收稿日期:2016-03-31 录用日期:2016-06-03
基金项目:国家自然科学基金(61471309); 福建省自然科学基金(2013J01258)
通信作者:hxsun@xum.edu.cn
基金项目:国家自然科学基金(61471309); 福建省自然科学基金(2013J01258)
通信作者:hxsun@xum.edu.cn
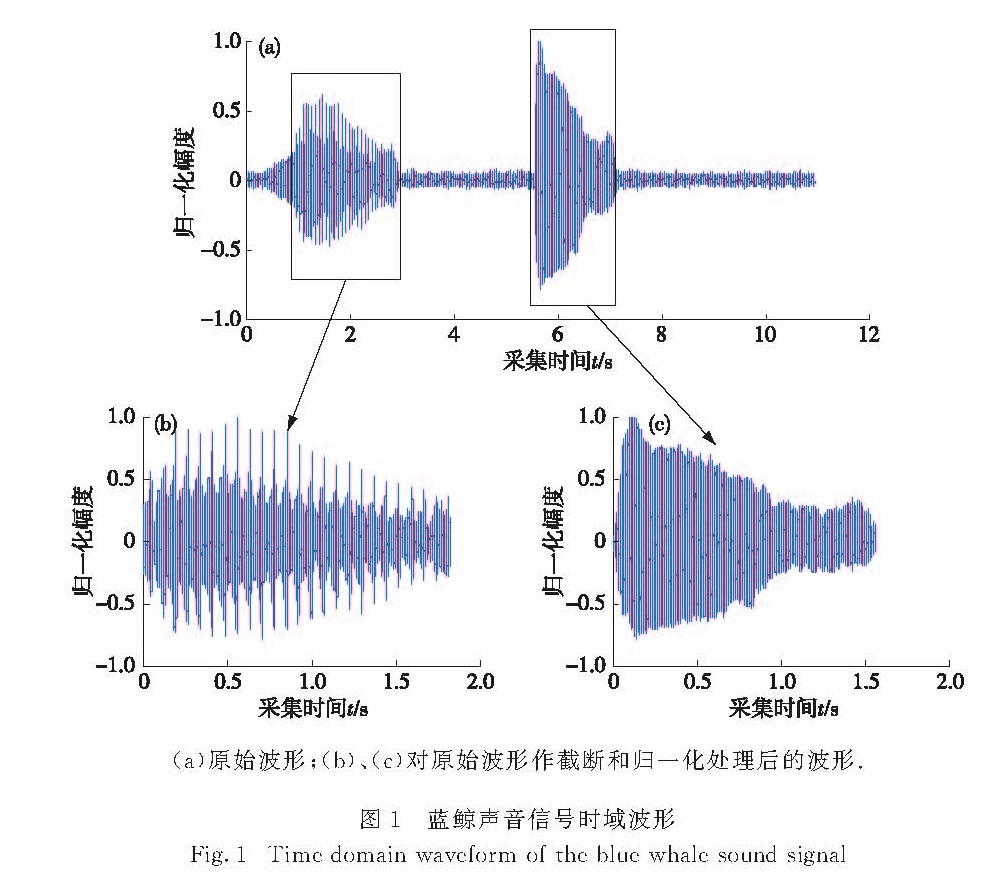
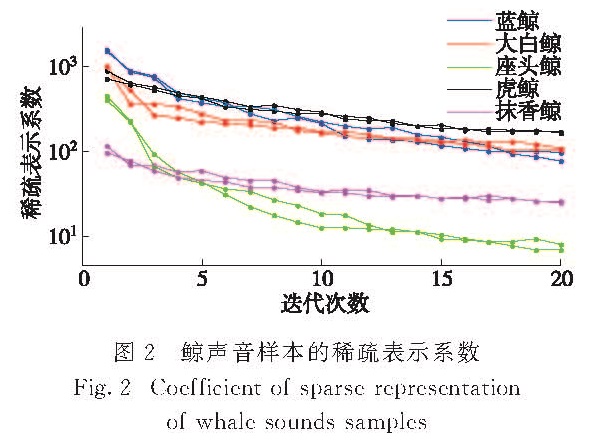
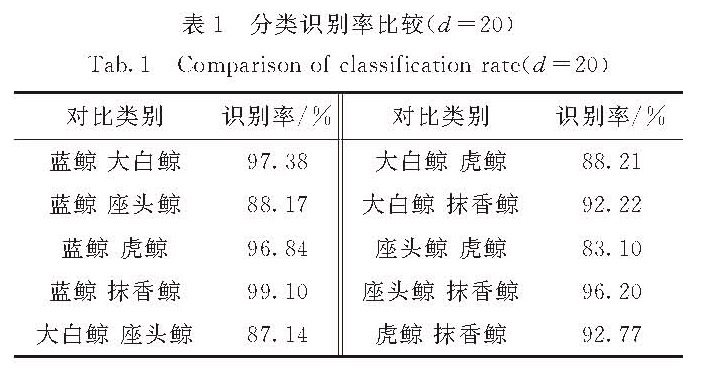
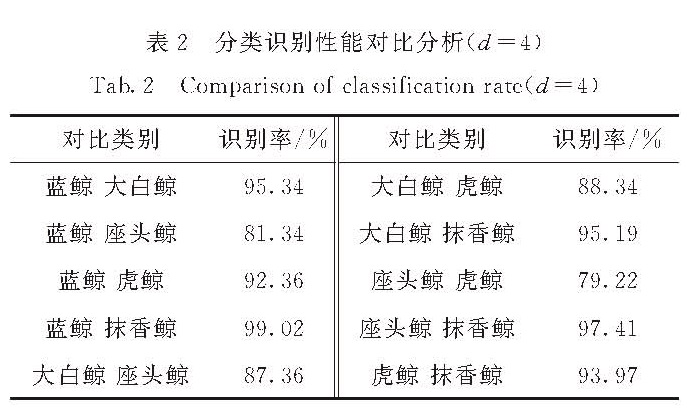
针对传统的水声信号分类技术处理方法复杂、特征提取时间长以及特征量多等问题,提出了一种基于稀疏表示的分类系统,先利用正交匹配追踪法(OMP)算法提取与水声信号最为匹配的少数原子作为目标特征,再采用支持向量机(SVM)进行分类.对鲸类声信号进行仿真实验,实验结果表明,不仅提高了压缩效率和运算速度,而且识别率高,在水声信号的实时处理中具有较高的实用价值.
Traditional classification technologies of underwater acoustic signals are involved withissues such as the complicated processing method,the prolonged feature extraction,vast features and other problems.In this paper,we propose a novel method based on sparse representation classification.First,we extract a spot of atoms matched best with underwater acoustic signals as signal features utilizing the OMP algorithm.Second,we adopt SVM as our classifier.Through experimental evaluations,the effect of this method is shown to provide a significant improvement in compression efficiencies,computing speeds and recognition rates.