收稿日期:2016-08-08 录用日期:2016-12-09
基金项目:福建省科技厅对外合作项目(2017I1009); 福建省软件学项目(2015R0083)
通信作者:csx@xmut.edu.cn
基金项目:福建省科技厅对外合作项目(2017I1009); 福建省软件学项目(2015R0083)
通信作者:csx@xmut.edu.cn
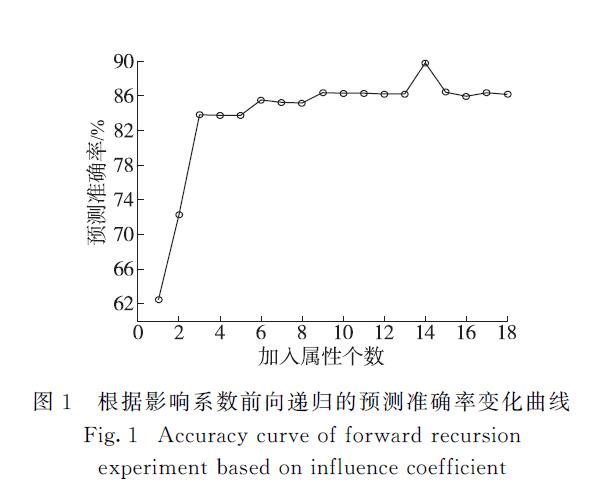
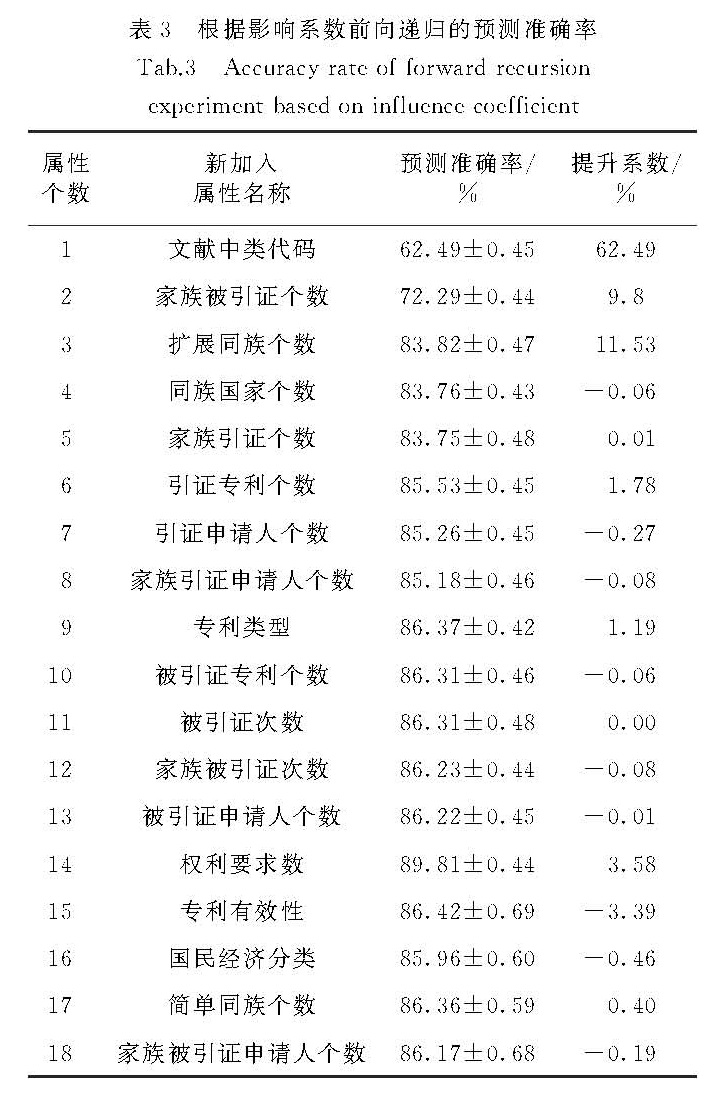
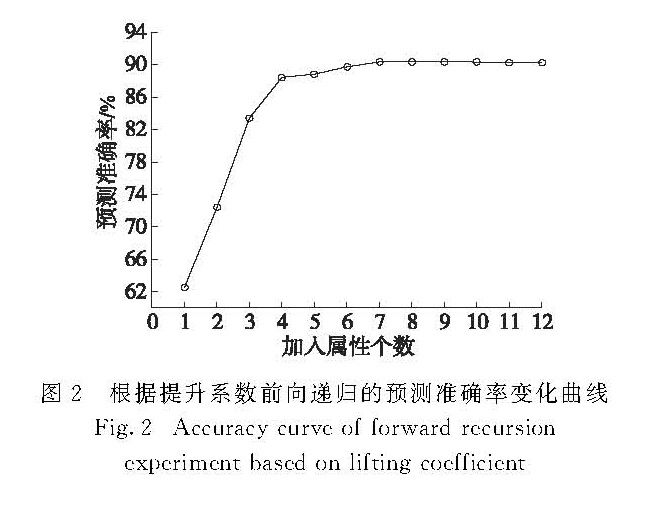
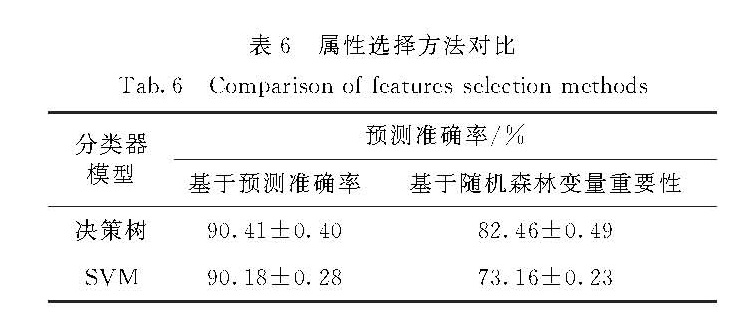
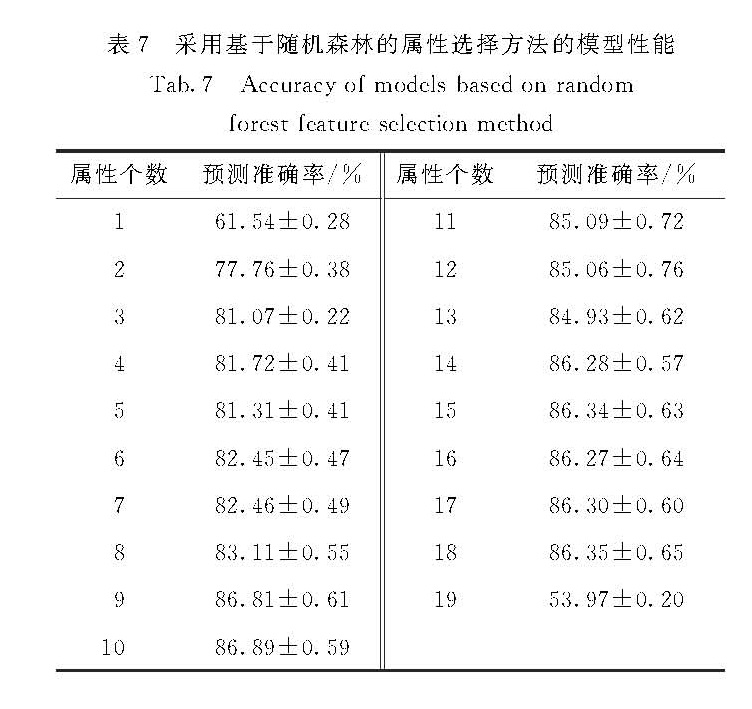
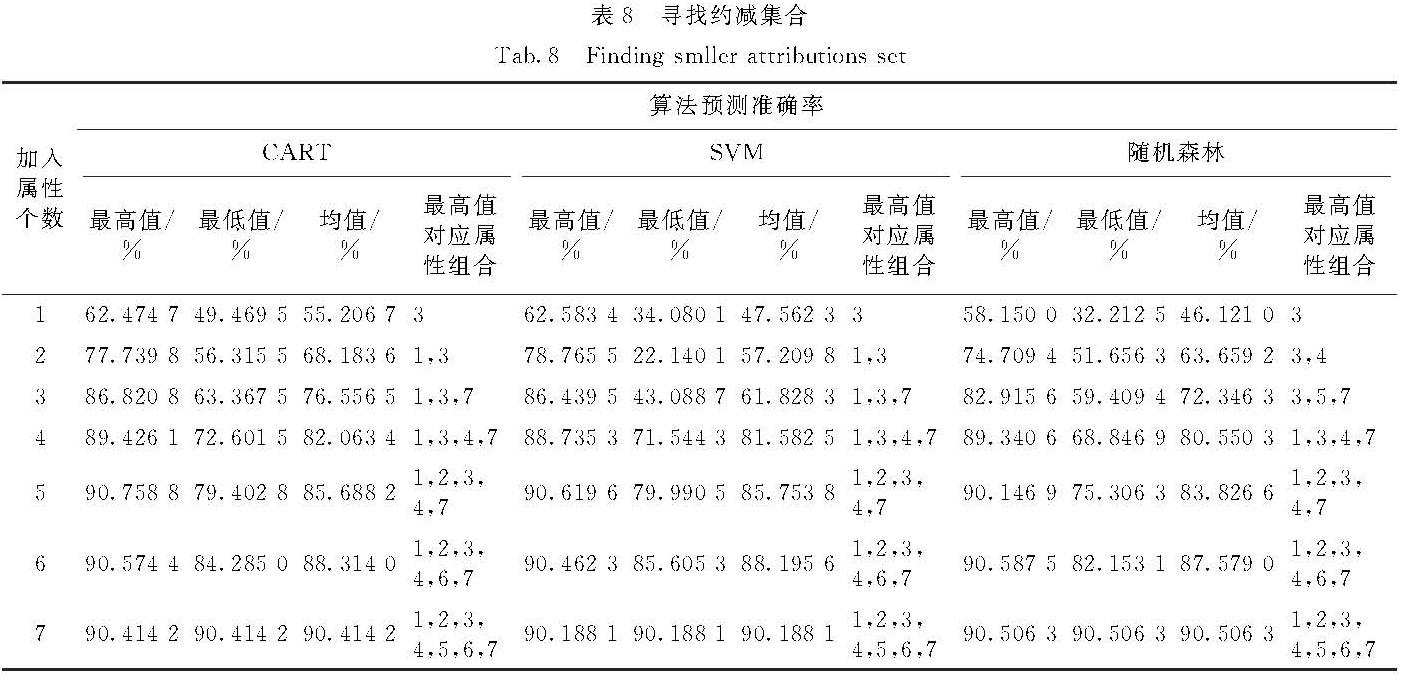
我国专利数据来源众多、指标关系复杂,针对现有专利价值评估过程依赖人为主观判断,缺乏客观、合理评估方法等问题,提出了一种基于分类回归树(classification and regression tree,CART)模型的属性选择方法,用于构建专利价值评估的指标体系.实验结果表明相较于基于随机森林的属性选择方法,该方法不仅能有效地降低指标体系的规模,并且能提高评估建模的效率,在兼顾评估模型可解释性的基础上更好地提高专利价值评估的准确性.进一步通过枚举遍历的方法,约减指标集大小,构建出规模更小的指标体系,结合专家知识和实证研究,有效地验证了该指标体系的可解释性和现实意义.
The scientific and accurate patent-value assessment will promote the transition of patent industrialization and commercialization,which is the important key point of promoting the national and enterprise's comprehensive strength.As for features of numerous patent data sources and complex indictor relationships in our country and problems that the current patent-value assessment process depends on human and lacks the objective and reasonable assessment method,a features selection method based on the Classification and Regression Tree(CART)decision tree model is proposed in this paper,which is used for building the patent-value assessment indictor system.The experiment result indicates that,compared with the features selection method based on the Random Forest,this method not only effectively reduces the indictor system model size,but also improves the efficiency of the patent value assessment.At the same time,we better enhance the accuracy of the patent value assessment based on the improvement of interpretability of model.This paper reduces the size of the indicator set and builds a smaller indictor system further by the enumeration method,combined with the professional knowledge and empirical studies.It verifies the interpretation and practical significance of this indictor system effectively.