目前,维吾尔语中用于有监督消歧模型的词义消歧标注语料资源非常有限,同时也缺少相应有效的歧义词主动发现方法.因此很难实现面向所有词任务的词义消歧模型,同时也限制了传统有监督方法在维吾尔语中的应用.传统无监督词义消歧方法,虽然不依赖于标注训练语料,但一般需要有相应的义类词典、语义网络、网络百科词典等,如Roget's Thesaurus、WordNet、HowNet、Wikipedia等.然而,维吾尔语作为一种典型的资源稀缺型语言,上述类型的语料资源仍在建设完善中.这一方面导致了目前维吾尔语词义消歧应用场景的局限性,即在深度语义信息难以获取和利用的限制下,需要使用更多语义相关的上下文词来更准确地表达歧义词在当前上下文中的语义信息.因此更适用于篇章文本的歧义消解,在句子级中性能表现非常有限.另一方面也极大的限制了维吾尔语词义消歧方法的选用:由于缺少如WordNet等有效外部特征信息的引入,导致传统的基于词典、语义网络和图模型的无监督词义消歧方法也难以实现.考虑到LDA是一种基于词频统计特征的词袋模型,因此考虑抽取与歧义词关联度高的词作为LDA模型的有效词,强化主题模型与词义消歧模型的关联性.
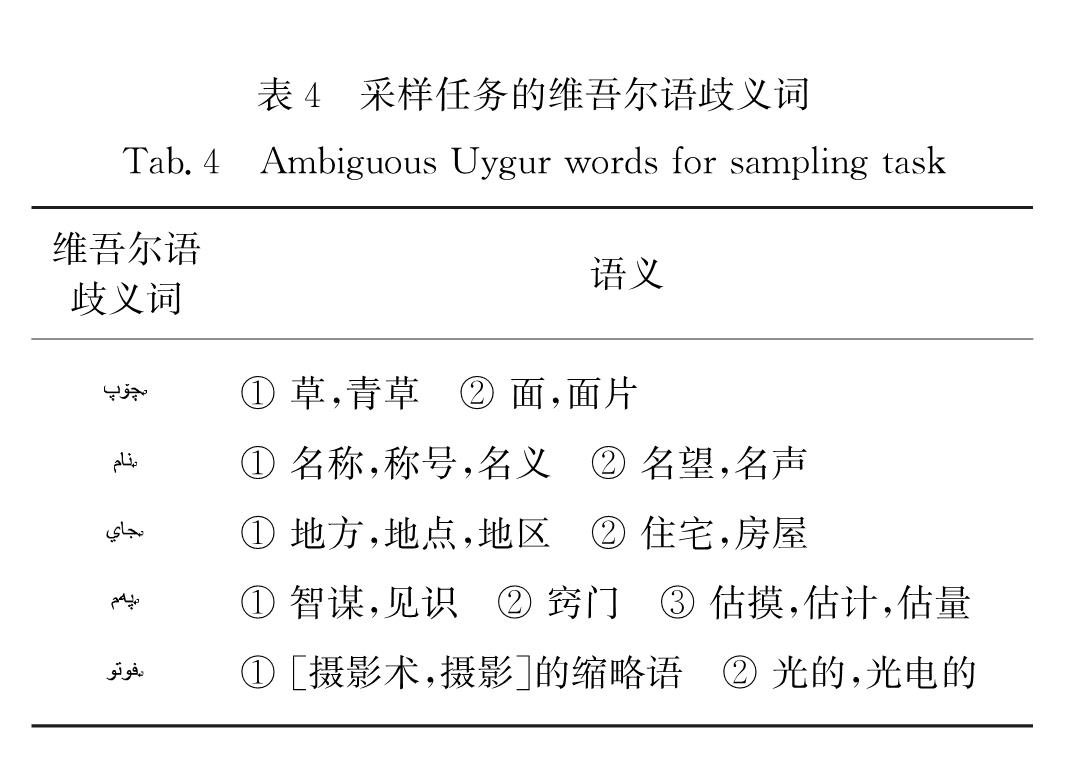
本文拟解决的消歧问题可以表述为:针对维吾尔语歧义词采样词任务,已知歧义词wi以及该词对应的K个不同语义义项si,k(k=1,2,…,K),每个义项都对应一个包含该歧义词的篇章文本ti,k.当出现含有歧义词wi的待处理篇章文本tnewi时,确定在该篇章文本上下文中wi对应的语义义项si,k.
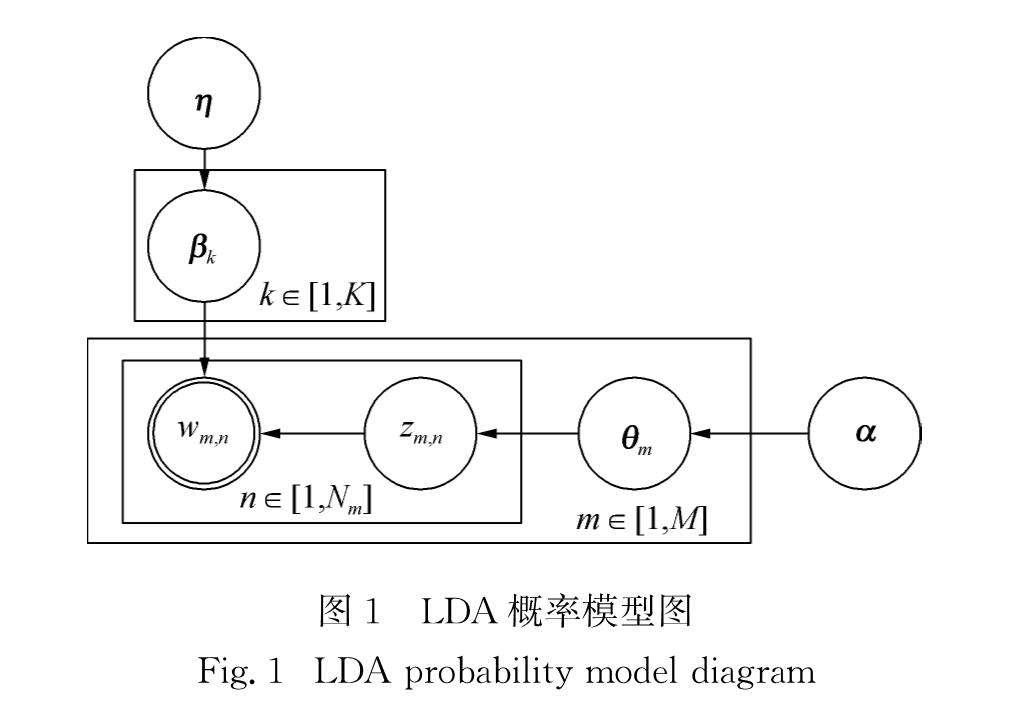
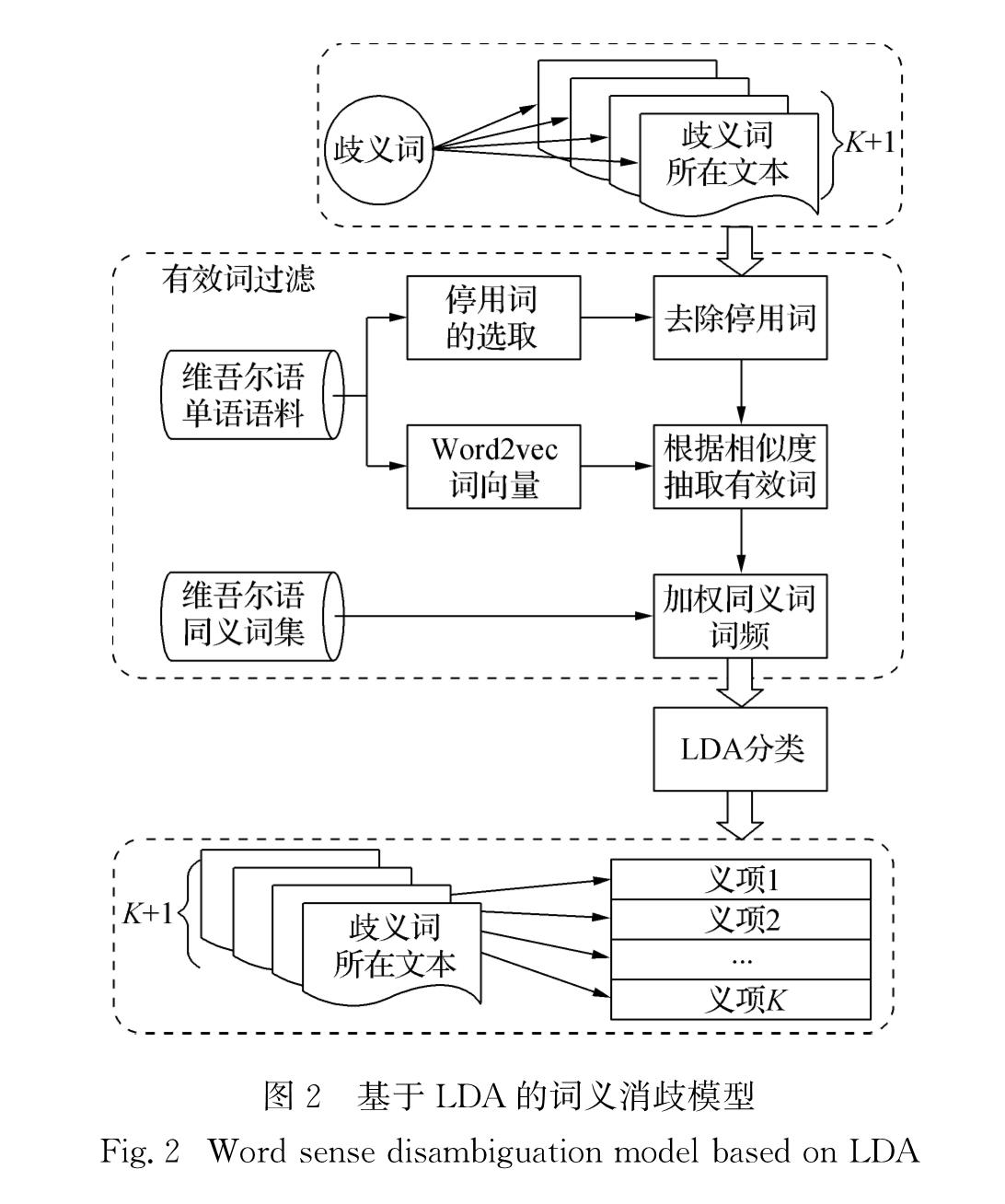
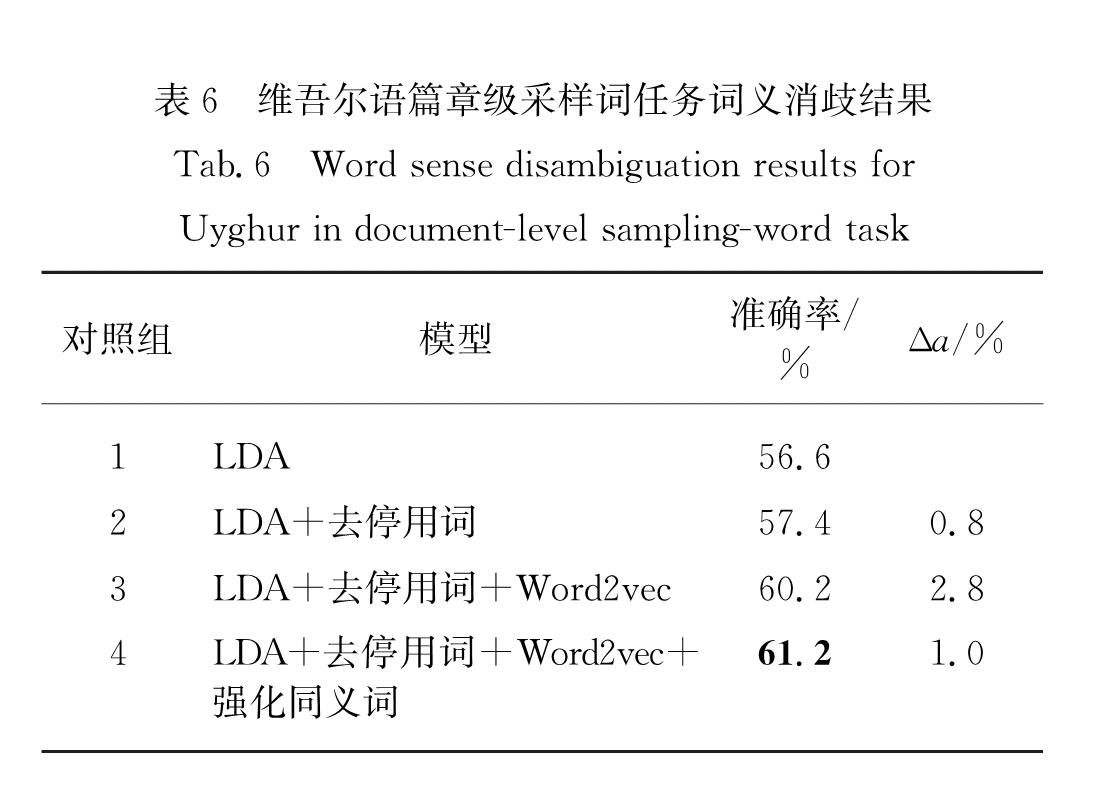
针对上述问题,本文使用LDA主题模型构建无监督词义消歧模型,如图2所示.根据待消歧文本tnewi和已知的歧义词各义项对应文本ti,k,构建待分类文本集Ti={tnewi,ti,1,ti,2,…,ti,K},则Ti中文本数为M=K+1.将歧义词的不同语义义项视为文本的主题类型,那么待分类文本集中每个文本的歧义词-义项关系就可以类比为文本-主题关系,因此可以通过LDA主题分类模型确定每个文本中歧义词-义项的分布关系,并由此确定tnewi对应的主题(义项).与主题分类模型不同的是,此时待分类文本集对应的主题数(义项数K)是已知的.同时,注意到传统LDA模型中,文本的主题是通过文中所有词汇的主题分布进行确定的,直接将LDA用于词义消歧时存在一个问题,即歧义词及其语义关联词只是众多参与表示文本主题词汇中的一部分.为了保证歧义词的语义义项信息与文本的主题信息高度一致,需要对LDA模型中参与主题表示的词汇进行过滤,即筛除文本中参与表达文本主题但与目标歧义词语义关联度低的词汇,具体表现为图2中的有效词过滤环节:首先去除停用词,然后根据词向量相似度抽取出与歧义词关联度高的词作为有效词,最后进一步提高有效词中同义词的参与权重.过滤并调整有效词后,使用LDA模型进行文本分类,并根据文本-主题(义项)的分布概率确定待消歧文本中歧义词对应的语义义项.
图2 基于LDA的词义消歧模型
Fig.2 Word sense disambiguation model based on LDA
2.1 去除停用词
停用词一般指文本中普遍出现的,主要用于语法结构搭配的功能词,如“a”、“is”、“the”、“在”、“个”等.停用词由于其本身的普遍性和语法功能性,通常与篇章文本的主题关联度较低,在词义消歧中,表现为歧义词与上下文中停用词的语义关联度非常低.因此,首先需要对待分类文本进行停用词过滤预处理,避免上下文中停用词对篇章主题和歧义词语义信息的影响.
本文中,停用词主要包括数字、字母、符号和高频维吾尔语词汇.其中,高频维吾尔语词汇是在35万句维吾尔语语料的词频统计数据中过滤得到的,人工过滤词频数高于5 000的词汇作为停用词.最终整理出的维吾尔语停用词如表1所示.
表1 维吾尔语停用词
Tab.1 Stop words in Uyghur
2.2 过滤有效词
由第1节介绍的有关主题模型生成文本的过程可以看到,除了常见的停用词外,LDA模型认为文本中每个词汇都与文本主题相关,因此文本的主题本质上是通过文中每个词汇的主题分布叠加计算后确定的.然而,将LDA应用于词义消歧任务中,将文本主题类比为歧义词语义义项时,除了去除停用词外,还需要进一步过滤出其中的有效词汇,即区分出文本中与歧义语义相关的词和参与文本主题表达但与歧义词语义不相关的词.显而易见,前者是我们需要的有效词汇,而后者是需要排除的噪声词.
使用Word2vec训练出维吾尔语词向量,并使用余弦相似度计算词对(X,Y)之间的语义关联度:
cos θ=(∑ni=1(Xi×Yi))/((∑ni=1(Xi)2)1/2×(∑ni=1(Yi)2)1/2).(1)
为了确定合适的语义关联过滤阈值,计算停用词表中停用词与歧义词的平均向量相似度作为过滤阈值,计算公式如下:
γi=(∑Nstopj=1cos(wi,wj))/(Nstop),(2)
其中,wj为停用词,停用词表中共有Nstop个词汇(包括字母等),γi为每个歧义词wi对应的过滤阈值.根据停用词的定义可知歧义词与文本中停用词的语义关联度很低,因此如果词-歧义词之间的向量相似度低于其对应的过滤阈值,那么这些词即为LDA模型中的噪声词,而其余词汇则是有效词.
对包含歧义词wi的任一篇章文本ti,m∈Ti,wi,m∈ti,m为该篇章文本中包含的词汇.计算歧义词与篇章词汇向量之间的余弦相似度,并根据过滤阈值将wi,m添加到有效词集Weff和噪声词集Wnoise.即
{wi,m∈Weff, 当cos(wi,wi,m)≥γi,
wi,m∈Wnoise, 其他.(3)
2.3 强化同义词
与上下文词汇相比,在篇章文本中出现的同义词词组集合与文本表达的主题关联性更强,因此首先构建维吾尔语同义词集.
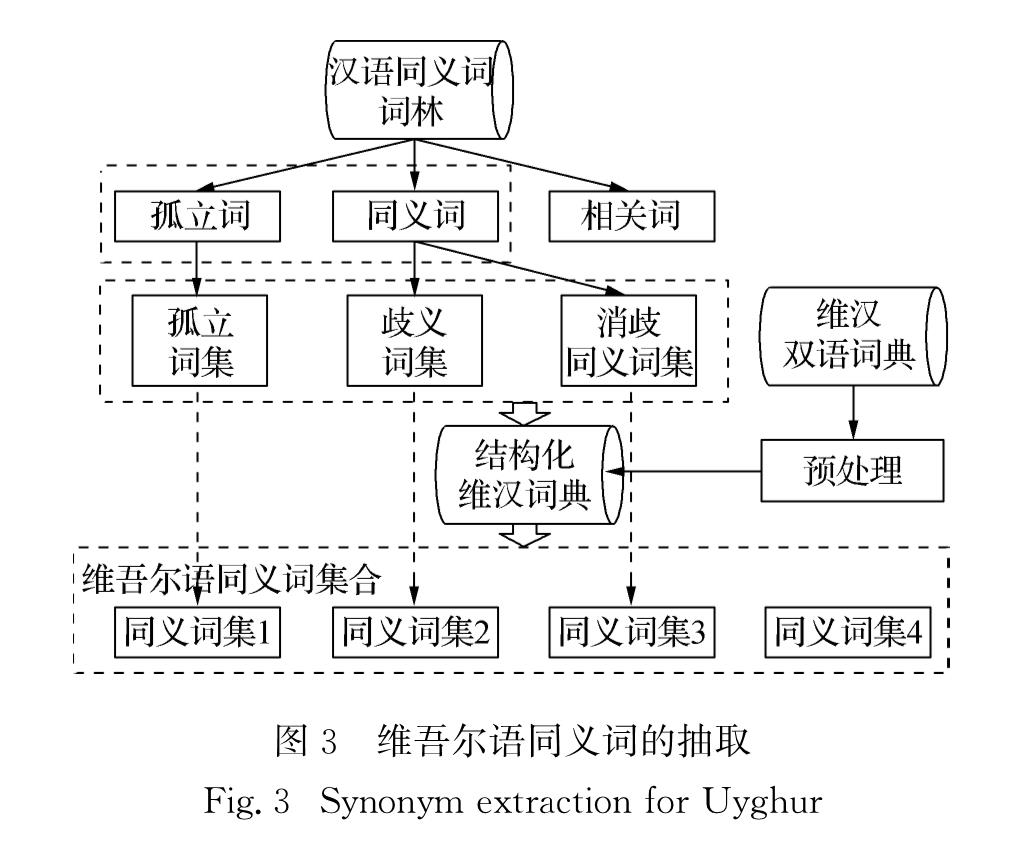
本文采用基于维汉对齐词典的同义词抽取方法,对维汉对齐词典和汉语同义词进行词条匹配,并抽取出对应的维吾尔语同义词集.具体抽取过程如图3所示.
首先对汉语同义词词林预处理,在《哈工大同义词词林扩展版》[20]中,汉语词义关系标为3类:孤立词、同义词和相关词.其中相关词不做考虑,同时由于汉语同义词中包含的部分多义词会影响维吾尔语同义词抽取的准确率,所以进一步将汉语词分为:孤立词集(不存在同义词,也不具有歧义)、歧义词集和消除歧义词后的同义词集(即消歧同义词集).
图3 维吾尔语同义词的抽取
Fig.3 Synonym extraction for Uyghur
然后对维汉对齐词典进行结构化处理.原始词典词条结构为“维吾尔语词汇/短语集+汉语词集+拼音”,如“认真rèn zhēn; 老实lǎo shí; 率真shuài zhēn; 忠诚 zhōnɡ chénɡ ”.
预处理过程主要包括去除维吾尔语短语、非维汉词汇、标签文字以及汉语形容词后缀“的”,并按照汉语词汇长度和对应维吾尔语词数调整词条结构.处理后的词条结构为“汉语词+对应维吾尔语词数+维吾尔语词集”,如“认真5”,共63 477条.
根据同义词的一般性定义,以及原始和处理后的结构化维汉对齐词典,提出两条策略:
1)同一词条中的维吾尔语词构成维吾尔语同义词集;
2)不同词条中,汉语词是同义词,对应的维吾尔语词合并为一个维吾尔语同义词集.
根据过滤结果以及策略1)和2),对维汉对齐词典进行同义词抽取,得到4类维吾尔语同义词集分别对应汉语孤立词集、汉语歧义词集、汉语消歧同义词集以及未在汉语同义词词林中出现的汉语词集,具体抽取结果如表2所示.其中,维汉对齐词典和结构化词典的词数分别为385 505和63 477,对应抽取出的以上4类维吾尔语同义词集数分别为332,2 740,4 363和8 088条.对每类抽取结果按照词条中维吾尔语词频区间分布,各自随机抽样100组词条进行人工评价,准确率分别为88.43%,76.09%,85.00%和83.13%.合计抽取维吾尔语同义词集共15 523条,平均准确率为83.16%.
表2 维吾尔语同义词集
Tab.2 Synonym set for Uyghur
使用上述维吾尔语同义词集匹配出每个篇章文本有效词集中的同义词,调整相应词汇的词频,从而增强篇章文本的主题(歧义词语义信息)表达能力.同义词词频加权公式如下:
tf(wSynseti,m)'=max(tf(wi,m))×
(1+(cos(WSynseti,m,wi)^-)/(cos(Weffi,m,wi)^-)),(4)
其中,wSynseti,m为篇章Ti中出现的同义词,max函数为篇章的最高词频数,cos(Weffi,m,wi)^-为篇章中有效词与歧义词的平均余弦相似度,cos(WSynseti,m,wi)^-为篇章中所有同义词与歧义词的平均余弦相似度.
2.4 主题分类
根据上述过程处理后得到的有效词进行LDA主题分类,使用Gibbs抽样方法进行参数估计,具体参数训练过程如下:
1)确定每个采样词的语义项数K(主题),待分类文本数M=K+1,并选择合适的先验参数α和η;
2)对每一篇文本的每一个有效词,随机分配一个语义项(主题)编号z;
3)扫描整个篇章文本集,对于每一个有效词,利用Gibbs抽样公式更新词汇的语义项(主题)编号,并更新篇章文本集中该词的编号;
4)重复步骤3),直到Gibbs抽样收敛;
5)统计整个篇章文本集中各文本各词汇的义项(主题),得到文本的义项(主题)分布θm,选取分布概率最高的义项作为该采样歧义词的消歧结果.