收稿日期:2019-03-08录用日期:2019-05-04
基金项目:国家重点研发计划(2016YFE0132100); 国家自然科学基金(61673289)
通信作者:xiangyuduan@suda.edu.cu
基金项目:国家重点研发计划(2016YFE0132100); 国家自然科学基金(61673289)
通信作者:xiangyuduan@suda.edu.cu
(School of Computer Science and Technology,Soochow University,Suzhou 215006,China)
neural machine translation; recurrent neural network; system combination; attention mechanism; gate mechanism
DOI: 10.6043/j.issn.0438-0479.201903015
为了提高机器翻译模型的泛化能力,基于神经机器翻译系统,将系统融合技术应用于模型训练过程.在神经机器翻译系统的基本结构——编码器-解码器结构的基础上,提出5种融合方法(平均融合、权重融合、拼接融合、门机制融合和注意力机制融合)分别应用于多个编码器-一个解码器的融合、多个编码器-多个解码器的融合和一个编码器-多个解码器的融合.在中英翻译任务上进行实验,相对于基准系统,系统融合方法改进的机器翻译模型的机器双语互译评估(BLEU)值最终提升了0.59~3.01个百分点.实验结果表明,系统融合能有效地提升译文质量.
To improve the generalization ability of the machine translation model, we have applied the system combination technology to the model training process based on the neural machine translation system.According to the encoder-decoder structure of the neural machine translation system, five combination methods are proposed,including average combination,weight combination, concatenation combination, gate mechanism combination and attention mechanism combination.They are applied to the combination of multiple encoders and one decoder,the combination of multiple encoders and multiple decoders and the combination of one encoder and multiple decoders,respectively.Subsequently,the method is applied to the Chinese-English translation task.Compared with the benchmark system,the BLEU value of the machine translation model improved by the system combination method is finally increased by 0.59-3.01 percentage point.Experimental results show that the system combination can effectively improve the translation quality.
机器翻译(machine translation, MT)指的是将一种语言自动翻译到另外一种语言的过程.传统系统融合方法大多基于统计机器翻译(statistical machine translation,SMT),大致包括3种类型[1-3]:句子级别的系统融合、短语级别的系统融合和词汇级别的系统融合,主要关注于对多系统的翻译假设和单个系统的搜索空间建立潜在的映射关系[4],过程往往比较复杂.近年来,神经机器翻译(neural machine translation,NMT)的提出[5-7],显著地提升了MT的性能,不同于SMT,NMT主要使用编码器-解码器结构,框架清晰有序,更有利于系统融合.
在机器学习中,相同的结构使用不同的初始化参数训练,能够得到不同的预测模型.但模型不能完全匹配真实函数,每个模型都会犯错.实验表明[8],不同模型不一定会在相同地方犯同样的错误,若集成多个系统,则能够提高模型的泛化能力,同时扩大了假设空间,有利于模型逼近真实函数.因此系统融合通常会得到比单个模型性能更好的表现.
现有的NMT系统融合方法主要分为2种:一种是基于编码器的融合,主要是融合源端的上下文信息[9-10]; 另一种是基于解码器的融合[11],该方法将目标端的训练看成词序列预测任务,结合多个解码器预测概率来预测下一个时刻的翻译.
NMT的系统融合方法大多应用于多语言翻译任务上.Zoph等[9]在源端使用多个编码器,每个编码器对应不同的输入语言,目标端包含一个解码器,用源端各编码器的最后一个状态的和来初始化目标端隐藏层,同时将目标端的状态隐藏层向量和源端上下文向量拼接得到目标端注意力隐藏层向量.Firat等[10]在输出层对不同语言生成的目标端词汇概率分布进行算数平均,来减小模型预测错误的概率.Garmash等[11]则通过门机制来动态地控制模型对目标端概率预测的贡献.Zhou等[12]结合SMT系统和NMT系统的特性,对系统生成的上下文向量通过注意力机制加权平均,该方法融合了SMT的准确性和NMT的流畅性.
与上述方法不同,本文中在单一的平行语料上,对系统融合的方法进行了分类扩展.本研究将系统融合分为3种:多个编码器-一个解码器(N -1)融合、多个编码器-多个解码器(N-N)融合和一个编码器-多个解码器(1-N)融合.在这3种结构基础上,应用5种融合方法在中英数据上进行测试,并与已有的融合方法比较.
本文中的基准系统是基于循环神经网络的NMT系统[6].具体结构如图1所示.
编码器通过双向循环神经网络将源端输入序列X=[x1,x2,…,xi,…,xn]编码成隐藏层序列H=[h1,h2,…,hi,…,hn],其中xi是词嵌入向量,n为源端句子长度,hi由双向隐藏层向量hi^←和hi^→拼接得到,常用的循环神经网络为门循环单元(gated recurrent unit, GRU)[13]或者长短期记忆网络(long short-term memory,LSTM)[14].
解码器预测目标端词汇的概率分布,目标端词汇概率分布p(yt|y<t; X)通过注意力隐藏层向量st~转换得到,st~由上下文向量ct和目标端状态隐藏层向量st拼接得到,具体公式如下:
st~=tanh(Wc[st; ct]),(1)
p(yt|y<t; X)=softmax(Wyst~),(2)
其中:Wc和Wy是系统参数; 上下文向量ct通过Luong等[7]提出的全局注意力机制方法计算得到,由图1中的注意力机制层实现.用源端隐藏层的最终状态来初始化目标端的循环神经网络.
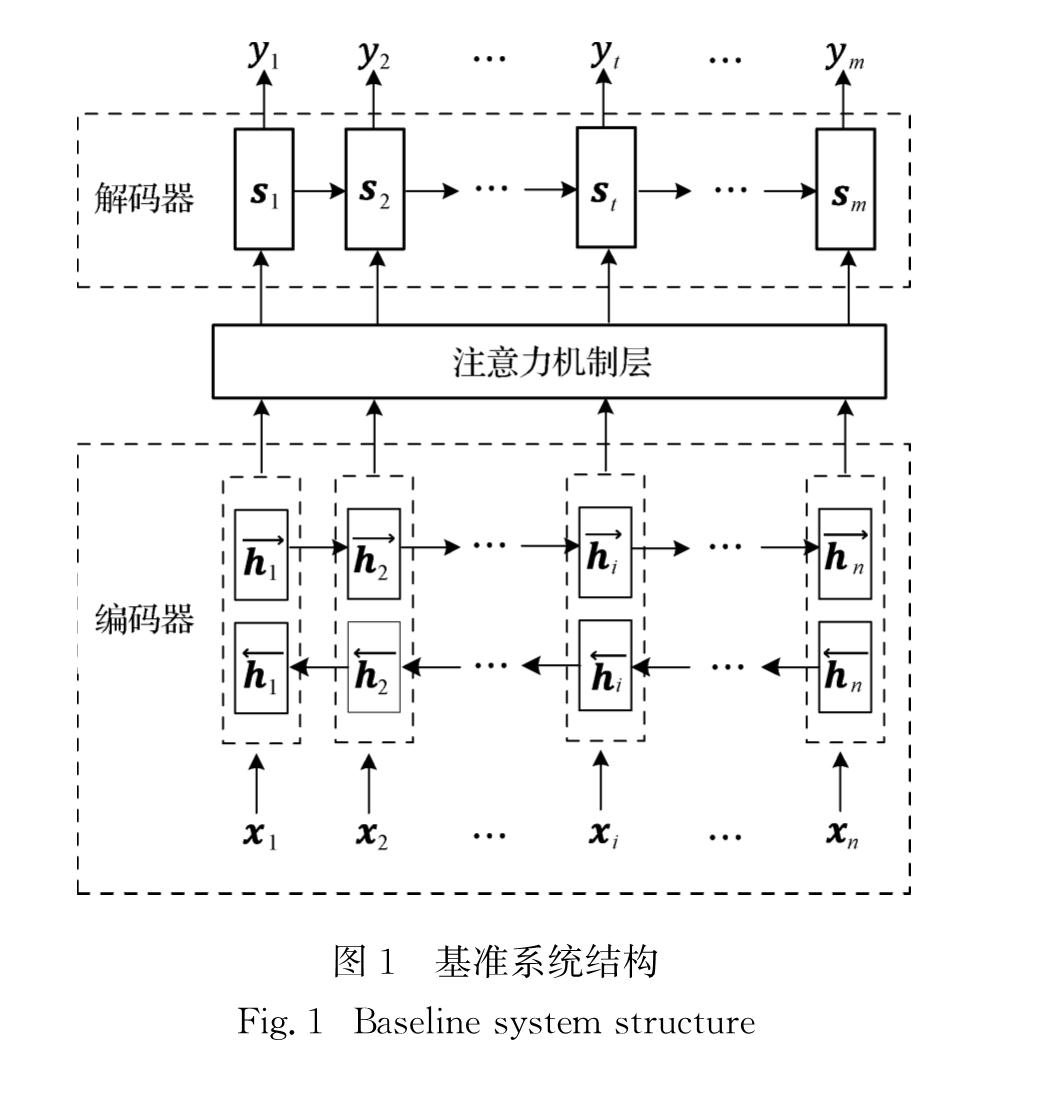
图1 基准系统结构
Fig.1 Baseline system structure
本文中基准NMT系统的结构可简化为如图2所示.编码器首先将源端输入X编码成隐藏层向量,其次系统通过注意力机制得到源端与目标端的上下文信息ct,最后解码器根据目标端的注意力隐藏层信息预测词汇y.

图2 基准系统结构简略图
Fig.2 Brief diagram of baseline system structure
本研究集成多个相似结构的翻译系统,每个系统使用不同的模型参数初始化.系统融合有效的前提是:所有的模型必须相对准确且不同[15].相对准确的模型是指对于新的数据,该模型的预测结果比随机预测的好,模型不同则为对单词的预测结果不一致.在此前提上,根据融合对像的不同,本文中将系统融合分为3类: N-1融合, N-N融合, 1-N融合.具体融合方法介绍如下.
图3展示了N-1融合的系统框架,X为输入,N为编码器的个数,cit表示第i个编码器与目标端解码器之间的上下文向量.每个编码器由预训练的基准模型初始化,任选某个模型的解码器初始化该融合系统中的解码器.相同的源端输入经由不同模型的编码器编码后,得到不同的源端信息; 每个模型的神经网络参数不同,学习到的源端编码信息也就不同.基准系统的编码器并不能完全准确地抽取源端信息,导致注意力信息存在错误,而不同的模型不会在相同的地方犯错,融合多个编码器在一定概率上会校正注意力信息,从而改善目标端的预测效果.本节选择融合上下文向量来实现编码器的融合,具体介绍5种融合方法.

图3 N-1融合框架
Fig.3 Combination framework of N-1
系统融合中最基本的方法是平均,本文对多个编码器生成的上下文向量进行算术平均,得到融合后的上下文向量:
ct=(∑Ni=1cit)/N.(3)
由于网络参数初始化不同,编码器编码的源端信息也就有差异,平均融合对于不同编码器的贡献判定过于简单,而每个编码器的权重大小不能直接决定,需要通过神经网络学习得到:
ct=w1c1t+w2c2t+…+wNcNt.(4)
其中:w1,w2,…,wN是权重参数,参与网络训练,将本文中权重参数随机初始化,大小在0~1之间,各权重之和为1.
拼接融合是一种非线性组合方法,是将上下文向量拼接得到源端联合信息,再经过一层线性变换后使用tanh函数激活,对上下文向量进行压缩:
ct=tanh(Wz[c1t; c2t; …; cNt]).(5)
其中:Wz∈Rp×Np,p是单个编码器的上下文向量维度.
进一步,本研究尝试用门机制动态地控制权重分布,对于不同的上下文信息,通过非线性单元转换后再使用softmax()函数归一化当前上下文向量的权重比例,再经过算术平均捕获隐藏的句法信息,为目标端的预测提供深层翻译信息.具体公式为:
ct=∑Ni=1zitcit,(6)
zt=softmax(Wgut+bg),(7)
ut=tanh(Wq[c1t; c2t; …; cNt]+bq).(8)
其中:Wg∈RN×l,Wq∈Rl×Np,为权重向量,l为门向量维度; bg和bq为偏置向量.实验中,l根据经验设为250.
最后,本研究尝试注意力方法的动态融合.该方法基于注意力机制,由目标端状态隐藏层st把控源端各上下文向量对目标端的贡献权重.计算式如下.
ct=∑Ni=1αt icit(9)
αti=(exp(eti))/(∑Nj=1exp(etj)),(10)
et i=sTtWacit.(11)
其中:Wa∈Rq×p,为权重向量,q是目标端状态隐藏层维度.
N-1融合只结合多个源语言信息来预测目标端词汇,进一步在编码器学习到源语言信息并通过注意力机制传递给解码器后,本文中融合解码器的注意力隐藏层信息来进行单词预测.图4为N-N融合的系统框架,系统中相同编号的编码器、解码器分别由同一模型里的编码器、解码器初始化,不同模型之间的编码器和解码器互相独立.具体采用以下4种融合方法进行实验.
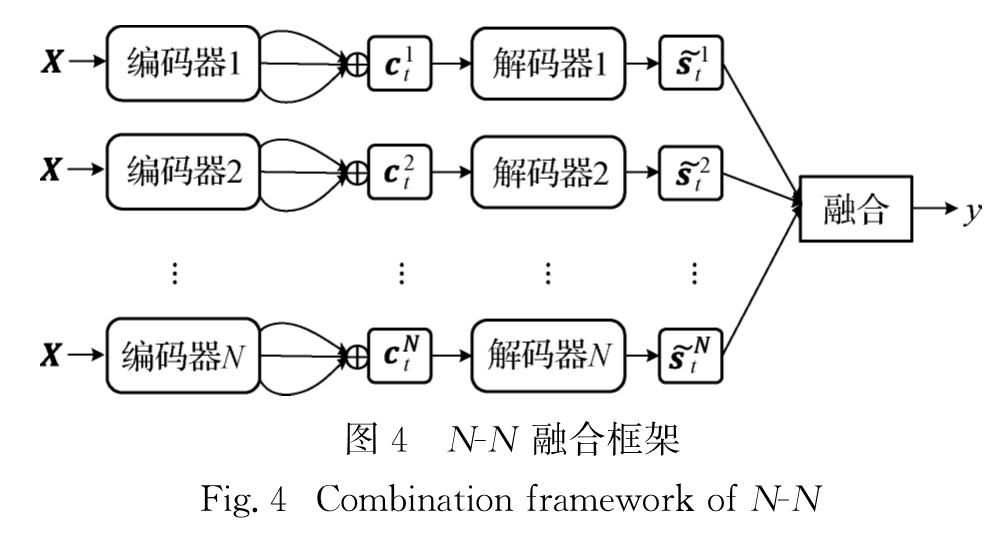
图4 N-N融合框架
Fig.4 Combination framework of N-N
该方法均衡每个解码器的注意力隐藏层信息来预测目标端词汇概率分布:
s~t=(∑Ni=1s~it)/(N).(12)
其中,st~i是第i个解码器的注意力隐藏层向量,st~i=tanh(Wci[sit; cit]).
每个解码器的注意力隐藏层捕捉到的目标语言信息不同,对目标端词汇的预测也就不一样,赋予每个隐藏层不同的权重来得到一个综合的预测:
st~=w1st~1+w2st~2+…+wNs~Nt.(13)
其中,w1,w2,…,wN是权重向量,参与训练.
本节拼接融合与2.1.3节相似,将目标端注意力隐藏层拼接在一起,经过非线性变换之后得到融合后的注意力隐藏层信息:
st~=tanh(Ws[st~1; st~2; …; st~N]).(14)
其中:Ws∈Rq×Nq,为权重向量.
与权重融合不同,门机制融合根据各解码器注意力隐藏层信息决定权重分布,且权重和为1,公式为:
st~=∑Ni=1ztist~i,(15)
zit=softmax(Wiguit+big),(16)
uit=tanh(Wio[st~1; st~2; …; st~N]+bih).(17)
其中:Wig∈RN×l,Wio∈Rl×Nq,实验中l设为250; bih为偏置向量.
此外,本文中继续尝试了当源端只有一个编码器传来的信息时,目标端的解码器是否能够据此学习到不同的语言信息.图5是1-N融合的系统框架,通过集成目标端多个注意力隐藏层信息来综合预测目标端词汇,本节使用与2.2节相同的融合方法.
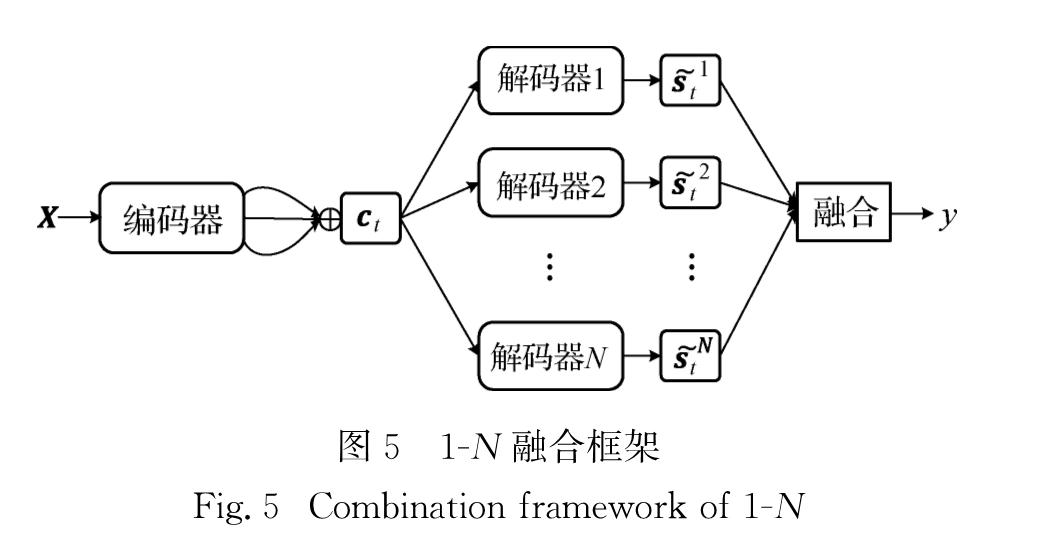
图5 1-N融合框架
Fig.5 Combination framework of 1-N
与2.2节不同的是,本节源端只有一个编码器,随机由某个基准模型的编码器初始化; 目标端则使用多个基准模型的解码器初始化,目标端多个解码器的循环神经网络均由该编码器的末端隐藏层初始化,且使用同一个上下文向量来生成不同解码器的注意力隐藏层向量st~i.
本研究在中英机器翻译任务上测试了系统融合的实验效果,使用multi-bleu.perl评测脚本给模型打分,使用大小写不敏感的机器双语互译评估(BLEU)[16]值作为评价指标.
本研究的训练集是从语言数据联盟(linguistic data consortium,LDC)里抽取的125万句中-英平行语句对,其中包括LDC2002E18、LDC2003E07、LDC2003E14、LDC2004T07、LDC2004T08和LDC2005T06中的议会议事录部分.选择NIST MT 02、03、04、05、08为测试集,NIST MT 06为验证集.
本文中使用开源的NMT系统Fairseq(https:∥github.com/pytorch/fairseq)训练基准模型,其循环神经网络采用LSTM.预处理语料时,对中文做分词处理,对英文做tokenization处理.词汇表大小设置为3×104,这3×104个高频词分别覆盖了97.7%的中文词汇和99.3%的英文词汇.训练时,词嵌入向量的维度、源端和目标端的隐藏层维度、上下文向量的维度都设置为512,使用Nag优化算法, 神经元随机失活率(dropout)大小为0.2,系统的初始学习率是0.2,当学习率小于2.5×10-5时,程序停止训练.解码时,采用集束搜索方法(beam-search),其中beam大小设置为10,其他参数使用Fairseq默认参数.融合2个基准模型来测试本文中提出的方法.特别说明的是,在N-N融合系统和1-N融合系统的融合过程中,融合后的注意力隐藏层向量st~需要调用激活函数.集成系统初始化时,对用于生成单词概率分布的向量,不借助基准模型参数初始化,而使用随机初始化重新训练.
本文首先训练了2个基准模型来进行系统融合实验,基准模型的得分如表1中的基准系统1和基准系统2所示,并平均2个系统的得分得到平均基准系统,作为本文的对比基线.表1中的融合测试为本文中复现的Jean等[17]提出的在测试时融合多个模型的概率来预测译文的方法,实验中该方法的BLEU值比平均基准系统提高了1.44个百分点.
表2是N-1融合的实验结果,可以看出:
1)本文中提出的5种融合方法,与平均基准系统相比,翻译质量都有一定的改善,其中注意力机制融合
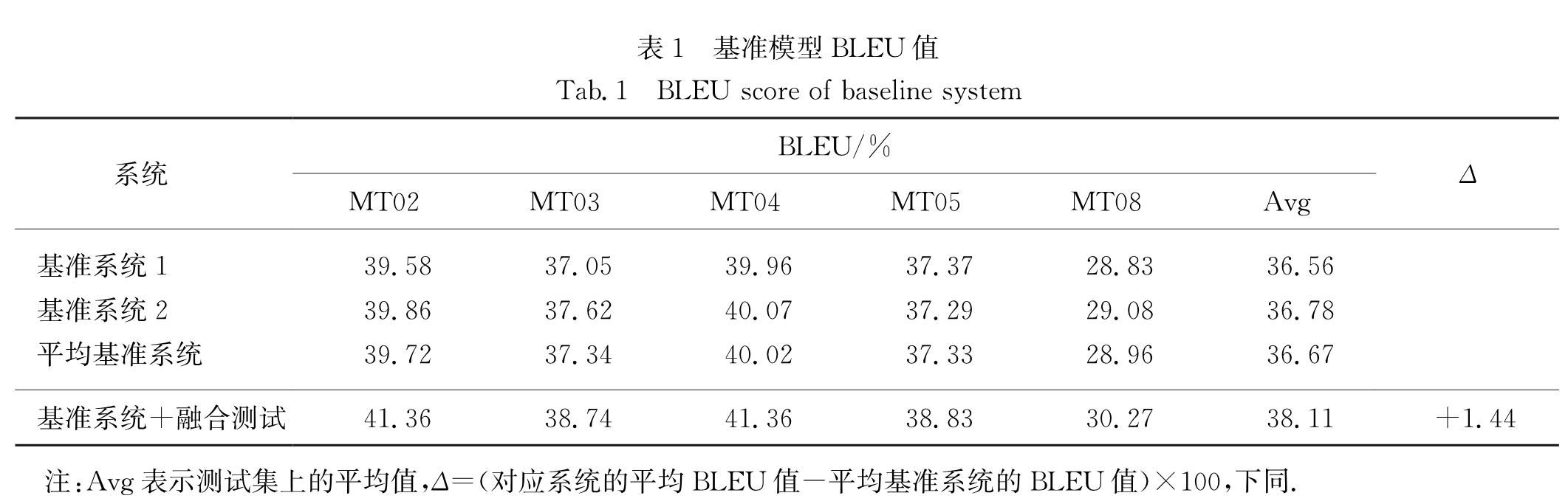
表1 基准模型BLEU值
Tab.1 BLEU score of baseline system
注:Avg表示测试集上的平均值,Δ=(对应系统的平均BLEU值-平均基准系统的BLEU值)×100,下同.

表2 N-1融合的实验BLEU值
Tab.2 BLEU score of combining N-1
注:Zoph等[9]为本文中复现的文献[9]提出的在多元MT中,将源端的多个编码器生成的上下文向量与目标端的状态隐藏层拼接在一起,得到注意力隐藏层的实验,该方法属于N-1融合.
方法最有效,其BLEU值比基线系统提高了1.09个百分点;
2)5种融合方法中,门机制融合方法和注意力机制融合方法的实验效果,均优于Zoph等[9]提出的方法;
3)此外,通过注意力机制融合方法训练出2个模型后,在测试时融合2个模型的预测概率,能更大地提升翻译质量,BLEU值相比于平均基线系统有2.55个百分点的提升.
表3是N-N融合的实验结果,可以看出:
1)4种融合方法中,拼接融合最为有效,其BLEU值相比于平均基准系统提升了2.05个百分点;
2)与Garmash等[11]方法相比,本文的N-N融合上的译文质量只有微弱的提升;
3)使用拼接融合方法训练得到多个模型后,在测试时融合多个模型的预测概率,同样会提升译文质量,相比于平均基准系统BLEU值最终提升了3.01个百分点.
表4是1-N融合的实验结果,可以看出:
1)1-N融合系统通过本文的融合方法,能够提升翻译质量,其中权重融合提升最明显,有1.41个百分点的BLEU值提升;
2)在测试时集成2个权重融合的模型进行解码,相比于平均基准系统,同样能够有2.36个百分点的BLEU值提升.
由上述实验结果可以看出,本文中提出的融合方法,在中英MT任务上,与平均基准系统相比均有显著的提升,其中N-N融合系统对译文质量提升得最明显.并且,当源端只有一个编码器传来信息时,多个解码器也能够抽取出不同的信息,达到提升译文质量的效果.此外,在测试时融合多个模型解码,会得到更好的翻译效果.

表3 N-N融合的实验BLEU值
Tab.3 BLEU score of combining N-N
注:Garmash等[11]为本文中复现的文献[11]提出的通过门机制得到权重,作用于不同解码器生成的目标端词汇分布的实验,该方法属于N-N融合.

表4 1-N融合的实验BLEU值
Tab.4 BLEU score of combining 1-N
本文的融合方法对于不同的融合对象,其BLEU值均有提升,范围在0.59~3.01个百分点之间,5种融合方法的表现各有差异.从实验结果可以观察到:
1)在编码器的融合上,注意力机制融合方法表现最佳.我们分析是由于源端各编码器学习到的语言信息不同,通过注意力机制,让目标端隐藏层来决定源端信息与目标端的相关度,可以得到更准确的注意力信息.
2)对于解码器的融合
(i)若源端有多个编码器,则拼接融合解码器更为有效.猜测这是由于各模型间相互独立,编码器-解码器之间没有参数关联,非线性的融合可以得到更充分的信息.
(ii)若源端只有一个编码器,则使用权重融合效果更好.因为目标端共享源端语言信息,所以各解码器之间存在关联,使用权重融合更适合,同时扩大了假设空间,增大了翻译准确的概率.
本节将融合各编码器、解码器对应的最好融合结果的多元BLEU值进行对比.前文的BLEU值为一元、二元、三元、四元BLEU值的平均结果,本节选取一元BLEU值和四元BLEU值进行观察比较.一元BLEU值可以较好地衡量单词翻译的覆盖率,四元BLEU值可以较好地衡量系统对短语的翻译效果.结果如表5所示,可以看出,无论是单词的覆盖率还是短语的翻译效果,系统融合的表现均好于平均基准系统,其中N-N系统的拼接融合翻译的单词覆盖率最高,短语翻译的准确率也最高.
本节以长度间隔为10将测试集分为6类,在这6
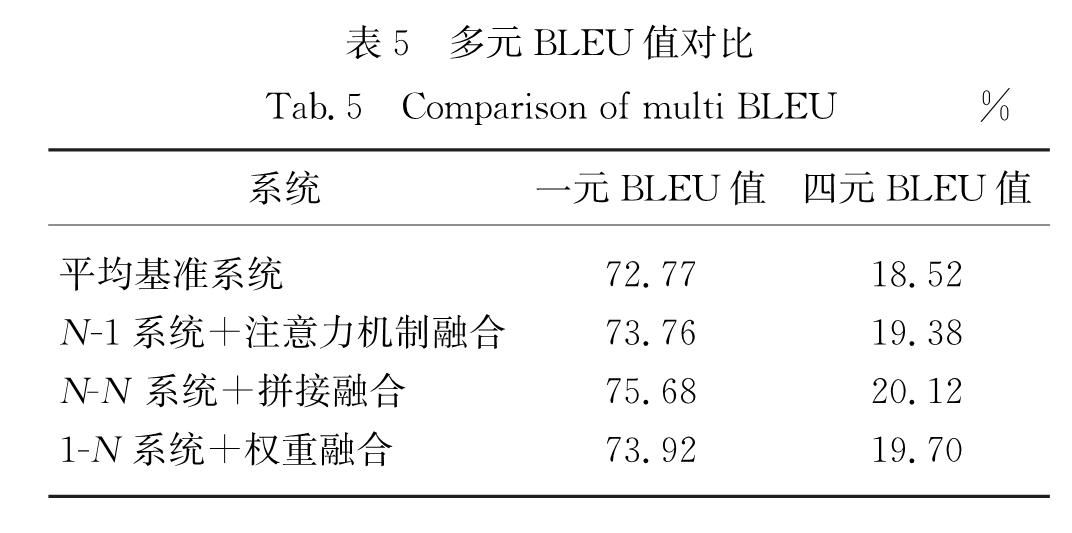
表5 多元BLEU值对比
Tab.5 Comparison of multi BLEU%
类长度不同的测试集上,分别对比了平均基准系统和融合不同编码器-解码器其对应的最好融合效果的模型在不同输入长度上得到的译文,结果如图6所示.可以看出,对于不同长度的句子,系统融合的翻译效果均好于平均基准系统.同时,N-N的拼接融合在不同句长上的译文表现都优于其他融合方法.从图中还观察到,当长度大于10时,随着句长增加,BLEU值在不断降低.分析原因,随着句子长度增加,循环神经网络里传递的信息有一部分被丢失,以至于长句子翻译往往不准确,这也是NMT中一直存在的问题,系统融合在长句子上的翻译效果表明,训练时融合多个模型的子结构可以一定程度上改善长句翻译问题.
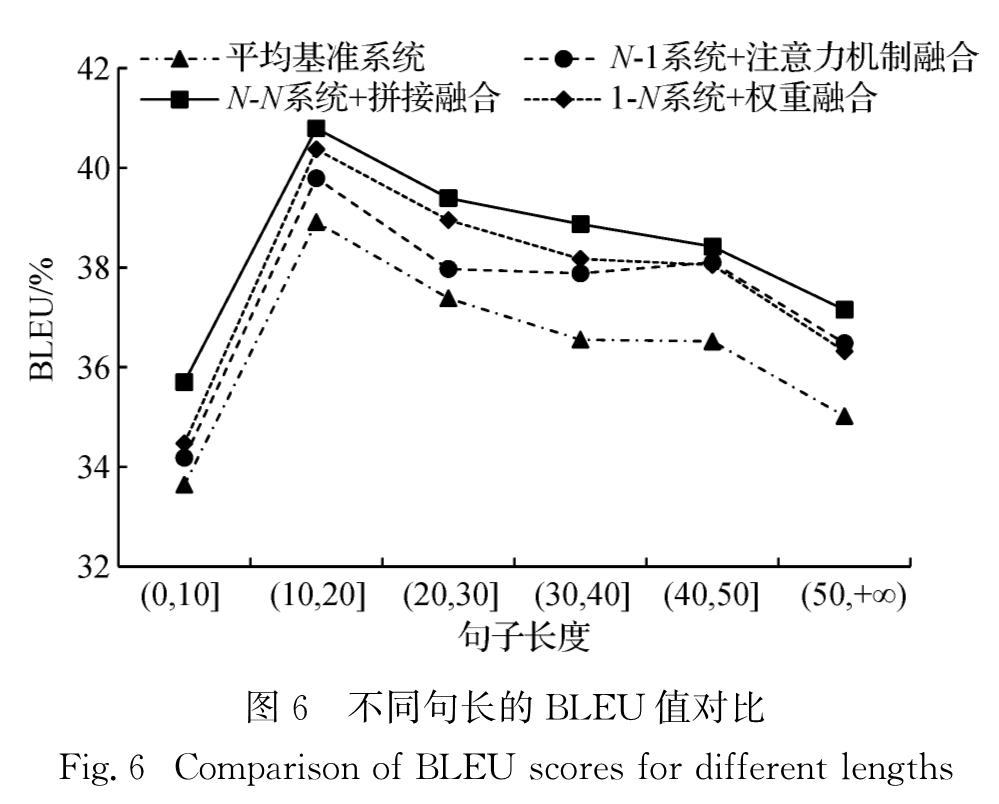
图6 不同句长的BLEU值对比
Fig.6 Comparison of BLEU scores for different lengths
本文的融合主要分为2类:编码器融合和解码器融合.编码器融合主要通过结合上下文向量完成,解码器融合通过结合目标端的多个注意力隐藏层词信息完成.
编码器融合让模型从多个角度学习源端语言信息,能够记忆更多源端信息,在长句子翻译上更有优势.因此,如图6所示,在不同句长的BLEU值对比中,当句子长度在1~50时,N-1融合的BLEU值比1-N融合的BLEU值低; 当句子长度大于50时,N-1融合的BLEU值超过1-N融合的的BLEU值.
解码器融合是根据各学习器的学习内容来进行综合预测,扩大假设空间,减少犯错概率,获得更高质量的译文.因此,如表5所示,在多元BLEU值的比较中,1-N融合的一元BLEU值和四元BLEU值均比N-1融合的高.
本文中探索了如何对基于循环神经网络的MT结构进行系统融合,提出了5种融合方法,分别在N-1,N-N和1-N系统上进行了实验,实验结果表明,在中英翻译任务上,在N-N系统上采取拼接融合提升效果最明显.
本文主要贡献如下:
1)按融合对象的不同,介绍了多种NMT系统融合方法,并对比了各种方法的有效性;
2)提出了1-N的新型融合结构;
3)本文提出的系统融合方法显著提升了中英数据的翻译效果,效果优于已有的基准系统融合方法.
本文中仅研究基于循环神经网络的MT系统融合方法,NMT系统还包括其他的结构,比如基于卷积的ConvS2S[18],使用自注意力的Transformer[19]等,在未来的工作中,将继续探索适用于不同NMT结构的系统融合方法.
