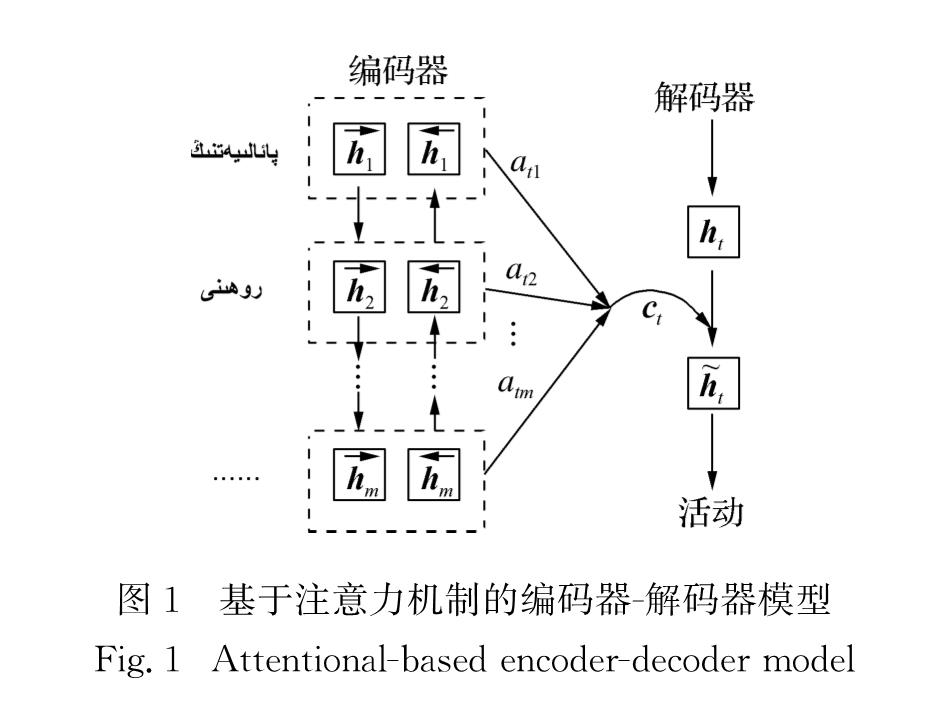
神经机器翻译(NMT)技术是近几年发展起来的一种新型机器翻译方法[1-2],一般通过基于循环神经网络(RNN)的编码器将源端语句编码为一个稠密的特征向量,然后使用解码器将该向量解码为目标端语句.此外通过添加长短时记忆(LSTM)[3]和注意力机制[4]等方法有效地处理长距离依赖问题,并捕获需要生成的目标词汇NMT技术相对应的源语句中的词汇.NMT技术已在汉语-英语、英语-法语等大规模的语言对上取得了巨大的进展,并已成为目前主流的机器翻译模式[5-6].
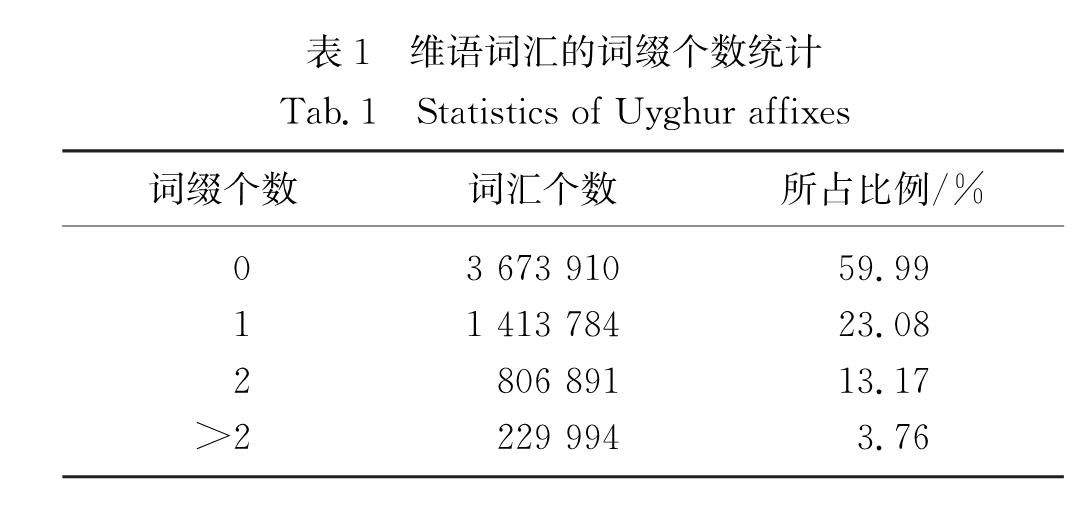
不同于汉语、英语等常见的孤立语和屈折语,维吾尔语(下文简称维语)是一种具有丰富形态结构的黏着性语言,采用词干和词缀的多种组合形式来表达词汇层面上的句法和语义关系.虽然维语的词干和词缀数量有限,但是通过两者的结合,理论上可以生成无限数量的词汇,并且许多词汇在语料库中的出现频率很低[7-8].由于在处理维语相关的机器翻译任务时面临形态复杂性和数据稀疏性等问题,因此无法获取高质量的译文结果.
虽然在大规模双语语料下,NMT在预先不提供任何语法信息的前提下,仍可以通过其内部的网络机制捕获隐藏在源端语句中的浅层词汇信息,但很难挖掘深层的句法信息[9]; 同时由于维语的复杂性,缺少高质量的依存关系抽取、命名实体语别以及语句结构解析等句法分析工具抽取句法结构信息,因此高效地利用维语的词性标签和词缀形态标签特征等浅层语法知识非常关键,通常采用融合多种语法特征的方法.Alexandrescu等[10]提出一种因子化的神经网络语言模型,该模型将词汇和词类特征映射至连续空间中,用于预测下一个词汇; Koehn等[11]引入多个特征集成的翻译模型,该模型融合了词汇级的语法信息,提高基于短语的统计机器翻译(PBSMT)的翻译效果; Chen等[12]使用词汇、词性标注和依赖标签训练神经网络分类器,用于分析深层依存句法关系; Sennrich等[13]对编码器的嵌入层进行扩展,以融合多个输入特征至NMT系统中; Aqlan等[14]对阿拉伯语-汉语的PBSMT系统进行优化,采用阿拉伯语词汇的词干、词性标签和形态特征作为词汇的附加信息,并对未登录词(OOV)和缺失词进行建模.
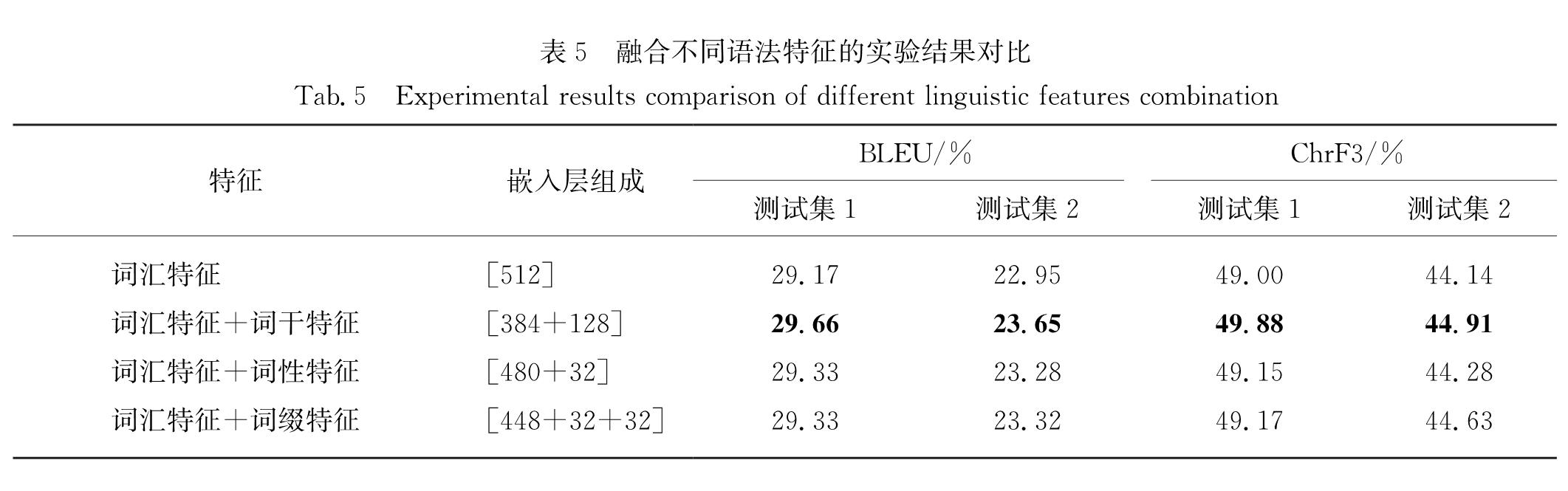
另外,哈里旦木·阿布都克里木等[15]对6种主流的NMT技术进行了深入比较和分析,实验结果表明,相较于维语形态切分,词表扩大更能提高机器翻译性能,并且大规模的词表中包含更多的维语词汇.但NMT系统使用的词汇表规模有限[16](一般3万到8万大小),只能保留有限的高频词汇; 对于稀有词汇和低频词汇,统一使用“<UNK>”进行表示,在一定的程度上丢失了部分词汇的语法信息.因此,将维语词汇的语法特征融合至NMT系统中,可能可以辅助单一的词汇表示形式帮助模型更好地利用维语词汇在不同上下文中的特征信息学习维语的句法结构,增强模型对源端维语语句的表示和学习能力,从而提高机器翻译质量.
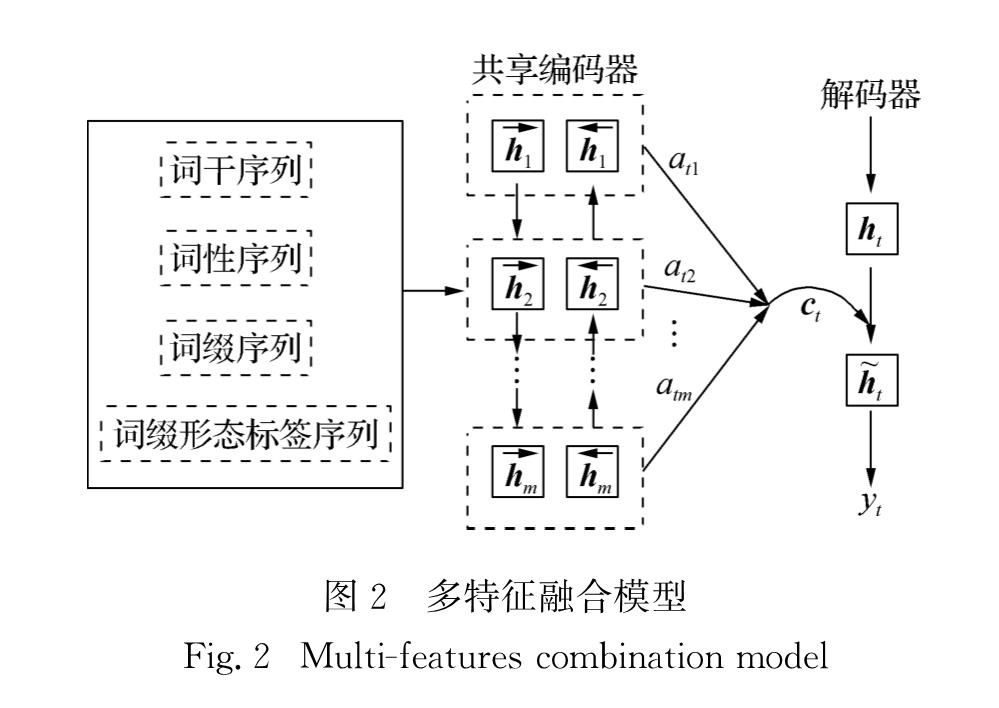
基于以上分析,本文提出一种层次化融合多个维语语法特征的NMT模型,该模型采用4种浅层语法特征,作为维语词汇的附加信息输入至翻译系统中; 同时引入层次化神经网络结构对上述词干级特征和词缀级特征进行融合,以增强NMT系统对于深层维语语句的句法结构和语义知识的学习能力,提高机器翻译质量.本文的主要贡献包括以下两点:1)构建层次化的语法特征融合模型,将维语的词干级特征和词缀级特征进行分层融合,保证了源端输入信息的结构性.2)针对维语的复杂语言形态,显式地对维语的词缀特征进行建模,保证了词汇信息的完整性.