随着神经机器翻译(neural machine translation, NMT)的发展,在线机器翻译平台可以给用户提供更合适、更流畅的翻译体验.不同的翻译模型结合不同种类的解码方法[1-2],如循环神经网络(recurrent neural network,RNN)[3]、卷积神经网络(convolutional neural network,CNN)[4]、Transformer[5]等,在不同句子上取得的翻译效果也不尽相同[6].机器翻译的译文质量估计(quality estimation,QE)任务[7-8]旨在无参考译文的前提下,对翻译结果的质量进行评估.
目前,机器翻译QE常用基线模型为QuEst++[9].随着深度学习的发展,越来越多的研究人员开始使用神经网络来解决这一问题.2014年,Zhang等[10]提出双语短语嵌入方法用于短语级别的译文QE任务.2015年,Kim等[11]提出了一种基于RNN的预测-估计框架POSTECH用于词级别和句级别的QE任务.UNQE(the unified neural network for sentence-level QE tasks)[12]是由POSTECH修改而来的,它将预测和估计结合在一起,帮助其特征提取器获得更多有用的信息.目前,Bilingual Expert[13]是QE任务上的最佳模型,其特征提取器基于双向Transformer,通过一个单向Transformer解码重构目标句子,并在大规模双语语料上进行预训练.DeepQuEst[14]则是一种简单快速的神经网络模型,主要解决句子级和篇章级的QE问题.
当前,大部分句子级的QE任务的目的在于预测翻译结果需要人工后编辑的工作量,WMT每年举办的QE评测任务就是针对该问题.在数据构建过程中,往往需要专家对翻译结果进行后编辑,之后通过计算翻译结果与后编辑标准译文的编辑距离(WMT往往使用TERp[15]进行计算)来代表工作量的大小.
POSTECH[11]、UNQE[12]、Bilingual Expert[13]、DeepQuEst[14]等基于神经网络的特征提取器考虑了源语句信息,但它们的主要模块是关于目标语言的语言模型.显然,源语句中的词汇和其翻译结果中的词汇的交互程度小,信息传递不充足,而这种交互在QE任务中可能会更加有效.
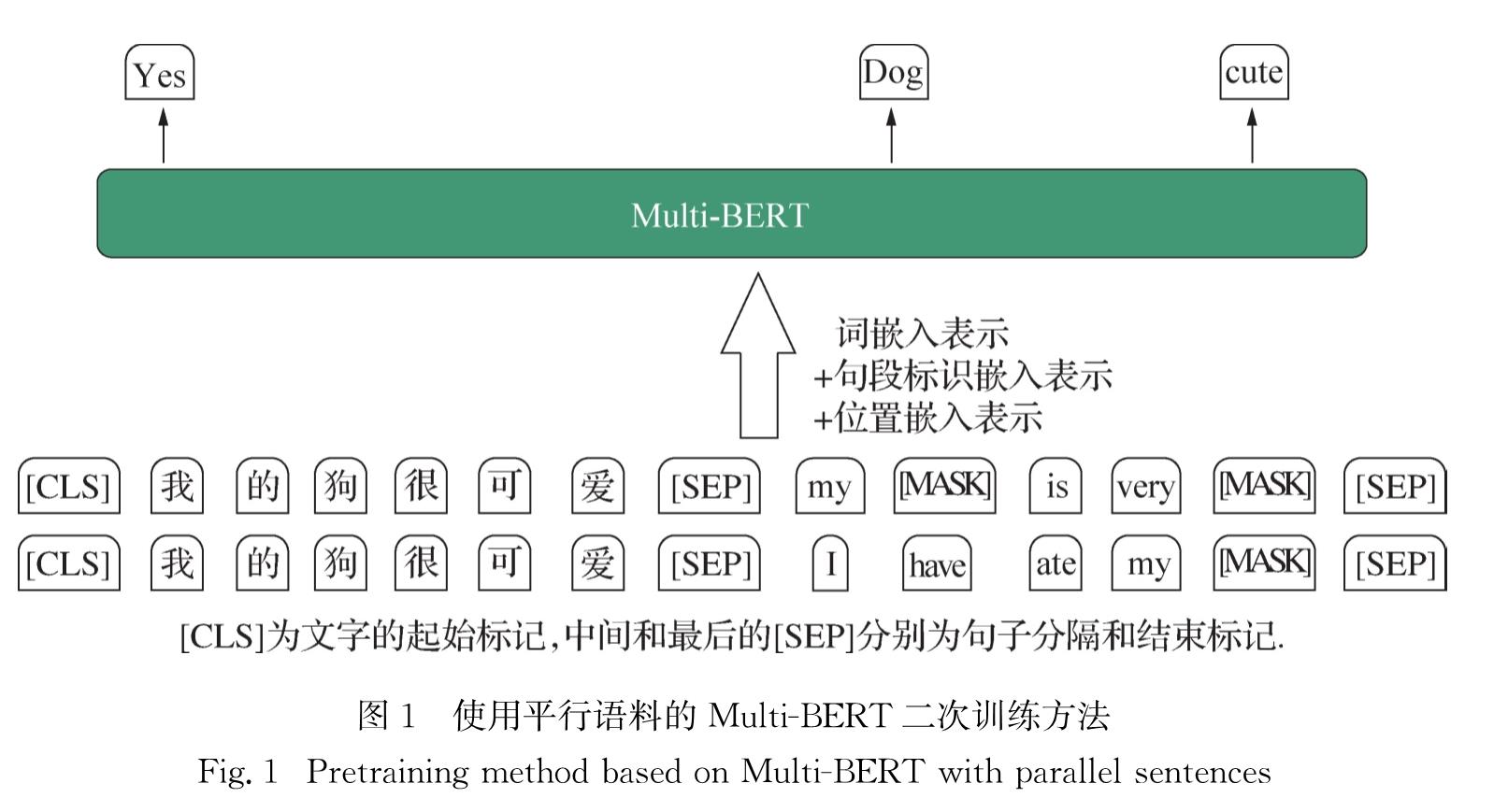
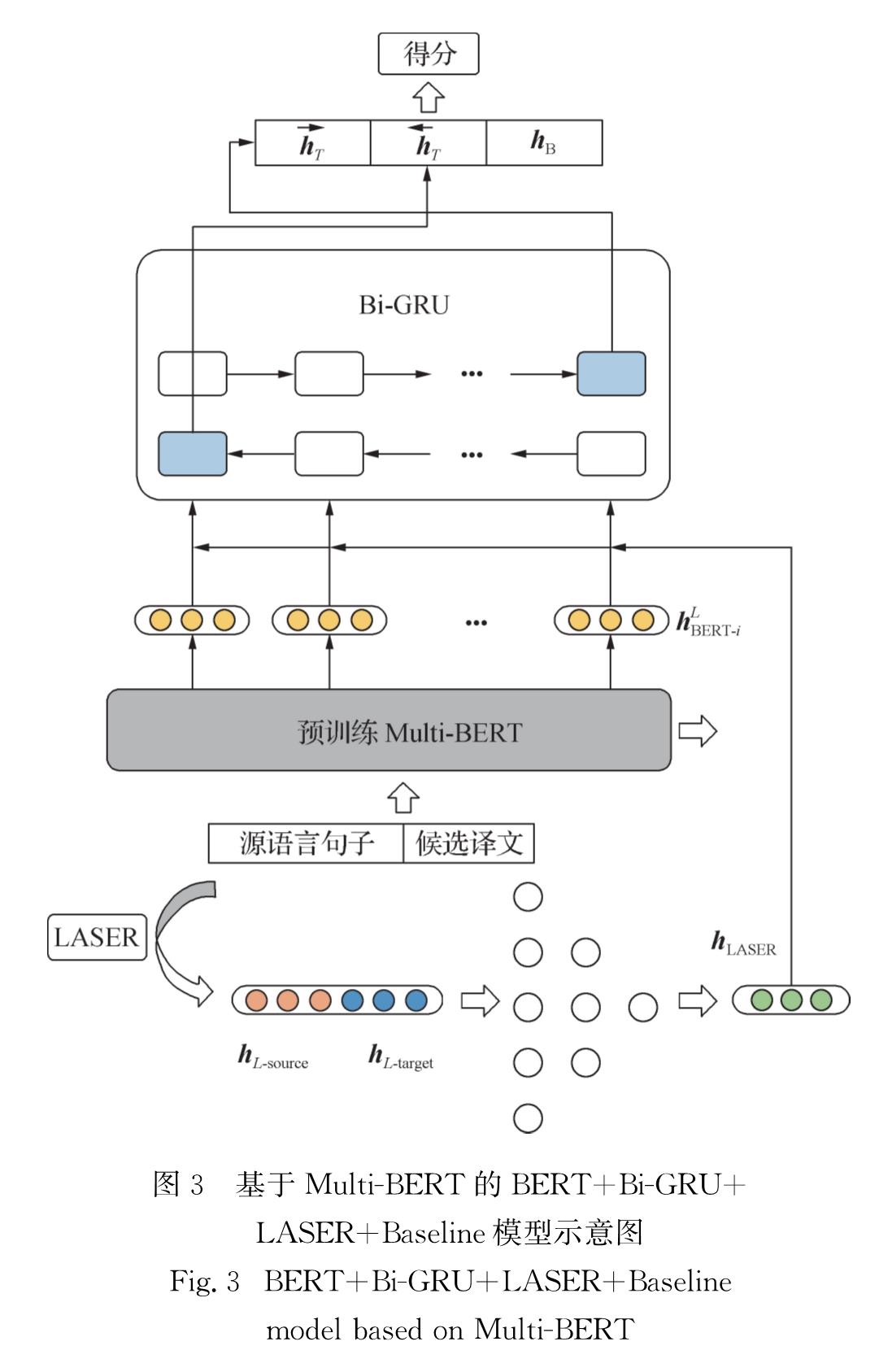
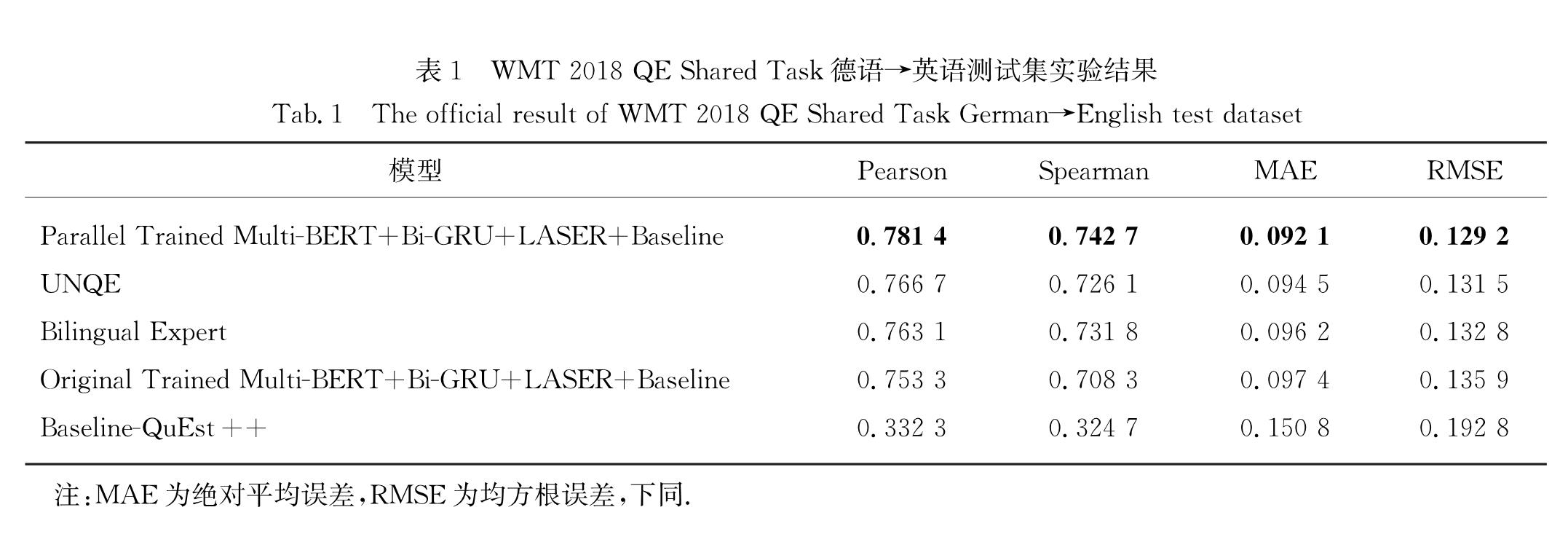
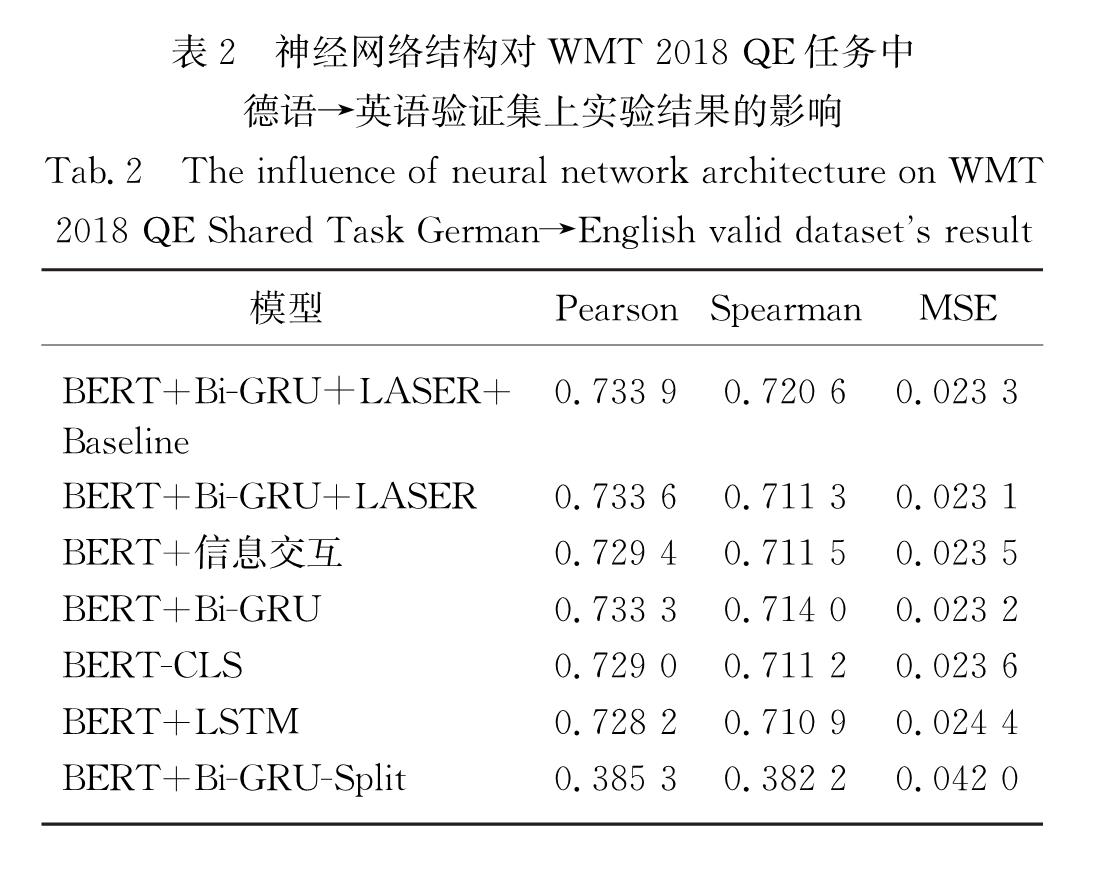
随着EMLo(embeddings from language models)[16]、GPT[17]、BERT(bidirectional encoder representations from Transformers)[18]等预训练语言模型的出现,多语言预训练语言模型,如Multilingual BERT(下文简称Multi-BERT)、XLM[19]等也吸引了人们的注意.这些模型都基于一种能使输入句子内词汇(token)之间进行充分交互,以得到更好的词汇表示与句子表示的神经网络结构Transformer.因此,本研究提出了一种基于Multi-BERT和联合编码的预训练语言模型来完成句子级的QE任务,并使用多种不同的网络结构进行微调,以探究其对于BERT隐层状态的应用效率.