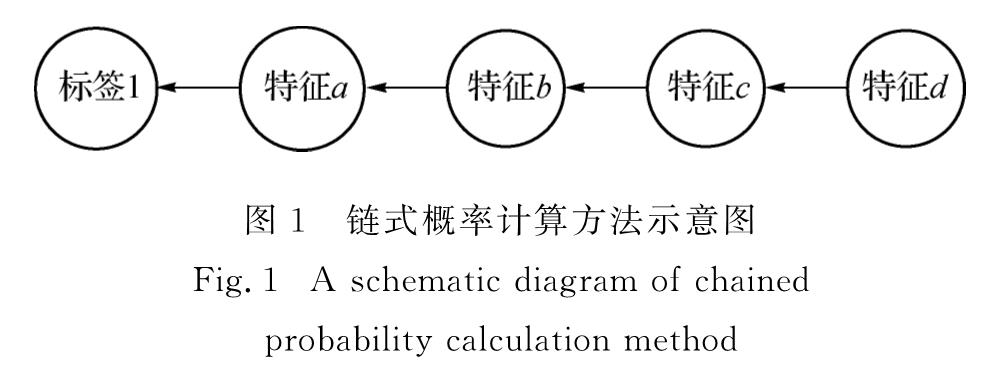
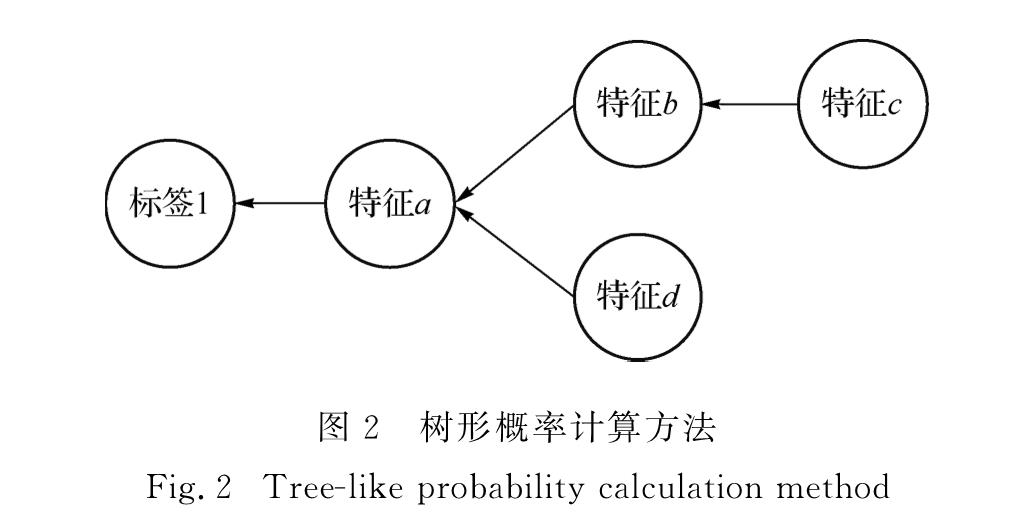
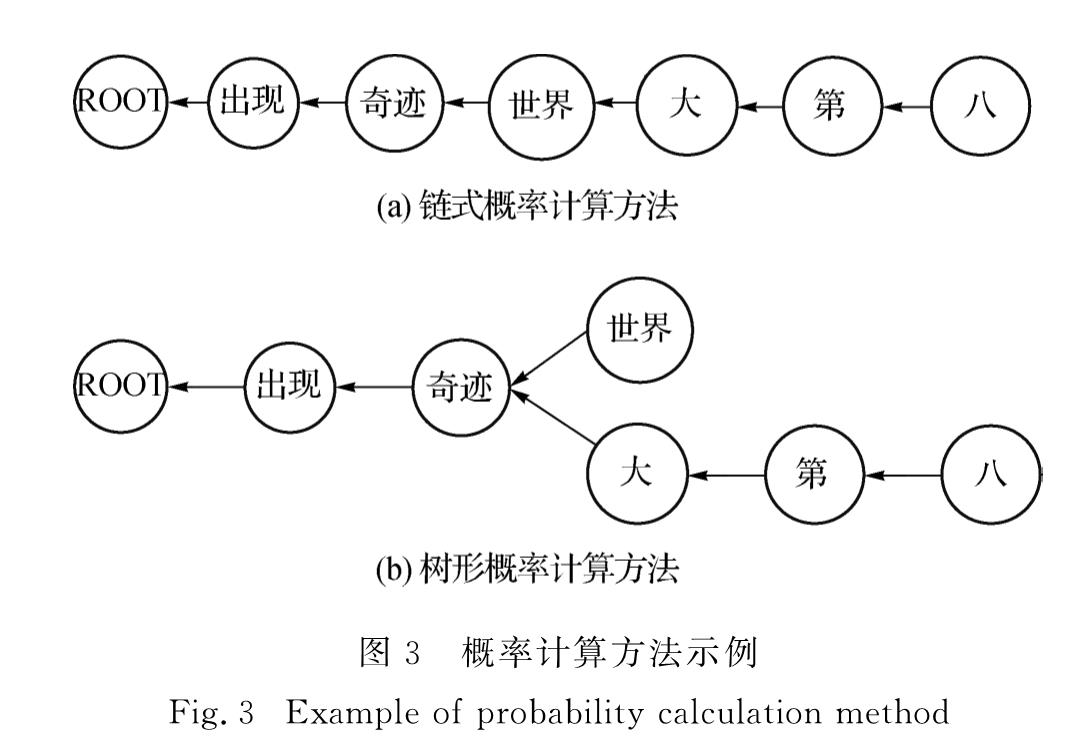
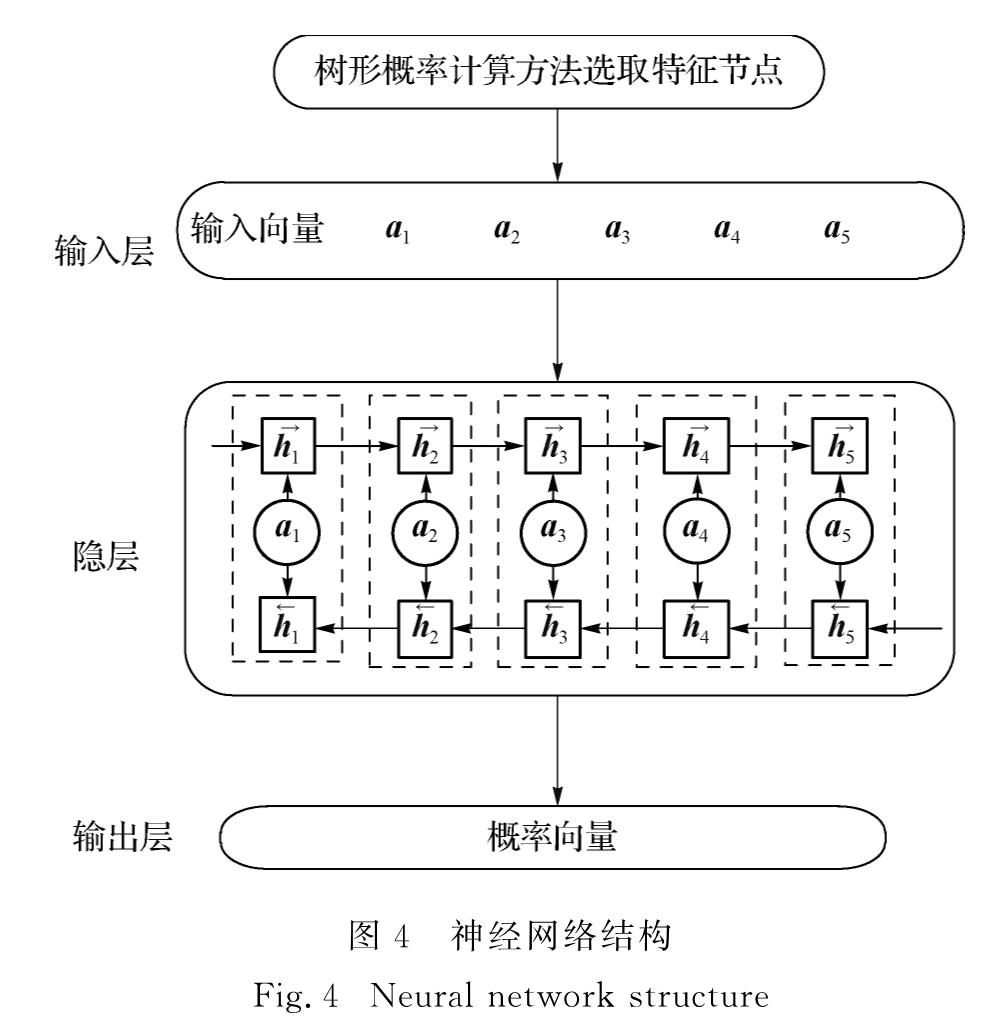
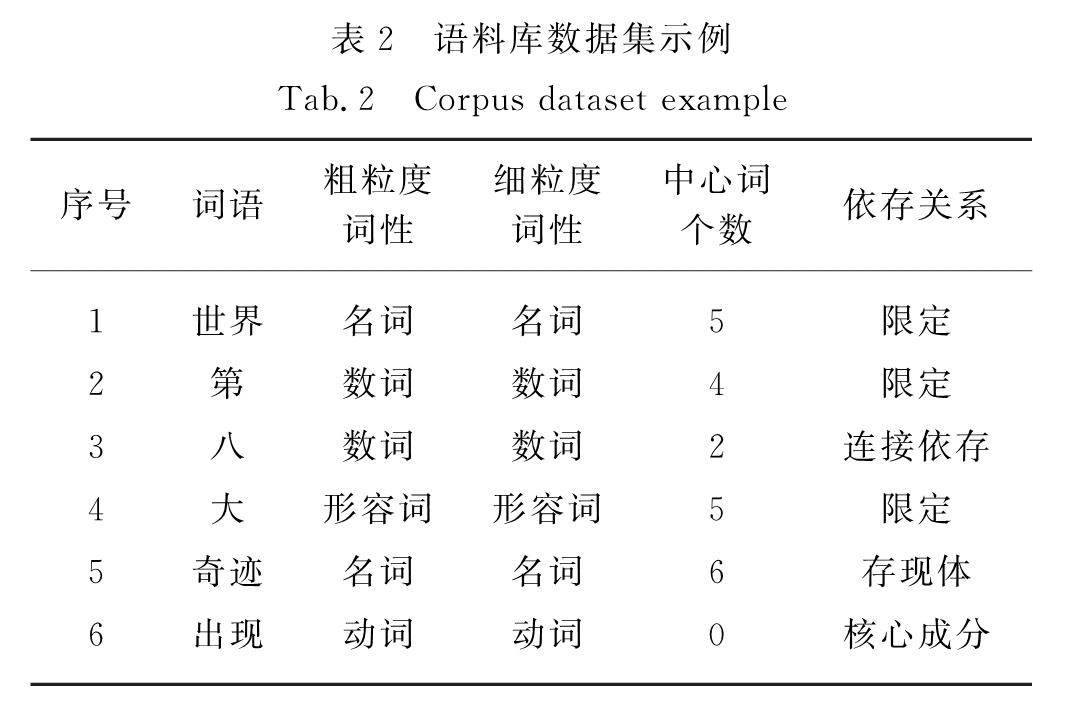
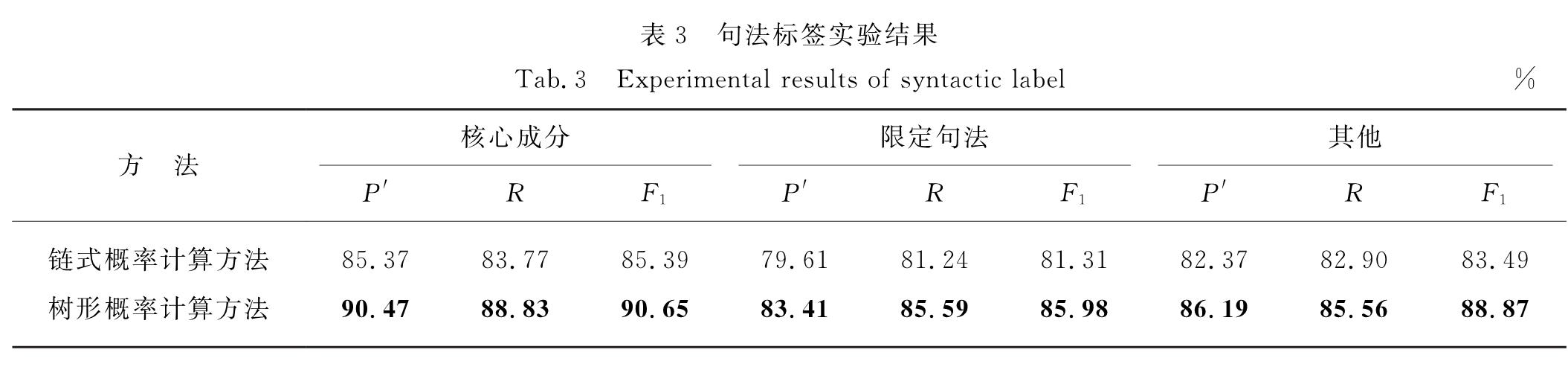
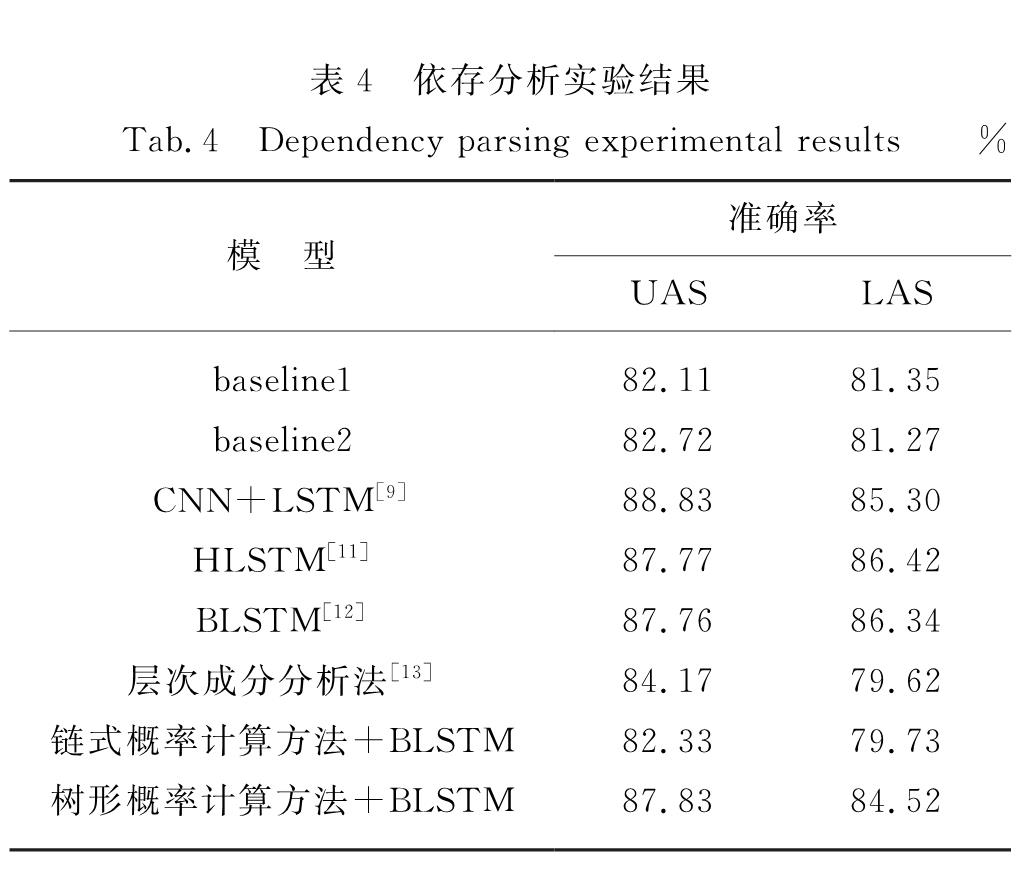
为有效解决数据的稀疏性问题,并考虑句法预测的内在层次性,提出了一个基于双向长短时记忆(bidirectional long short term memory,BLSTM)神经网络模型的渐步性句法分析模型.该模型将树形概率计算方法应用到对句法标签分类的研究中,利用句法结构和标签之间的层次关系,提出一种从句法结构到句法标签的渐步性句法分析方法,再使用句法分析树来生成句法标签的特征表示,并输入到BLSTM神经网络模型里进行句法标签的分类.在清华大学语义依存语料库上进行实验的结果表明,与链式概率计算方法以及其他依存句法分析器比较,依存准确率提升了0~1个百分点,表明新方法是可行、有效的.
In order to effectively solve the problem of data sparseness and inherent level of syntactic prediction,an incremental stepwise dependency parsing model based on bidirectional long short term memory(BLSTM)is proposed.This paper applying the tree-like probability calculation method to the study of syntactic tag classification,using the hierarchical relationship between syntactic structure and tag,proposes a step-by-step syntactic analysis method from syntactic structure to syntax tag,using syntactic analysis tree to generate the characteristics of the syntactic tag which are input into the BLSTM model to classify syntactic tags.Compared with other syntactic analysis methods and chained probability calculation method on the Semantic Dependency Corpus dataset of Tsinghua University,the dependency accuracy rate is improved by 0-1 percent.It shows that the new method is feasible and effective.