本研究以Transformer为基础架构,为每种语言创建一个编码器和一个解码器,又共享其中的部分层的参数并结合UNMT训练的3大原则在英语(en)、法语(fr)和德语(de)之间同时建立训练任务(enfr、ende和defr),训练得到UNMT模型.例如,当训练en→fr和en→de任务时,由于法语和德语有着相似的语言结构,可以从不同的目标语言中联合学习到有用的语义和结构信息.
1.1 Transformer架构
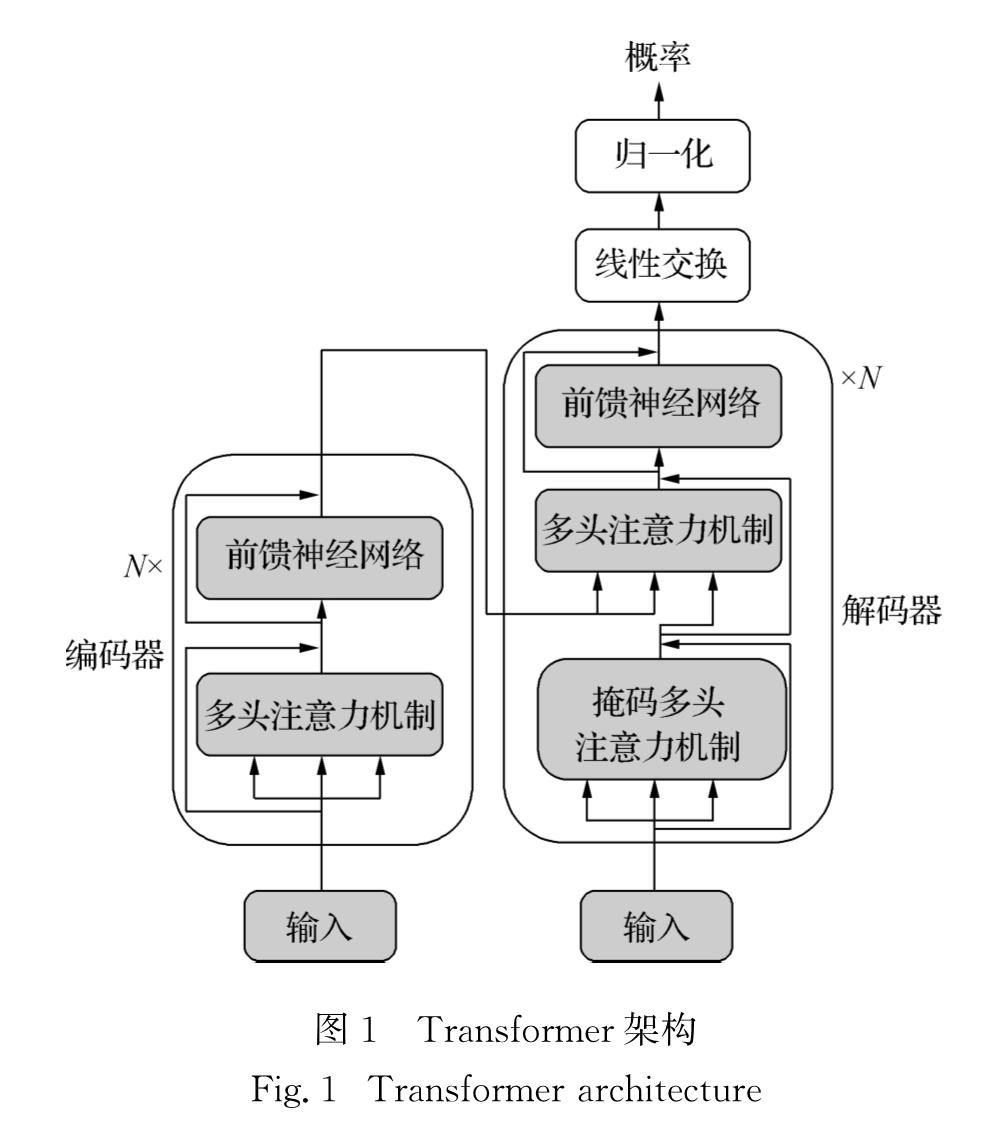
Transformer的主要特点是它既不依赖于RNN也不依赖于CNN,而仅使用自注意力机制实现了端到端的NMT.自注意力机制是将一句话中的每个词和该句子中的其他所有词进行注意力计算.目的是为了学习句子内部的依赖关系,捕获句子的内部结构.
Transformer架构的结构图如图1所示.Transformer的编码器和解码器都是多层网络结构,编码器和解码器都包含N个相同的层.在编码器中,每一层又包含2个子层,分别是自注意力机制层和前馈神经网络层.而解码器的每一层中,则有3个子层,除了一个掩码自注意力机制层和一个前馈神经网络层外,在它们中间,还有一个对解码器输出的多头注意力机制,子层之间均使用残差连接[11],残差连接的方式可以用式(1)表示:
hl=hl-1+fsl(hl-1),(1)
其中,hl表示第l个子层的输出,fsl表示该层中的函数功能.
图1 Transformer架构
Fig.1 Transformer architecture
1.2 双语单任务UNMT模型
双语单任务UNMT模型在训练阶段仅用Transformer结合UNMT 3大原则训练单个训练任务,即en→fr、en→de和de→fr中的一种.
本文分别用S和T来表示源语言和目标语言的句子集合,s∈S和t∈T表示单个句子,Ps和Pt分别表示由源语言和目标语言的单语训练出的语言模型,用Ps→t和Pt→s分别来表示源语言到目标语言和目标语言到源语言的翻译模型得到的预测概率,UNMT的过程主要由如下3步构成.
1)初始化.对模型的初始化大体分为两种方式:第一种方法使用word2vec[12-13]单独训练两种语言的词向量,再通过学习一个变换矩阵将两种语言的词向量映射到同一个潜在空间[6,14].这样就可以获得一个精确度良好的双语词表.第二种方法使用单词的字节对编码[15](BPE)作为子字单元.这样做的好处是在减少了词表大小的同时,清除了翻译过程中出现“未知(UNK)”的问题[16].除此之外,相比于第一种方法,第二种方法选择将两种单语语料混合打乱后共同学习词向量特征,源语言和目标语言可共享同一个词表.
2)语言模型.在双语单任务UNMT模型中,语言模型的降噪自编码器最小化损失函数为
Llm=Ex∈S[-logPs→s(x|C(x))]+
Ey∈T[-logPt→t(y|C(y))],(2)
其中:Ex∈s表示句子x属于s的交叉熵损失的期望; C(x)表示现有句子x加入噪声后的句子,其方法是交换句子中一些词的位置或者删除一些词.语言模型的训练过程实质上是以加入噪声后的句子C(x)为源端输入句子,以初始的句子x为目标端输入句子,把(C(x),x)当作平行句子对进行训练.
3)反向翻译.反向翻译的过程是把伪平行句对当作平行句对进行训练的过程.其训练的损失函数如式(3)所示.
Lback=Ey∈T[-logPs→t(y|u*(y))]+
Ex∈S[-logPt→s(x|u*(x))],(3)
其中:u*(y)表示由目标语言句子根据当前的语言模型翻译获得的源语言句子; 反之,u*(x)表示由源语言句子翻译获得的目标语言句子.反向翻译过程是把(u*(y),y)和(u*(x),x)都当作平行句对训练,将无监督的问题转换成有监督的问题.
反复迭代上述的2)和3),即为完整的双语单任务UNMT模型训练过程.
1.3 多语言多任务的UNMT模型
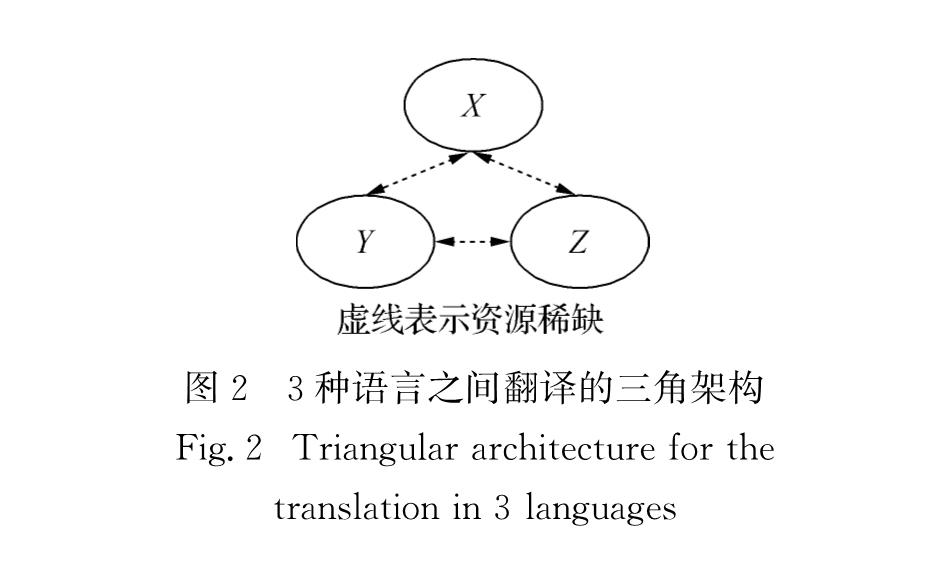
多语言多任务UNMT模型即为在Tranformer架构下结合UNMT 3大原则训练多任务获得的模型.具体地,假设当前有3种语言X、Y和Z的单语语料,彼此之前都不是平行的(如图2所示),则多任务UNMT模型包括6项训练任务,分别是X→Y、Y→X、X→Z、Z→X、Y→Z和Z→Y.受Yang等[14]的研究启发,为了在区分每种语言的语义结构的同时,学习到对方所包含的有用的结构信息,本研究为每种语言建立一个编码器和一个解码器,但是共享其中部分层的参数.其参数θ的优化过程如式(4)所示.
L(θ)=arg maxθ[∑N(1/M∑Mi=1log P(xni|yni; θ))],(4)
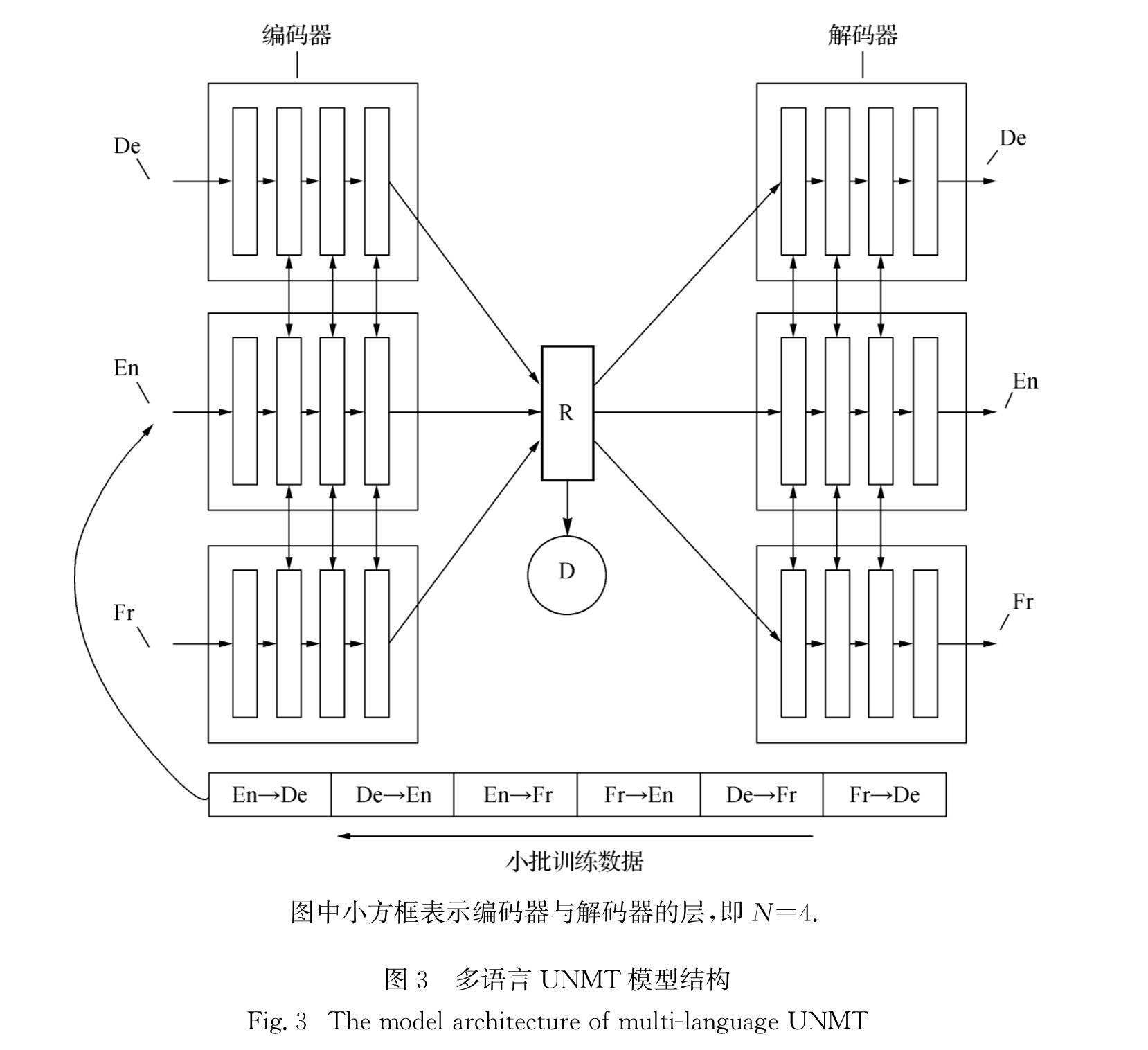
图中小方框表示编码器与解码器的层,即N=4.
图2 3种语言之间翻译的三角架构
Fig.2 Triangular architecture for the translation in 3 languages
图3 多语言UNMT模型结构
Fig.3 The model architecture of multi-language
UNMT其中:n=1,2,…,6,是翻译任务的索引; M是句子对个数; x和y分别为当前翻译任务中源语言和目标语言的句子.这样的参数设置使不同的语言对之间能够学习到其他语言的有用信息.
本研究的多语言多任务UNMT模型的模型结构如图3所示,模型由如下几部分组成:3个编码器、3个解码器、1个生成对抗网络D[17-18]和1个3种语言映射后共享的潜在空间R.每个编码器和解码器都有4个子层,双向箭头表示参数共享.本研究的模型参数与Lample等的实验[8]保持一致,将编码器的后3层参数共享,解码器的前3层参数共享.
为了强化共享潜在空间R的作用,本研究训练了1个生成对抗网络D用于X、Y、Z 3门语言对应的3个编码器之间建立三分类任务,其作用是预测当前编码语言的所属类别,优化方法为最小化式(5)所示的交叉熵损失.
LD(θD)=-Es'∈X[log P(f=X|EX(s'))]-
Es'∈Y[log P(f=Y|EY(s'))]-
Es'∈Z[log P(f=Z|EZ(s'))],(5)
其中:EX(s')表示当前编码的句子s'经过X语言的编码器的预测结果,s'既可能来自源语言,也可能来自目标语言; θD为生成对抗网络D的参数; f∈{X,Y,Z}; 为了训练这个生成对抗网络,编码器按下式进行优化训练.
LEX(θEX)=-Es'∈X[log P(f=Y|EX(s'))]-
Es'∈X[log P(f=Z|EX(s'))],(6)
LEY(θEY)=-Es'∈Y[log P(f=X|EY(s'))]-
Es'∈Y[log P(f=Z|EY(s'))],(7)
LEZ(θEZ)=-Es'∈Z[log P(f=X|EZ(s'))]-
Es'∈Z[log P(f=Y|EZ(s'))],(8)
其中,EY(s')、EZ(s')与EX(s')的含义类似,θEX、θEY和θEZ分别表示这3个编码器的参数.