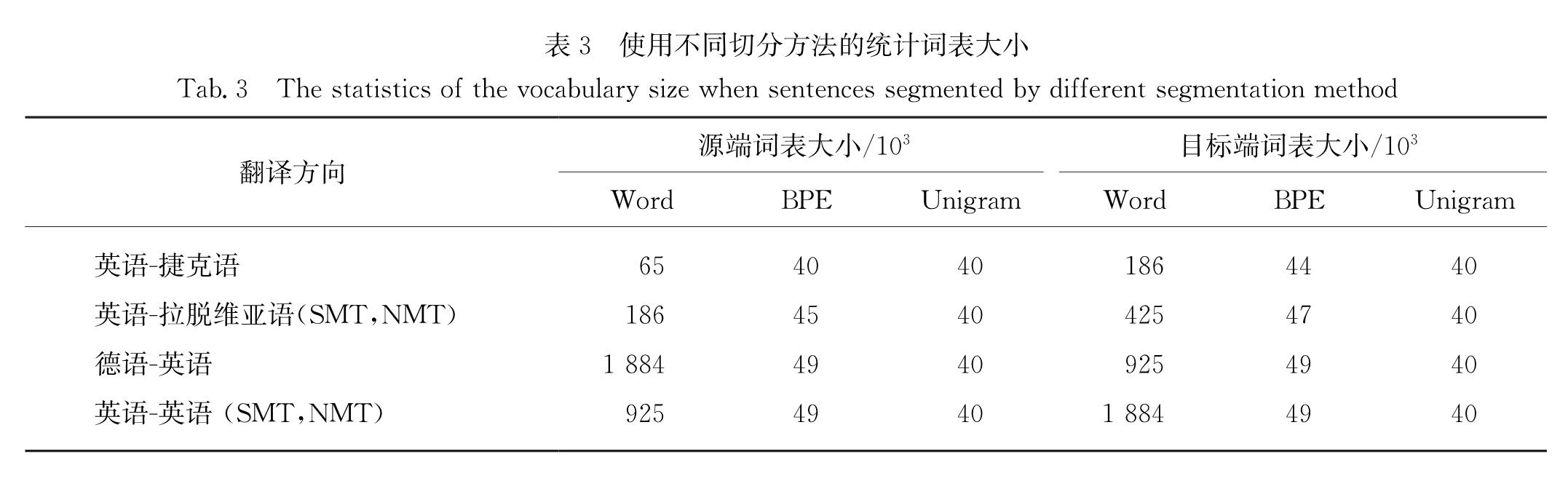
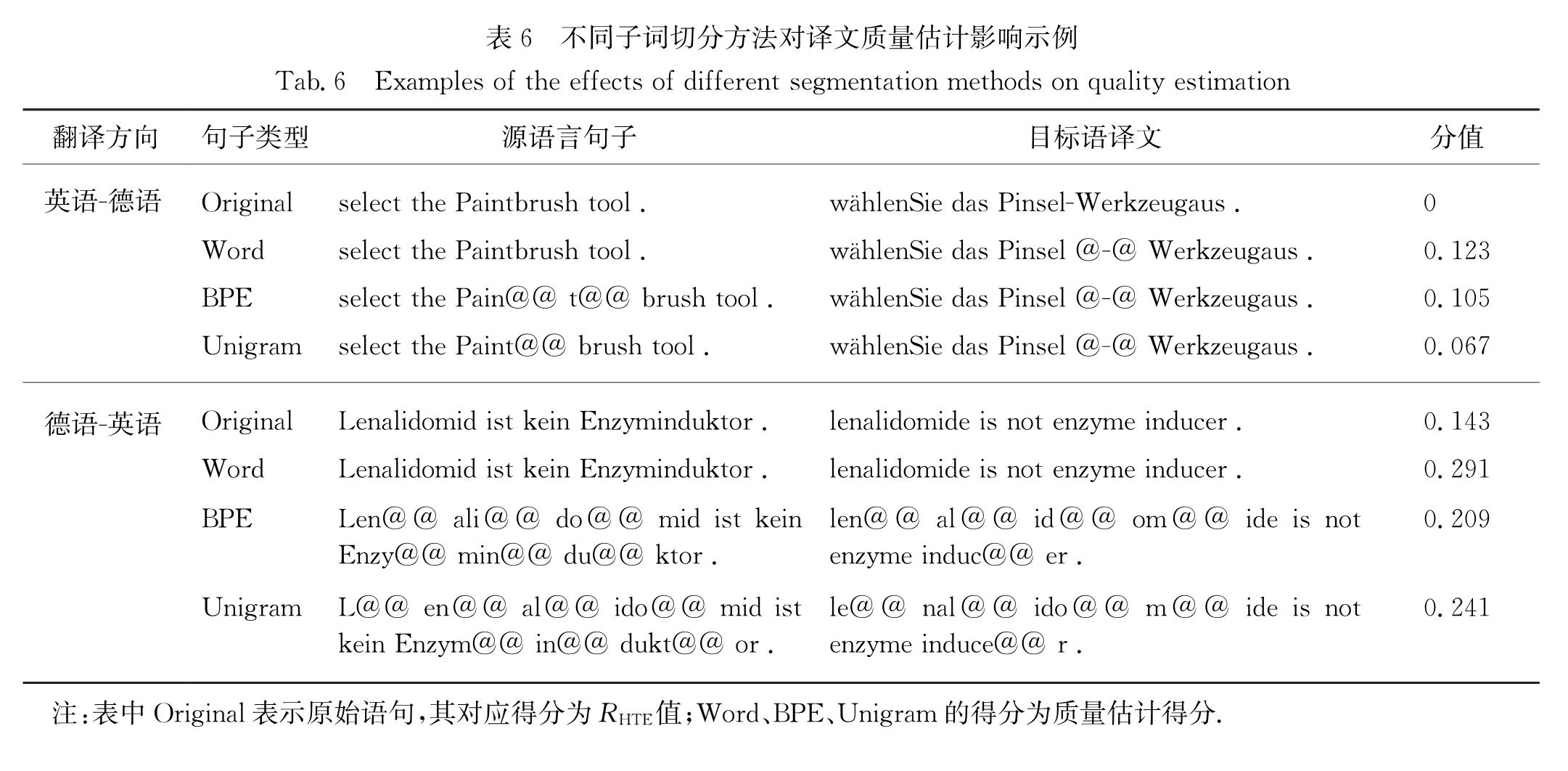
目前性能最优的译文质量估计系统使用神经机器翻译中的编码器-解码器模型作为特征提取器.该方法由于限制词表大小易导致数据稀疏问题,从而使得较多的未登陆词不能被正确评价.为了缓解上述问题,在详细分析不同子词切分方法的特点后,提出了基于字节对编码(BPE)子词切分和基于一元文法语言模型子词切分的神经译文质量估计方法,并将两者的译文质量估计的得分与基于词语切分的神经译文质量估计得分融合后进行译文质量估计.在WMT18句子级别译文质量估计子任务数据集上的实验结果表明:融合BPE子词切分、一元文法语言模型子词切分和词语切分的神经译文质量估计方法的性能在多个评测子任务上超过了WMT18给出的最好参与系统,深入的实验分析进一步揭示了融合不同粒度的句子切分方法提高了译文质量估计的健壮性.
Nowadays, the state-of-the-art translation quality estimation system takes the encoder-decoder model in neural machine translation as feature extractor.Duing to the restriction of vocabulary size,this method is prone to data sparseness,so that many out-of-vocabulary words can't be correctly evaluated.To tackle the data sparse issues,we propose the neural quality estimation approaches based on the byte-pair-encoding(BPE)subword unit and unigram language model subword unit after a detailed discussion of the characteristic of different subword segmenters.Furthermore,results of the neural quality estimation systems based on BPE subwords and that of the unigram language model subwords are combined with the results of the neural quality estimation systems based on words.Experimental results on the data sets of WMT18 sentence-level quality estimation tasks show that the ensemble system combining the results of the neural quality estimation systems based on BPE subwords,unigram language model subwords and words perform better than the best participated systems on several translation directions in WMT18 quality estimation task.Deep analyses further reveal that the ensemble system combining the results of neural quality estimation systems based on different granularity segmentations improve the robustness of the quality estimation system.
![图1 UNQE模型结构图[16]<br/>Fig.1 An illustration of the UNQE model architecture[16]](2020年02期/pic11.jpg)