.201908032
与传统的机器译文评价方法不同,译文质量估计技术旨在无参考译文的情况下对机器译文质量进行评价.针对目前流行的基于深度学习的译文质量估计方法因数据匮乏和模型限制导致所提取的深度学习特征不充分的现状,提出一种多特征融合的方法.该方法将词预测特征、语境化词嵌入特征、依存句法特征和基线特征等从不同模型中提取到的特征分别输入到基于循环神经网络的下游模型中,进一步学习后采用不同的特征融合方式进行融合,以此来提高译文质量估计的准确性.通过对比实验表明,本文所提出的多特征融合策略相比于单个特征能更好地对双语信息进行表达,且进一步提高了译文质量估计的皮尔逊相关系数等评价指标.
Unlike traditional machine translation evaluation methods,translation quality estimation technique aims to evaluate the quality of machine translations without references.At present,the deep learning-based features extracted by translation quality estimation methods are not sufficient due to the lack of data and the limitation of models.Focusing on this problem,we propose a multi-feature fusion method.In this method,features extracted from different aspects such as word prediction features,contextualized word embedding features,dependent syntactic features and baseline features are input to the downstream model based on the recurrent neural network.Then different strategies are adopted to combine these features.Comparative experiments show that the proposed method can better express the bilingual information compared with the single-feature method,and can improve the Pearson correlation coefficient as well as other evaluation metrics of sentence-level translation quality estimation.
机器译文质量通常根据参考译文计算双语互译评估(BLEU)值进行评价,但参考译文需预先提供且在多数情况下不易获取,因此在实际应用中以BLEU值为评价指标有时并不现实.译文质量估计技术便是在无参考译文的情况下对机器译文的质量进行评价,其中句子级质量估计任务可对每个句子的整体翻译质量进行评分,因此相较于词级译文质量估计任务,句子级研究更具有重要现实意义.
大量人工设计的浅层双语特征在早期的译文质量估计研究中扮演着重要角色,主要抽取的特征包括基线特征[1]、语言学特征[2]和从流畅度、忠实度、复杂度等角度提取的反映译文质量的特征[3].但由于特征数量较多,且存在一定的重叠,因此一些研究通过特征选择算法(如最小二乘法[4]、高斯过程[5]等)对特征进行选择后,再利用传统机器学习方法学习特征与译文质量之间的映射函数对译文质量进行估计.常用的机器学习方法包括逻辑回归[6]、条件随机场[4]、支持向量回归[1]等.
随着深度学习的发展,人们开始将神经网络用于译文质量估计,通过采用基于神经网络端到端的模型架构对源语言和机器译文进行深层特征提取[7-11],改变了传统人工设计的特征所包含的双语信息层次较浅且依赖于语言种类而导致通用性不佳的状况.这些对深度学习特征的研究多集中于进行有效的语言表示.在词级译文质量估计任务中,Kreutzer等[7]基于神经网络模型,提出了一种基于上下文窗口的双语表示学习方法,首先从目标词上下文提取一个固定大小的单词窗口,将其与对应同样大小的源语言词窗口进行拼接后作为双语序列输入,再用word2vec[12]训练词向量初始化查找表,将窗口内每一个词对应的向量进行拼接,通过下游前馈神经网络进一步学习双语表示,最后输出译文质量估计标签.但当语料较为匮乏时,深层特征提取在训练过程中易产生过拟合.为解决这一问题,研究人员提出引入预训练词向量的方法,该方法能够减少模型中训练参数的数量,有效缓解过拟合现象的发生.Patel等[8]在Kreutzer等[7]研究的基础上提出了一种基于循环神经网络(RNN)的译文质量估计方法,将窗口内的目标译文序列和源语言序列拼接后一起输入到RNN中; 同时引入了预训练词向量以及均衡化标签分布策略,证实了这两种策略在基于RNN的词级和短语级译文质量估计任务中的有效性.以上这两种方法均基于上下文窗口,而窗口的获取依赖于统计机器翻译(SMT)中的词对齐技术,且这种将固定长度的双语序列作为输入的方法在学习双语上下文信息时受限于窗口大小,无法学习到双语句子中的全局信息.
为了突破窗口大小的限制,学习双语序列中更为全面的信息,Kim等[9]提出一种完全神经化的译文质量估计模型,该模型由词预测和质量估计两部分组成,其中词预测模型在基于RNN的编码器-解码器框架基础上引入反向解码思想,从中抽取质量信息并以质量向量的形式输入到下游模块进行译文质量估计.该方法打破了传统神经机器翻语(NMT)译文质量估计方法依赖于窗口而不完全神经化的状况,同时由于模型由大规模平行语料进行训练并使用译文质量估计数据进行调整,有效缓解了由于训练数据较少所带来的影响.除此之外,孙潇等[10]针对句子级任务提出了一种融合机器翻译知识的新方法,利用大规模平行语料训练了两个方向相反的NMT模型,将两个模型中的编码器编码得到的向量作为质量估计特征,并与17个基线特征结合,进一步预测译文质量.但是此方法仅通过两个编码器提取特征而并未从解码器中提取更多信息.Fan等[11]提出“双语专家”模型,该模型利用完全基于注意力的Transformer[13]架构进行译文质量特征提取,除利用模型计算图中其本身的模型特征以外,研究人员还设计了一种4维的错误匹配特征用于直接衡量“双语专家”模型所学习到的先验知识与翻译输出之间的差异.该方法在2018年机器翻译研讨会(WMT)译文质量估计评测任务中达到了最佳效果.与上述从机器翻译模型中提取质量信息的方法不同,陈志明等[14]从语言模型入手,在句子级任务中提出了一种基于神经网络特征的译文质量估计方法,通过从不同语言表示模型提取词嵌入,同时采用算术平均、加权平均、最小值等不同方法进一步合成句子嵌入特征,并将该特征与RNN特征相结合,进一步提高了句子级译文质量自动估计与人工评分之间的相关性.其分别采用连续词袋(CBOW)模型[12]、矩阵分解(Glove)模型[15]和连续空间模型(CSLM)[16]训练词向量,但受训练词向量所采用的语言模型的限制,在编码单词信息时不能充分将上下文词之间的位置关系进行有效表达,使得该词向量无法携带较为全面的上下文信息.
综上分析,基于深度学习的译文质量估计任务主要涉及两类深层特征:预训练的词嵌入特征和特定模型提取的神经网络特征.因此从特征方面入手,本研究另外引入两类特征:1)提出加入预训练的语境化词嵌入作为一种深层特征来代替传统词嵌入,利用该特征强大的表义能力,改进过去采用传统词嵌入而导致的上下文信息携带不足问题.2)为了更好地学习双语句对句法之间的相关联系,显性地引入了依存句法特征.然后,通过不同的特征融合方式将以上两种特征与语境化词嵌入、其他模型所提取的深度学习特征以及基线特征进行融合,以达到语义与句法结构信息增强表示的效果.
根据上文分析,Kim等[9]在NMT模型的基础上构建词预测模型用于提取源语言和机器译文信息可有效表示译文翻译质量,因此本文中将其作为译文质量特征用于下游的质量估计阶段.
基于RNN的词预测模型在已知源语言和目标语言的情况下,随机选择目标语言中的一个词对其进行遮蔽,并根据源语言和目标语言上下文对该词进行恢复.本文中采用Bahdanau等[17]提出的基于注意力机制的双向RNN的编码器-解码器框架.在编码器模块将源语言信息通过双向RNN进行编码,得到基于注意力机制的源语言句向量信息cj.解码器在Bahdanau等[17]的模型基础上引入反向RNN解码结构,用来进一步学习目标词的下文信息.词预测特征的提取过程如图1所示.
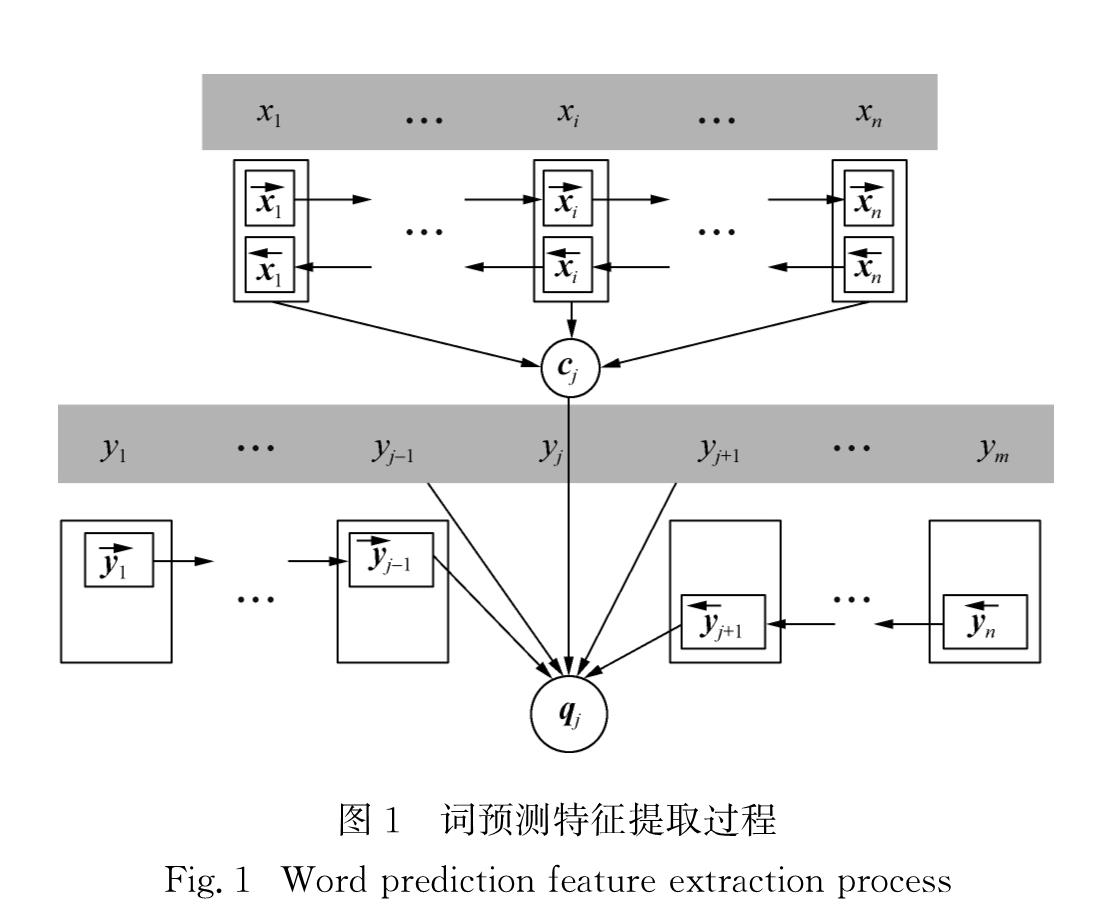
图1 词预测特征提取过程
Fig.1 Word prediction feature extraction process
由图1可知,根据源语言信息x和目标词上下文y1,…,yj-1,yj+1,…,yKy,预测目标词yj的概率为
p(yj|y1,…,yj-1,yj+1,…,yKy,x)=
g([s→j-1; s←j+1],[yj-1; yj+1],cj)=
exp(yТjWotj)[∑Kyk=1exp(yTkWotj)]-1,
其中:g是一个利用[s→j-1; s←j+1]、[yj-1; yj+1]和cj来预测目标词yj概率的非线性函数,[s→j-1; s←j+1]是s→j-1和s←j+1的拼接,s→j-1和s←j+1分别是前向RNN和后向RNN在目标句中的隐含状态,yj是目标词yj的独热(one-hot)向量; Ky是目标语言词汇表大小,Wo是权重矩阵,tj为中间表示,计算式如下:
tj=(max(t~j,2k-1,t~j,2k)),k=1,2,…,l,
t~j=So[s→j-1; s←j+1]+Vo[Eyjyj-1; Eyjyj+1]+
Uocj.
其中,So、Vo、Uo均为权重矩阵,Eyj是目标词的词嵌入向量,l是中间输出向量维数.由于yj的预测概率中包含了关于目标词是否正确地从源语句中翻译过来的质量信息,因此从中提取qj作为双语特征.
qj=[(yТjWo)⊙tТj]Т,
其中,⊙表示逐元素相乘.本研究将[q1,q2,…,qKy]作为词预测特征.
自然语言处理任务所研究的基本单元之一是词,如何对词进行有效的向量表示对下游任务有着极其重要的影响.近年来的研究表明,预训练的语言表示模型能够更好地对文本进行表征并用于下游任务.另外,因为传统的预训练表示模型仅为词汇表中每一个单词生成一个固定的向量,而语境化的词嵌入模型则在整个句子上运行一个经预训练的编码器网络,从而动态地为每个词提供一个基于上下文的向量表示; 所以语境化的词嵌入的预训练语言表示模型比传统的预训练语言表示模型对序列的上下文信息更为敏感.
本研究采用目前效果较优且讨论广泛的基于Transformer的双向编码表示(BERT)模型[18]作为提取语境化词嵌入特征vi的模型,如图2所示.BERT作为一种双向语言模型结构,使用双向Transformer作为编码器,其中的自注意力操作将句子中每个词的位置信息进行编码融入,同时引入了遮蔽机制从而利用输入语言的上下文信息.由于BERT允许将多个文本同时输入,因此本研究同时对源语言和机器输出译文进行编码,得到双
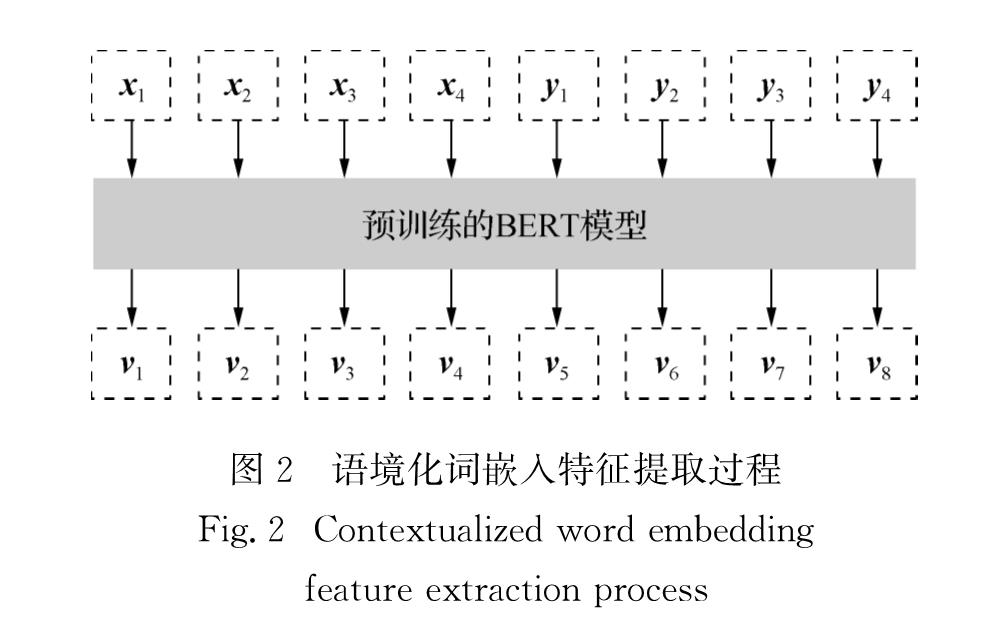
图2 语境化词嵌入特征提取过程
Fig.2 Contextualized word embedding feature extraction process
语词嵌入并将其进行拼接作为语境化词嵌入特征.
本文中BERT模型是在大规模语料上训练得到的,因其模型结构设置使所得词嵌入向量携带更多的语义及结构信息,同时有效缓解了歧义、多义词等问题,所以该模型提取的语境化词嵌入特征能够更好地辅助其他特征增强双语表示.
本文中还将依存句法信息显性地融入到译文质量估计任务中以更好地学习源语言和机器译文之间的句法结构关系.依存句法蕴含了句子中词与词之间的依赖以及被依赖关系,其中中心词体现了主要语法和语义信息,而修饰词在语义上从属于中心词,同时起到修饰以及对中心词信息进行补充的作用.将依存句法信息与其他任务相结合的传统做法是将依存句法分析中的依存关系融入到具体任务中,但为了使双语句对与显性添加的依存句法信息之间的关联表达更为紧密,本研究选择从双语句对中抽取能够蕴含依存句法信息的有效内容,将句子中每个词语所对应的中心词作为其句法标签进行建模.
本研究采用广泛使用的句法分析工具Stanford Parser(https:∥nlp.stanford.edu/software/lex-parser.shtml)对源语言和机器译文均进行句法分析,并将两个句子的中心词信息进行拼接得到依存句法特征向量[pS1,pS2,…,pSm; pT1,pT2,…,pTn].这里pSi为源语句中的中心词Si对应的信息的向量表示,pTj为机器译文中的中心词Tj对应的信息的向量表示.
除由神经网络提取的连续稠密的特征外,WMT官方提供了由人工抽取的17个双语特征:
1)源语句的词数; 2)机器译文的词数; 3)源语句中词的平均长度; 4)源语言的语言模型概率; 5)机器译文的语言模型概率; 6)目标句各个目标词出现的次数的平均值; 7)源语言中每个词对应译文词数的平均值(采用IBM 1模型,阈值即源词x翻译成目标词y的概率p(y|x)>0.2); 8)源语言中每个词对应译文词数的加权平均值,权重为源语言词表里的每个单词的逆频率(采用IBM 1模型,阈值prob(y|x)>0.01); 9)源语言词占源语言训练语料中频率四分位数1(频率较低的单词)的百分比; 10)源语言词占源语言训练语料中频率四分位数4(频率较高的单词)的百分比; 11)源语言中的二元组占源语言训练语料中频率四分位数1的百分比; 12)源语言中的二元组占源语言训练语料中频率四分位数4的百分比; 13)源语言中的三元组占源语言训练语料中频率四分位数1的百分比; 14)源语言中的三元组占源语言训练语料中频率四分位数4的百分比; 15)SMT训练语料库中看到的源语句中的一元组百分比; 16)源语句中的标点符号数; 17)机器译文中的标点符号数.
这些特征虽然仅涉及双语句对的表层特征,但相比于神经网络抽取的高维向量特征更直观且解释性更强,因此本研究将这些特征与其他深度学习特征相结合,一同对双语信息进行更深入全面的表示.
在本研究提出的多特征融合的译文质量估计模型的整体架构如图3所示.首先采用第1节所述方法从源语言和目标语言中提取出表示语境化词嵌入特征、依存句法特征、词预测特征的高维向量; 再将这3种特征分别输入3个双向长短时记忆(Bi-LSTM)网络,得到经Bi-LSTM编码后的最后一个隐状态HB、HS和HW; 对这3个隐状态和其他特征进行特征融合后通过Sigmoid函数求取译文质量分数.其中,其他特征均为数值型表示,由WMT官方提供.由于所采用的特征提取模型不同,使得各个特征在向量维度上存在较大差异,为了不使特征HB、HS、HW分别表示语境化词嵌入特征隐状态、
依存句法特征隐状态和词预测特征隐状态.
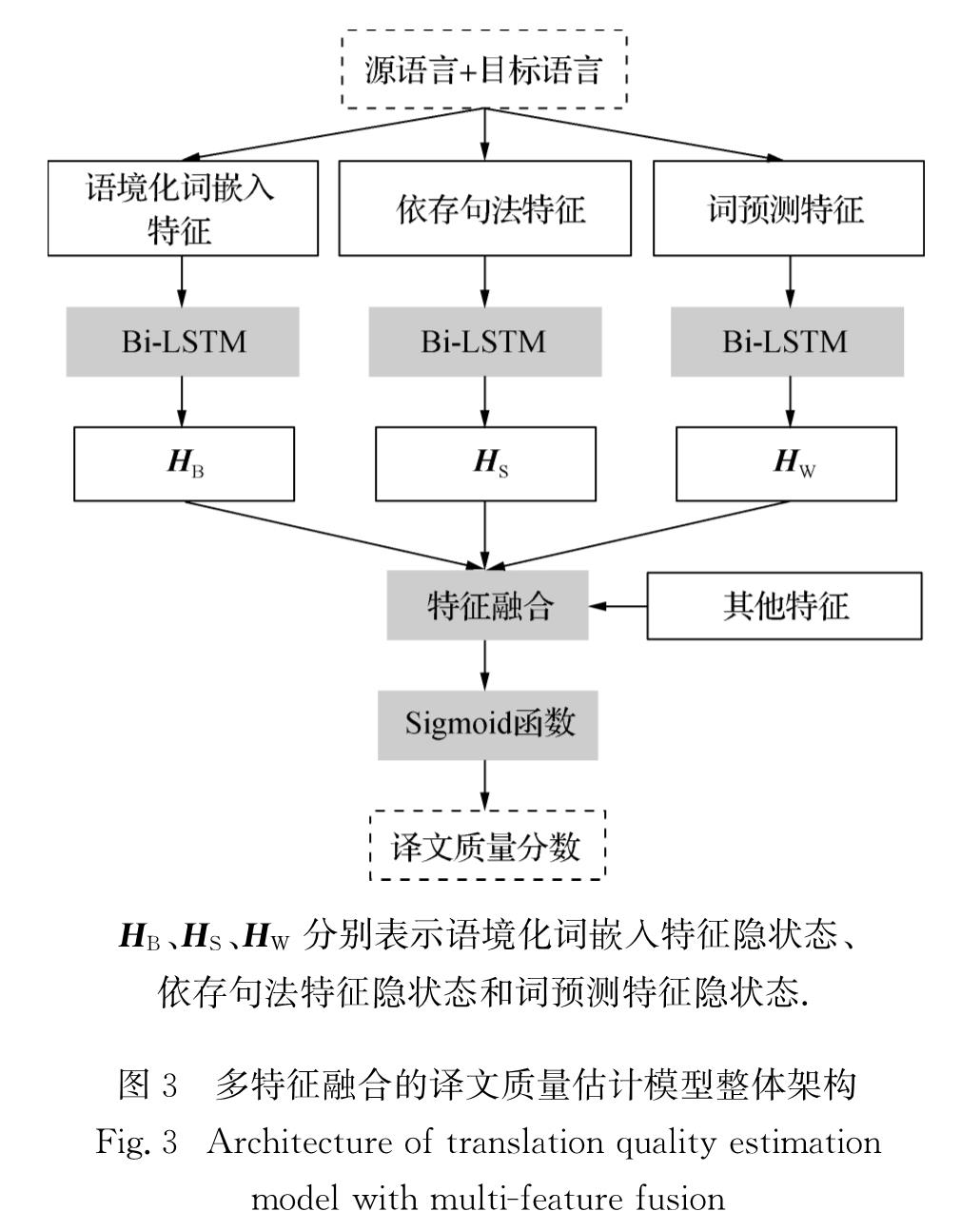
图3 多特征融合的译文质量估计模型整体架构
Fig.3 Architecture of translation quality estimation model with multi-feature fusion
信息因维度转换、变形等策略而缺失或修改,因此与传统的将特征在前期就进行向量化拼接融合再用于后续模型计算的方式不同,本研究采用后期融合的方法将各个特征分别输入到基于双向RNN的译文质量估计模型中进一步学习后,再融合各个最终得到的隐藏状态作为最终双语信息表征向量,进而用于译文质量估计分数的计算.
因为RNN能够将当前时刻之前的信息进行记忆并用于当前时刻计算,在处理序列问题方面具有较强的优越性,故本研究以RNN为基础构建模型.同时由于语境化词嵌入特征和依存句法特征是通过将源语言和目标语言序列同时输入到各特征提取模块得到的,导致部分特征序列较长,因此为了更好的编码学习长序列特征的内部信息,本研究采用RNN的变体——长短时记忆(LSTM)网络[19]作为基本的网络单元编码各个特征序列内部之间的联系.LSTM与普通RNN相比,最大的改进在于在神经元中引入了输入门、输出门和遗忘门,由于这3种门的引入,使得网络计算相比于普通RNN变得更为复杂.本研究用3个Bi-LSTM分别提取词预测特征、语境化的词嵌入特征和依存句法特征.每一个Bi-LSTM层中各门控单元的计算如下式所示:
ft=σ(Wf·[ht-1,xt]+bf),
it=σ(Wi·[ht-1,xt]+bi),
ot=σ(Wo·[ht-1,xt]+bo),
其中,ft、it、ot分别表示t时刻的遗忘门、输入门、输出门向量,σ为激活函数,W和b分别表示权重与偏置向量,ht-1和xt分别表示t-1时刻的隐状态和t时刻输入.训练过程中各个Bi-LSTM网络层设置相同的超参,各个特征在训练过程中分别学习互不影响.
在特征的融合阶段,针对特征向量采用了两种不同的融合方式.
1)将各特征由Bi-LSTM层编码后的HB、HS和HW直接相加.但是为了避免相加后的融合向量的模过大,因此采用对该向量取均值,即算术平均的策略.该策略默认每一个特征的重要程度都相同,即给每一个特征设置固定权重,即
H1=(HB+HS+HW)/3.
2)将各个向量按维度拼接.该方式未修改各个特征的任何维度内容,使得每一个特征所携带的信息得到充分表达.其融合特征向量为:
H2=[HB; HS; HW].
本研究在以上两种融合方式中未添加新的网络层,而是采用直接将各个特征进行融合的方法,没有增加模型参数,因此未对模型的训练速度造成影响.
由于方法1)未对各特征的重要程度加以区分,本研究还通过另外添加一层全连接层,用神经网络自动学习最佳权重,分析各个特征的重要程度对模型结果的影响,但是该方法在实验过程中易陷入局部最优,使得最终权重学习效果相对低于取均值的方法,因此在后续实验中仅对使用相同权重的融合方法进行分析.
最后分别将两种方式所得到的特征融合向量与其他17个基线特征Ho进行拼接,作为最终的特征融合向量,由于该部分基线特征是由各双语句对所抽取出的17个浮点数,因此拼接融合方式未对训练负担造成影响.拼接方式如下:
H=[Hi; Ho],(i=1,2).
本研究主要针对德-英译文质量估计任务,即对英文机器译文的质量进行估计.实验所使用的语料包括两部分:1)是训练词预测模型的大规模双语句对,该语料来源于WMT机器翻译任务发布的平行语料库,语料包括Europarl v7、Common Crawl corpus、News Commentary v11等.为了提高实验性能,本研究对语料进行了过滤,剔除过长与过短句对,以及双语句长比值超过一定阈值的句对; 2)质量估计数据来自WMT'2017 的质量估计任务.表1给出了实验所采用语料的具体数量信息.
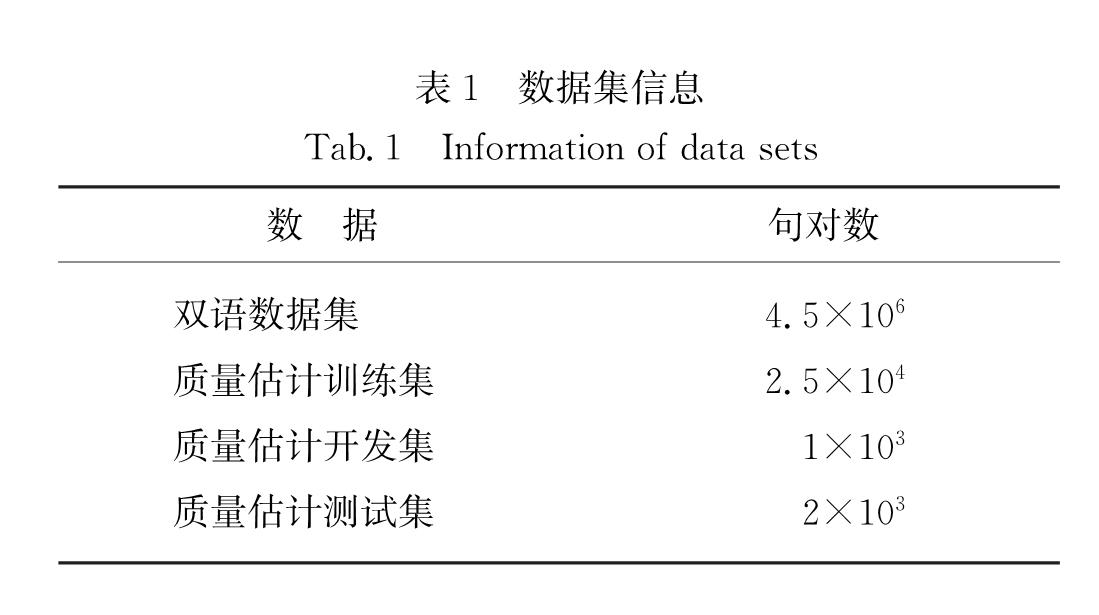
表1 数据集信息
Tab.1 Information of data sets
句子级译文质量估计任务在句子层面上对整体翻译质量进行评价,即对机器译文整体质量进行评分,其本质是计算机器译文与经人工编辑后的后编辑译文之间的最小编辑距离HTER(human-targeted translation edit rate)的值RHTE[20],它是对TER(translation edit rate)的改进,由下式给出:
RHTE=(ninserts+ndels+nsubs+nshifts)/n,
其中,ninserts、ndels、nsubs和nshifts分别表示人工将机器译文修改成正确译文所需要插入、删除、替换、移动单词的最少次数,n表示正确译文中的单词数量.
而为了评价译文质量估计系统的性能,一般使用皮尔逊相关系数r、斯皮尔曼相关系数ρ、平均绝对误差(MAE)和均方误差(RMSE)等4个评价指标,其中皮尔逊相关系数作为最主要的指标用来反映机器自动评价分数与人工评价分数之间的线性相关性,可由下式计算得出:
r=(∑Ni=1(Pi-P^-)(Hi-H^-))/((∑Ni=1(Pi-P^-)2∑Ni=1(Hi-H^-)2)1/2).
其中,N表示用于测试的机器译文总数量,Pi和Hi分别表示第i个机器译文的系统自动估计分数和人工评价分数,P^-和H^-分别表示N个机器译文平均系统打分和平均人工打分.皮尔逊相关系数越高,表明系统打分与人工评价分数越接近,系统效果越好.
皮尔逊相关系数主要反映两种评分之间是否线性相关,同时为了反映两种评分向量单调性是否一致,斯皮尔曼相关系数被用来评价机器自动估计分值排名与人工评价分数排名之间的排名相关性,可由下式计算得到:
ρ=1-(6∑Ni=1d2i)/(N(N2-1)).
其中,di表示第i个机器译文的系统预测分值排名与人工打分排名之间的差值.该值越高,说明机器预测分值排名与人工评分排名越相关,则系统效果越好.
MAE和RMSE作为辅助评价指标,与上述两种评价指标不同,其分值越低则表明系统性能越好.
为了对比3.3节中提出的两种不同融合策略对多特征融合的译文质量估计系统性能的影响,本研究在融合上述所有特征的系统上做了一组对比实验,结果如表3所示.
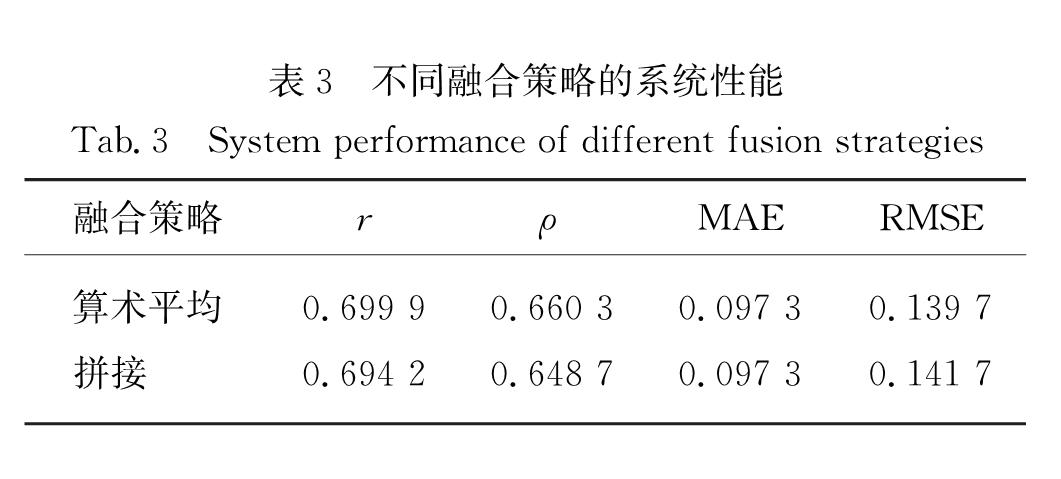
表3 不同融合策略的系统性能
Tab.3 System performance of different fusion strategies
由表3可知拼接方式的融合策略效果略低于算数平均融合策略,这可能是拼接融合方式下各向量中所携带的隐含特征种类存在重合而导致拼接后的向量出现特征冗余,而算术平均方式则是在隐含特征种类不变的情况下增加了其中各个隐含特征所携带的信息量,因此特征信息量的增加使得特征融合效果更为理想.故在下文中仅对效果较好的算术平均融合方式的系统性能进行对比分析.
为了比较单个特征以及不同的特征组合对译文质量估计效果的影响,本研究在控制变量的条件下进行了多组对比实验,并根据实验结果分析了各个特征对整体性能的影响,以及不同特征组合所带来的效果差异.表4中W-P、B-F和S-F分别表示仅使用词预测特征、语境化词嵌入特征和依存句法特征的系统; +表示特征融合; QEBrain(single)表示双语专家模型在该数据集上所得到的结果; POSTECH(single)表示Kim等[21]采用预测器-估计器单模型系统所得实验结果,将其与本研究的实验结果进行对比.另外,需要说明的是,仅使用词预测特征的模型与POSTECH(single)模型在训练过程中存在一定的差异,POSTECH(single)模型为了共同学习预测器和估计器两个子模型而采用了堆栈传播方法,该方法将训练误差从估计器到预测器进行反向传播.在本文中将预测器的输出作为一种词预测特征,因此在训练过程中并未采用堆栈传播算法对整体模型进行联合学习.
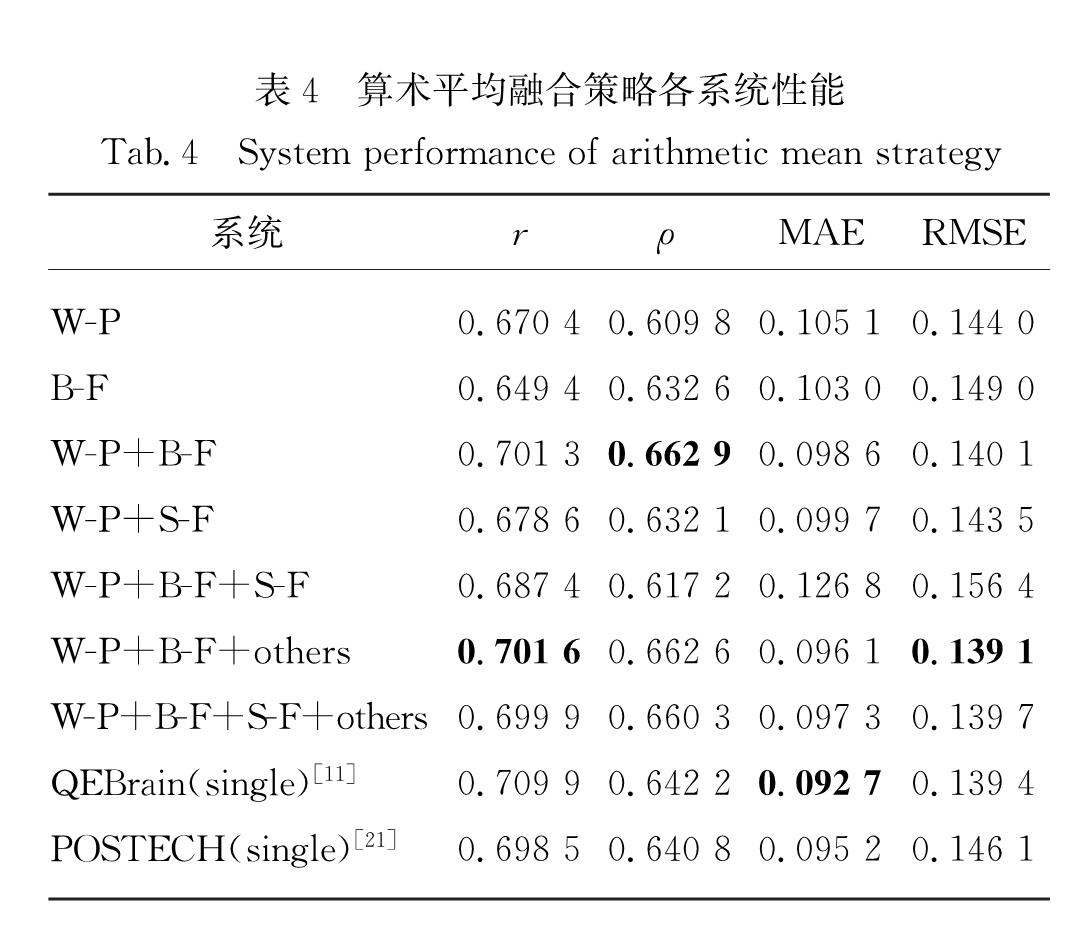
表4 算术平均融合策略各系统性能
Tab.4 System performance of arithmetic mean strategy
由表4可知,本研究提出的多特征融合的句子级译文质量估计系统相比于POSTECH(single)系统表现出更好的准确性.通过具体分析发现:仅使用词预测特征和语境化词嵌入特征均可得到可接受的结果,其中仅使用词预测特征的系统在皮尔逊相关系数指标上优于仅使用语境化词嵌入特征的系统,但是仅使用词预测特征的系统性能在斯皮尔曼相关系数指标上较低; 而两种特征的融合(W-P+B-F)系统能够进一步提高两种指标的分值,说明词预测特征与语境化的词嵌入特征在一定程度上所携带的信息存在互补关系且对彼此有促进作用,因此语境化的词嵌入特征可作为译文质量估计任务的一个极其重要且值得更深入研究的特征.
另外由W-P+S-F系统与W-P系统的结果对比可知,双语依存句法特征能够在一定程度上辅助词预测特征进行译文质量估计.而W-P+B-F+others系统与W-P+B-F系统的结果表明17个基线特征也能够进一步提高译文质量估计的准确性,但是依存句法特征与17个基线特征对译文质量估计的效果的提高幅度均不大.我们猜想由于依存句法特征在输入到Bi-LSTM中时仅经过词嵌入层进行学习,学习效果并不理想,而基线特征则因存在维度较小问题,在与其他高维特征进行融合时,耦合效果不佳.
值得注意的是,所有特征进行融合并不能得到最好的效果,我们猜想可能是因为BERT模型的训练是在大规模无标注语料上进行的,且其模型内部的自注意力机制通过编码句子的位置信息能够较好地学习句子的语义和词与词之间的结构信息,得到的词嵌入特征已经可以较为全面的表示句子内部的句法结构,将其与提取的依存句法特征再进行融合,可能会因特征冗余等问题导致融合效果较差,反而对结果产生不利影响.针对此猜想,本研究将W-P+B-F+S-F系统与W-P+B-F系统进行对比,从结果可看出,W-P+B-F+S-F系统的译文质量估计效果低于W-P+B-F系统,该结果从一定程度上证明了上述猜想,但BERT模型是否确实在句法信息的学习能力上有一定的优势,需根据其他任务进行更多对比实验以进一步验证.
在句子级译文质量估计任务中,本研究从增强双语信息的语义及结构表征入手,针对目前基于神经网络的译文质量估计任务采用的预训练的词嵌入无法有效利用上下文信息,且未显性融入依存句法信息,使得神经译文质量估计系统提取的深层特征对双语信息表达不够充分的现状,提出了一种多特征融合的译文质量估计方法.实验结果表明,该方法能够更好地对双语信息进行表征,提高了句子级译文质量估计任务中机器自动评分与人工评分之间的相关性.
但是该方法存在的问题是,所抽取的语境化词嵌入特征受限制于训练好的BERT模型,而BERT模型对输入句长有限制,允许输入的最长限制是512个单位,虽然本文中所研究的句子级译文质量估计任务极少存在超出最长限制的句子,但是在译文质量估计的另一个子任务即篇章级任务中,源语言和目标译文普遍偏长,导致输入长度可能会超出最长输入限制,使得语境化词嵌入特征在篇章级任务中或许不能发挥其重要作用.因此在接下来的研究中,将据此状况寻求较为通用的解决办法,并构建更优越的特征提取模型,在此基础上进一步分析提取出的各种特征在语义和句法结构等方面的具体作用以及作用程度,并尝试其他特征融合方式以更好地提高译文质量估计的准确性.