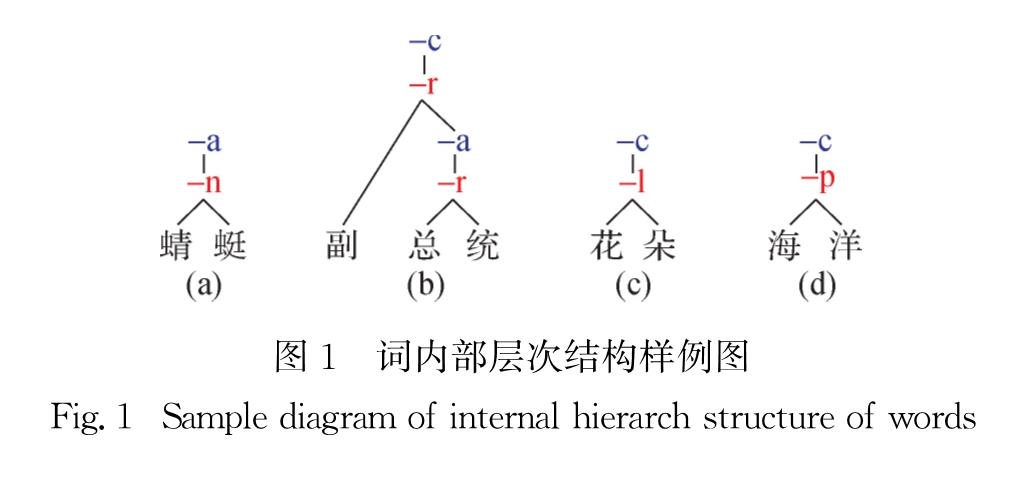
传统的中文自然语言处理任务或者先进行分词,然后以词为基本处理单元,或者直接以字符为基本处理单元.上述两种处理方式有着各自的优缺点.一方面,以词为单元保留了自然语言的语义信息,一个词就是一个基本的语义单元,能够很大程度上降低对句子理解上的歧义,但是存在数据稀疏问题.例如,“访问者”,即使是词表之内的词,但由于其在语料中出现的频率很低,模型仍然难以准确学到它的语义信息; 另一方面,以字符为单元虽然能够解决数据稀疏问题,但是字符相比于词歧义更大,同时句子输入序列过长,因此无法充分利用中文原子词的语义信息.例如:“蜻蜓”的语义由字符序列作为整体构成,而无法由字符语义组合而成.可见,如何探索适合中文自然语言处理的基本语义单元具有重要的研究意义.
对此,本研究认为定义合适的基本中文语义单元,并在此基础上引入词内部结构将有利于解决上述难题:1)引入更细粒度的语义单元,将有助于解决数据稀疏的问题.例如,可以将“访问者”拆分成“访问”和“者”两个语义单元.同样的句子在不同分词下标准中的结果往往不同,而细粒度语义单元的使用可以提高不同分词下标准分词结果的一致性; 2)进一步引入词内部结构可有效建模中文词内不同粒度的语义单元之间的关系; 3)基于词内部层次结构可以建模词的语义表示,作为传统以词为基本单元的词向量表示方法的有效补充.因此,探索词内部的基本语义单元和它们之间的层次结构对中文自然语言处理任务的研究具有重要意义.
近年来,在词的构成和表示上,语言学家们从语素的层面进行了较为深入的研究和探讨[1-4].与此同时,随着计算机中文文本处理的快速发展,中文词的结构以及词义表示也成为自然语言处理的研究热点之一.在这方面,Zhao[5]从词法标注角度探究了中文字符级别的依存关系,将词解析为以字符为基本单元的依存树结构.Li[6]同样考虑了词内结构,提出了一种新的分词方法.与前面工作不同的是,Li[6]的工作是基于词性标记并且区分了扁平词(即无内部结构的词)和有内部结构的词.Li等[7]认为中文中的前缀和后缀字符会派生出很多伪未登录词,而这些字符往往频率较高并且具有相同的语义用法,尽管它们在词中和在短语中的标注并不相同.例如:“刑法”和“环境保护法”,字符“法”的语义用法完全相同,但是前者将“法”标注为后缀,而后者将其视为词.因此,为缓解上述伪未登录词和标注不一致的问题,受先前联合建模的工作[8-9]的启发,Li等[7]将中文词法结构和句法结构解析进行统一建模,同时解析出词和短语的内部结构.进一步地,Zhang等[10]研究了基于字符的词内部语法结构,对分词、词性标注和句法解析3个任务进行联合建模.相较于Li[6],Zhang等[10]的词标注覆盖了整个中文树库(Chinese tree-bank,CTB)的词表.
与此同时,随着深度学习的快速发展,研究者也开始关注如何利用词内部细粒度语义单元来获得整个词的语义表示.Chen等[11]提出使用字符的平均表示以加强词义表示.Xu等[12]则在Chen等[11]的基础上对字符级的表示做了加权平均.Wang等[13]同样致力于细粒度语义单元对词义表示的影响,不同于前面的工作,他们认为词义表示由原子表示和组合表示共同组成,而后者可由字符语义表示通过注意力机制加权得到.
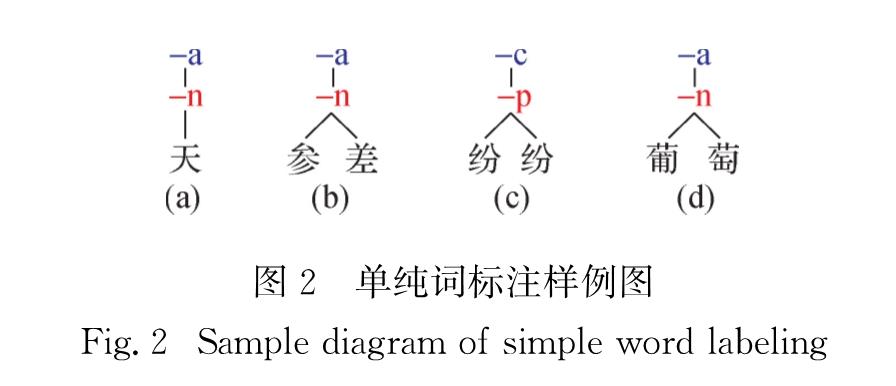
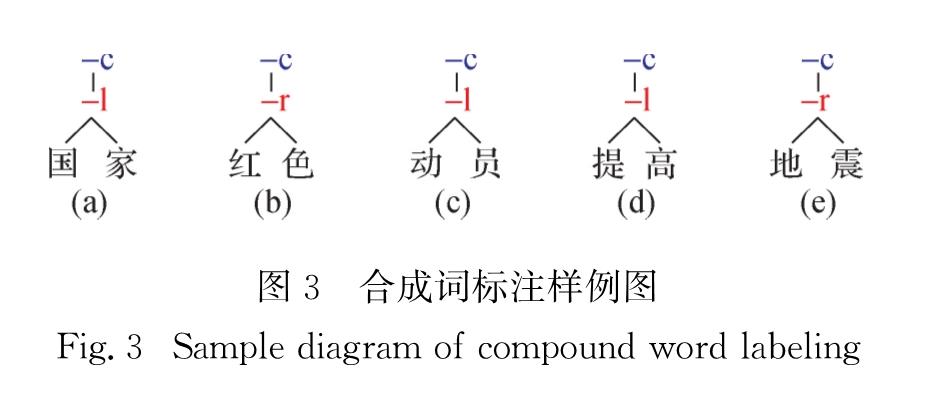
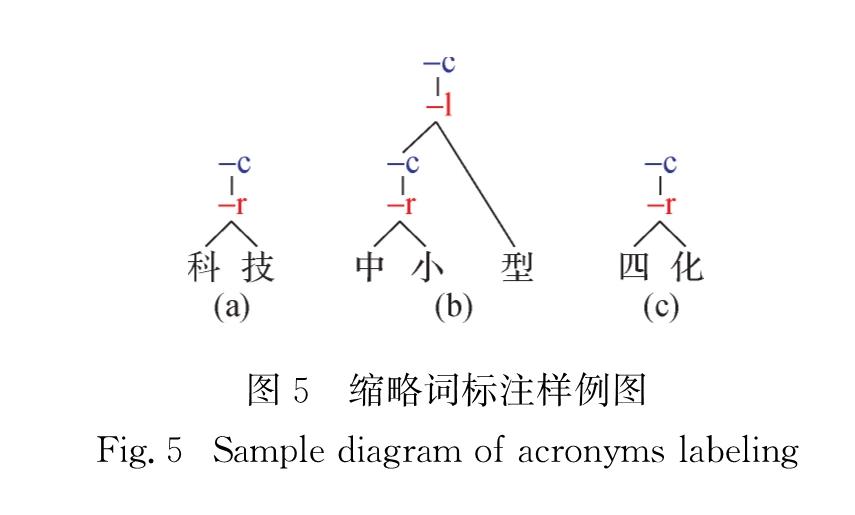
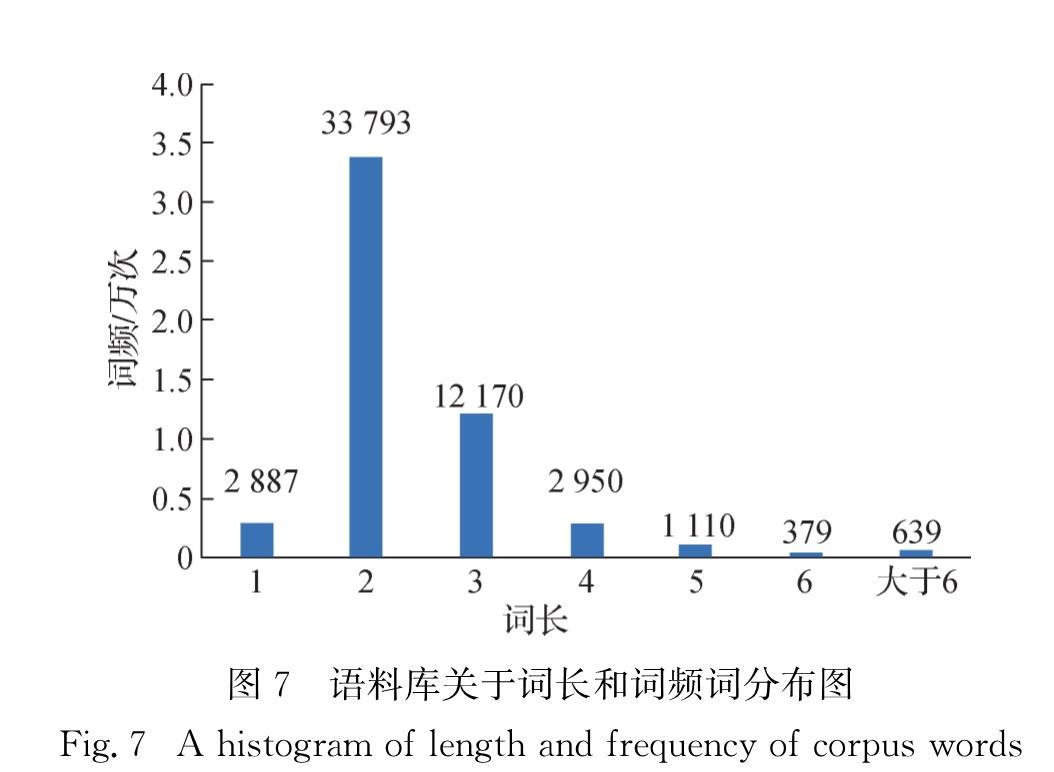
总体而言,上述工作均存在一定缺陷,主要为以下两点:1)多以字符为基本单元,然而,中文完全以字符作为基本语义单元存在歧义; 2)部分工作虽然考虑词内部结构,但这些结构往往较为简单,不够丰富.本研究借鉴现有相关工作,提出一种新的中文词内部层次结构定义标准,该标准首先定义了基本语义单元,并定义了以这些单元为基础的词内部结构,结构中包含了节点类型和节点内部关系; 进一步提出中文词内部层次结构的标注规范,并人工标注了带有内部层次结构的53 918个中文词料库.