聚类分析旨在发现相似样本组成的类簇,是模式识别研究的热点方向之一.随着科学技术的快速发展,数据收集变得更容易,产生了更大、更复杂的数据集.许多基于欧式距离的传统聚类算法容易受到高维数据多噪声、非线性的影响,从而影响聚类的准确性.因此,研究高维数据聚类具有重要意义.
子空间聚类是近年来聚类问题研究的热点之一.子空间聚类旨在根据某些特定的相似性度量和分组规则,对样本进行分组形成不同的类簇.在不同的子空间聚类方法中,谱聚类是研究高维数据聚类的重要分支.谱聚类算法中的一个关键步骤是构造“好”的相似矩阵.2009年,Wright等[1]提出用于人脸识别的稀疏表示(SR)分类法,SR基于线性表示揭示了数据之间的线性关系,并将获得的表示系数应用于分类,使人脸识别研究取得了新进展.从此基于线性表示的子空间聚类方法得到了快速发展.
由于SR通常揭示单个点与其他点之间的线性关系,Elhamifar等[2]提出了稀疏子空间聚类(SSC),该方法使用SR系数构造数据相似矩阵.Liu等[3]提出了低秩表示(LRR)子空间聚类,旨在获得低秩表示矩阵,并揭示数据的全局信息.Lu等[4]提出了最小二乘回归(LSR)子空间聚类,可将高度相关的数据聚合在一起,并且对噪声的识别具有鲁棒性.与其他算法相比,LSR更简单、更高效,因此许多LSR的扩展模型被相继提出.Lu等[5]利用相关熵改进LSR,该方法对非高斯噪声的识别具有鲁棒性,能更好地识别离群数据.简彩仁等[6]将降维思想融入到子空间聚类,提出投影LSR,通过去除冗余,提高聚类准确率.Cao等[7]将图像本身的局部纹理特征作为先验知识改进LSR,该方法可以更精确地检测织物疵点.这些基于表示理论的算法可以概括为求解表示矩阵,再用表示矩阵定义相似矩阵; 但是这些方法均假设数据相对于彼此可以线性表示,然而现实中的数据关系通常表现出高度非线性,因此会降低上述算法的聚类性能.针对这一不足,赵剑等[8]通过数据局部相关约束改进LSR,获得块对角性质更明显的表示矩阵,进而提高聚类准确率; 简彩仁等[9]提出核LSR(KLSR),利用核理论使其更适合高维数据的聚类.还有许多研究是针对正则惩罚项改进的子空间聚类模型,可以参考相关综述研究[10-11].
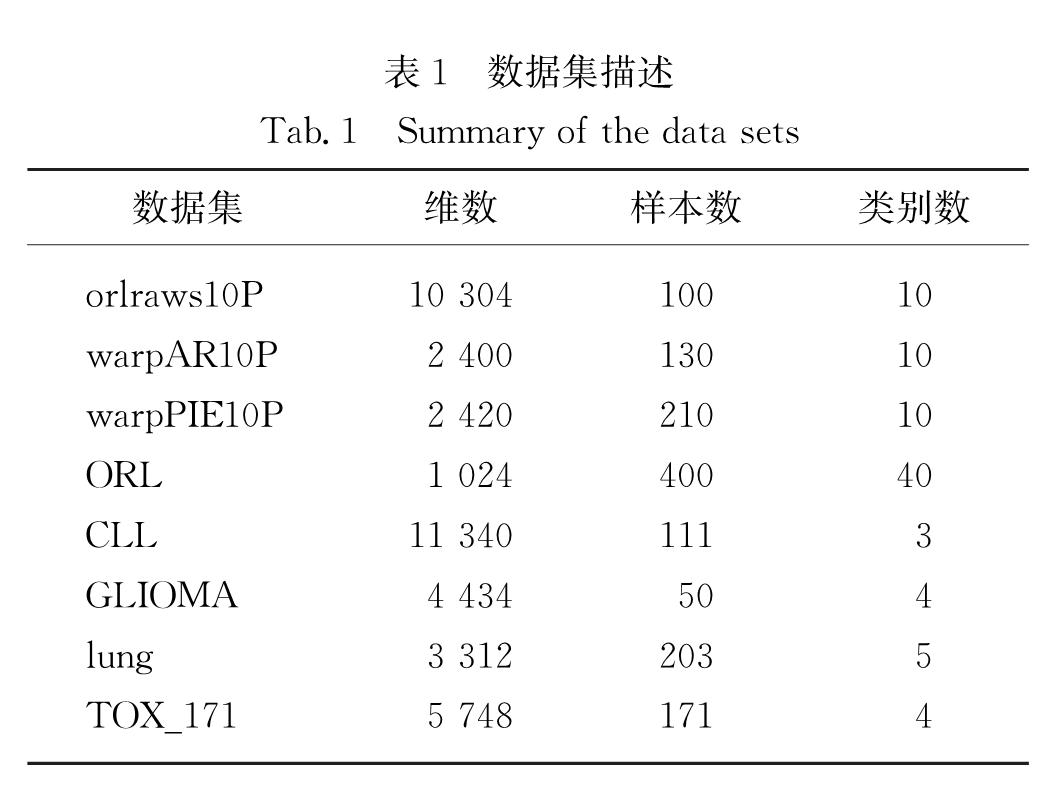
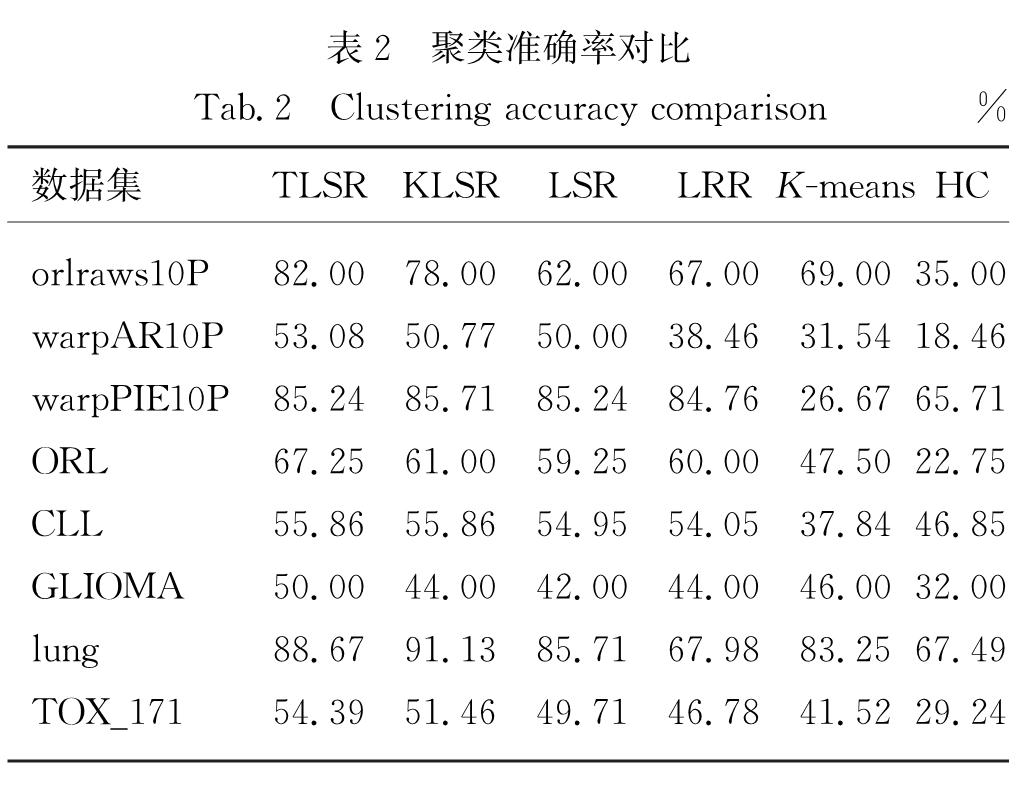
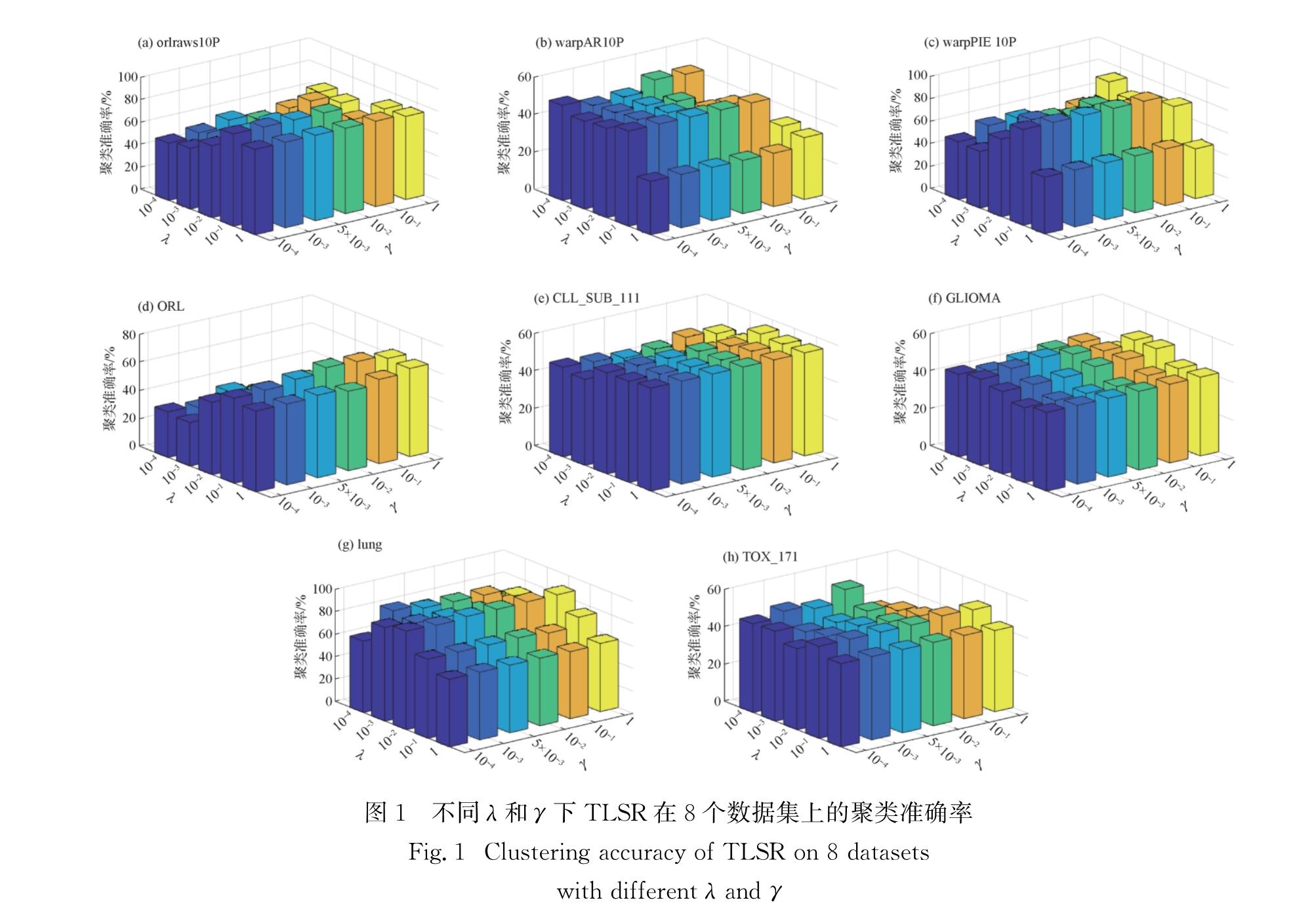
Roweis等[12]提出了著名的局部线性嵌入(LLE),该方法的结果表明数据的局部信息可以提高识别的准确率.因此考虑数据的局部特性,可以在一定程度上克服高维数据的非线性特性.基于此,本研究提出两阶段LSR(TLSR)方法:第一阶段利用LSR方法获得表示系数,利用表示系数刻画近邻关系,获得数据集的局部约束信息; 第二阶段利用第一阶段的局部信息,提出局部约束LSR模型,求得表示矩阵.最后利用表示矩阵定义相似矩阵,并用谱聚类完成高维数据的聚类.