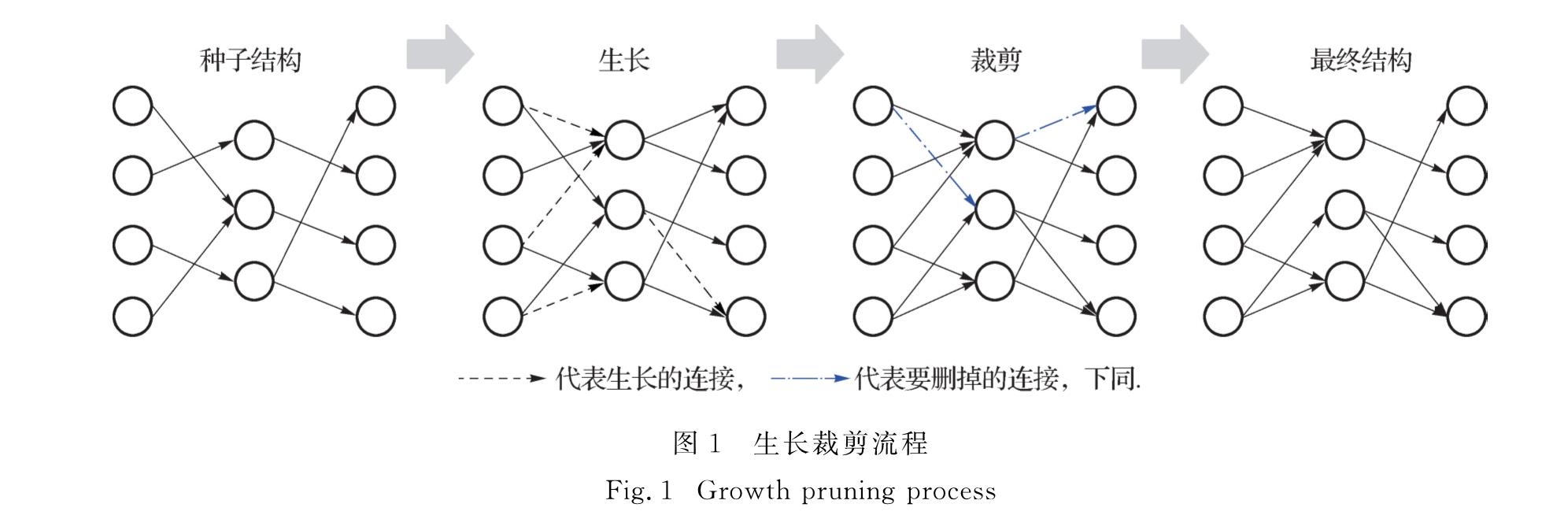
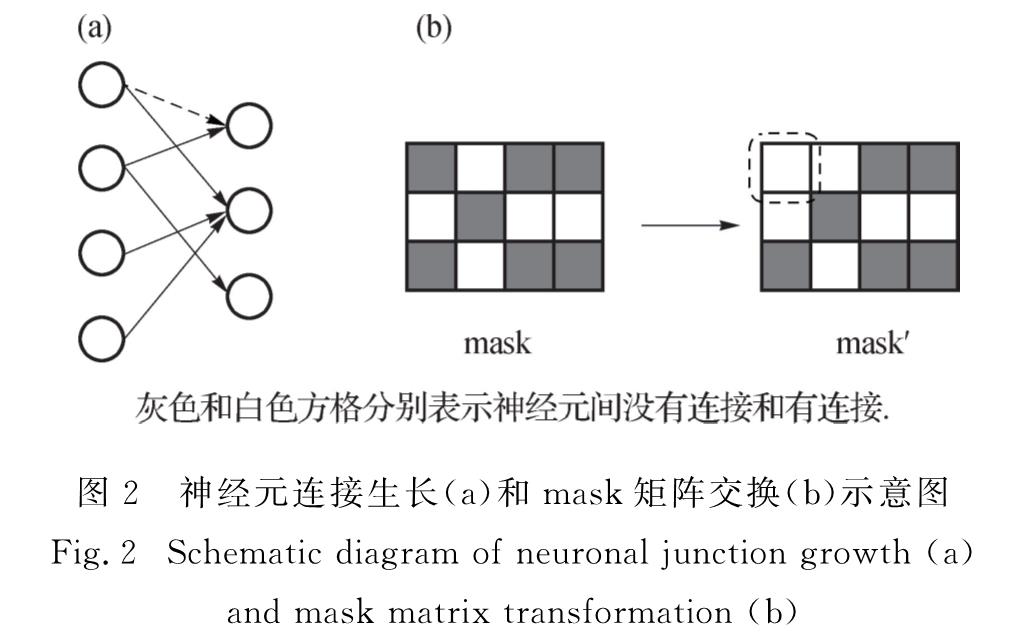
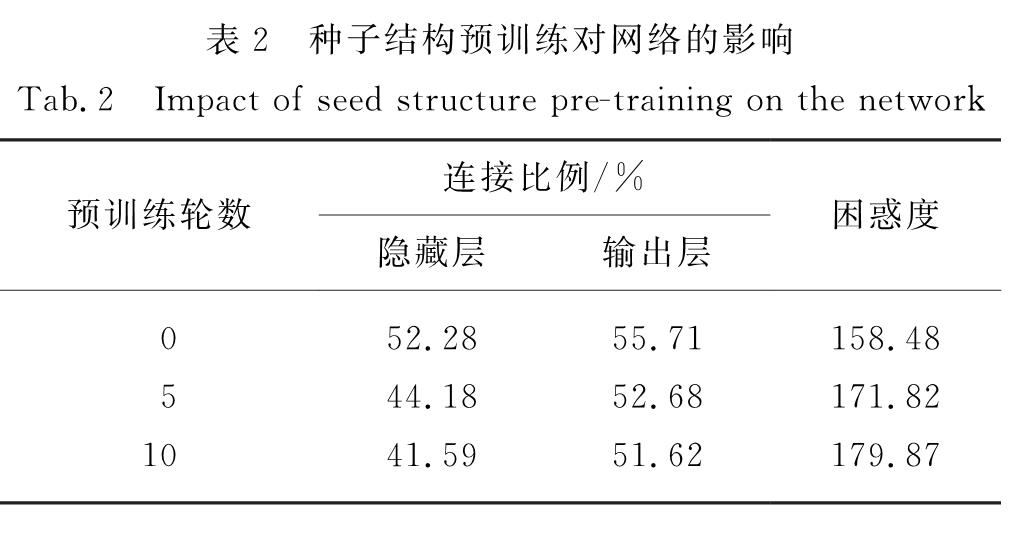
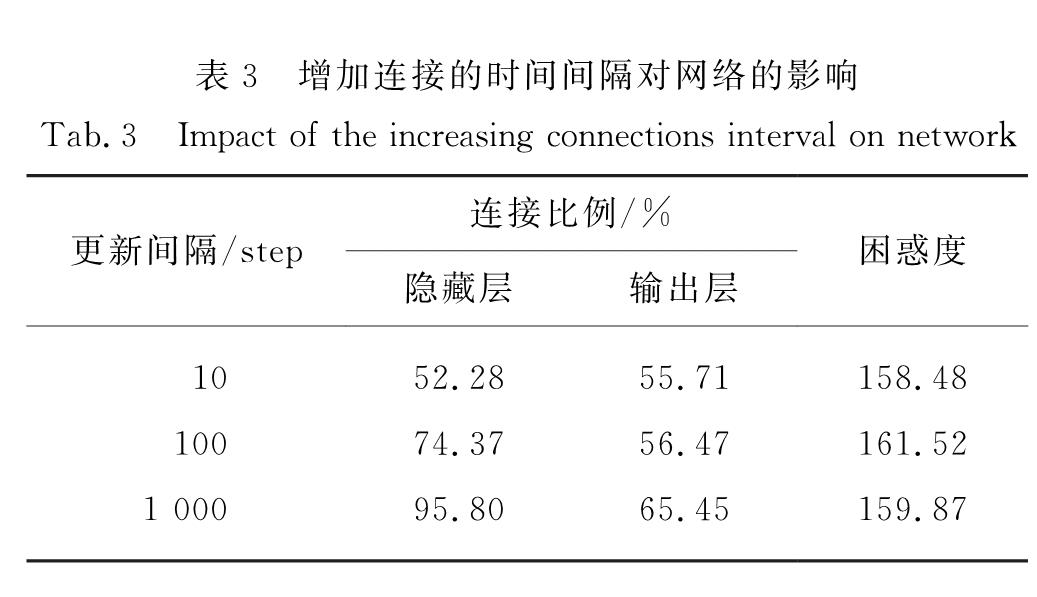
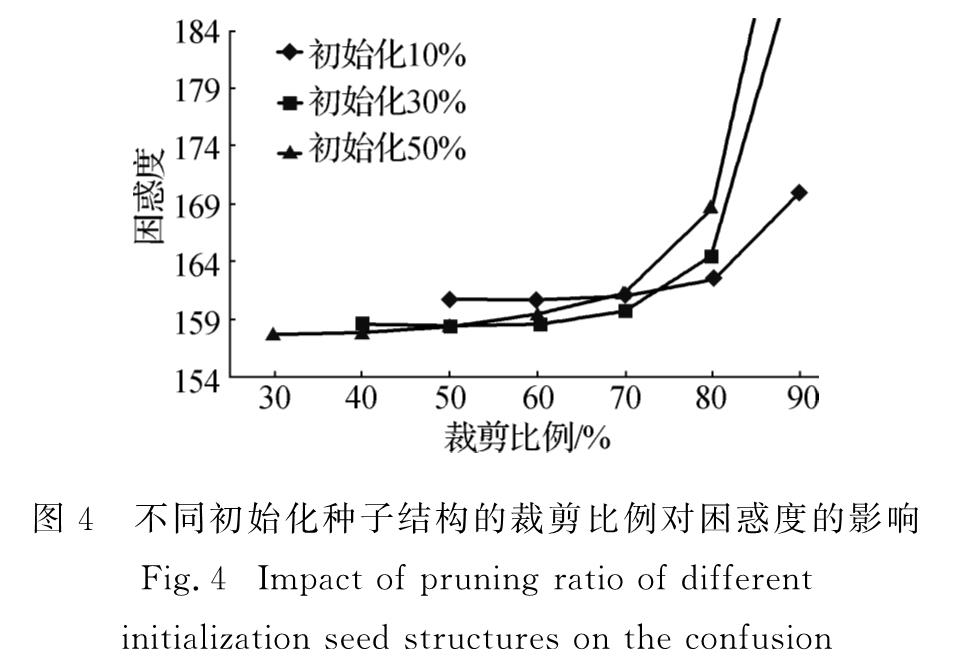
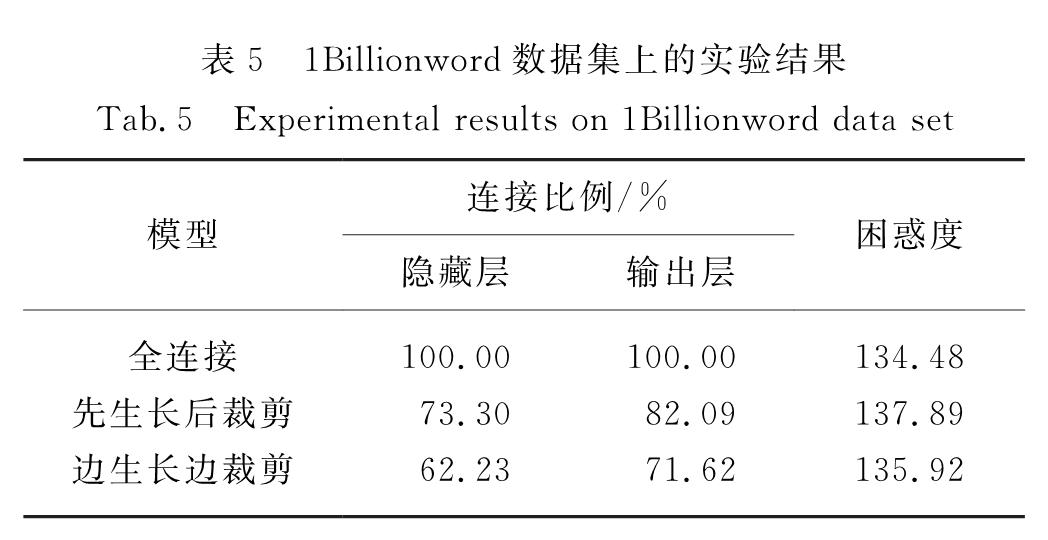
基于神经网络的模型是目前自然语言处理中广泛使用的框架,与传统神经网络一样,这类模型的最基本单元是神经元,神经元之间连接组成层,层和层之间连接构成网络.神经网络结构有很多种,大部分是根据先验知识进行人工设计的网络结构(如前馈神经网络和循环神经网络),进而通过训练网络参数来优化整个网络.这些网络结构在很多任务中都取得了很好的效果,如语言模型[1]、机器翻译[2]、语音识别[3]、图像分类[4]等.这得益于其规模庞大的多层神经元结构,层与层之间采用全连接,模型参数量大,模型性能优越.但其网络结构也存在大量冗余[5],而且人工设计的网络结构不容易捕捉神经元之间的关系,未考虑模型训练过程中神经元连接的动态变化过程,网络结构的表示并不高效.一般来说,增加网络结构的复杂度可以有效提升模型本身的表达能力,从而提升神经网络在各种任务中的性能.但许多研究人员也提出,实际上过于复杂的网络结构并不能对模型性能产生实质上的提升,反而会出现训练过程缓慢、计算存储资源消耗大等情况.
为了得到更加紧凑、有效的神经网络,研究人员提出了剪枝等模型压缩方法[6],基本思想是裁剪掉一些不合理、低权重的连接.通过剪枝模型结构,将全连接裁剪为较稀疏结构,可以得到紧凑的网络结构.最初Thodberg等[7]提出了使用剪枝的方法对网络中部分非重要的连接进行删减的策略,其核心思想在于通过网络连接重要性判别、剪枝、重训练3个步骤的结合,在对网络参数进行训练的同时对其中的冗余连接进行合理剔除,在不损伤性能的前提下缩小网络结构.之后Han等[8]、Nabhan等[9]、Kadetotad等[10]又从剪枝模式角度对该方法进行了改进,在原有的剪枝策略基础上融合了哈夫曼编码以及量化的模型压缩策略,最终在AlexNet网络结构上达到了35倍的压缩效果.然而,这类方法与网络的训练无关,不是通过学习得到的,而是通过一些外部指标直接对模型进行裁剪.由于其剪枝方法的操作对象为一个经过训练的网络结构,需要对其中连接的合理性进行探索,所以Mézard等[11]从模型生长的角度使用更小的结构对问题进行建模、求解,其采用一种增量式的方法改进结构,从小模型开始,通过不断尝试逐渐向其中增加能使模型性能提升的新的节点和层结构,最终获得更加紧凑的网络结构.近些年研究人员发现,模型生长和剪枝方式的结合相较于单一使用其中任意一种方法对于网络结构的学习都更有助益.2017年,Dai等[12]提出将生长和剪枝的方式进行结合,同时利用网络训练过程中的梯度信息对其进行指导,使得其所获得的模型参数量更小,并在图像识别任务中相对基线系统取得了更优秀的成绩.
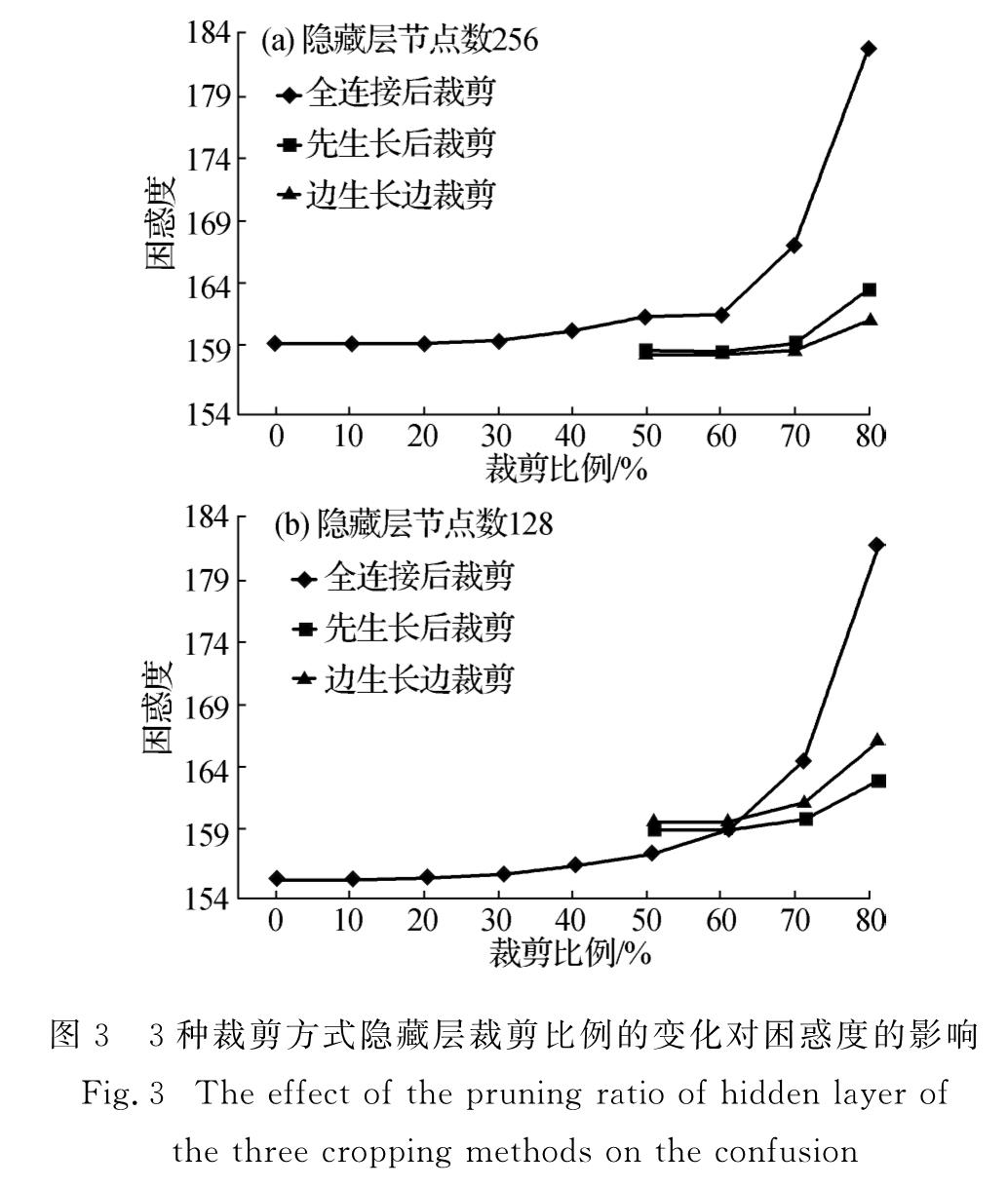
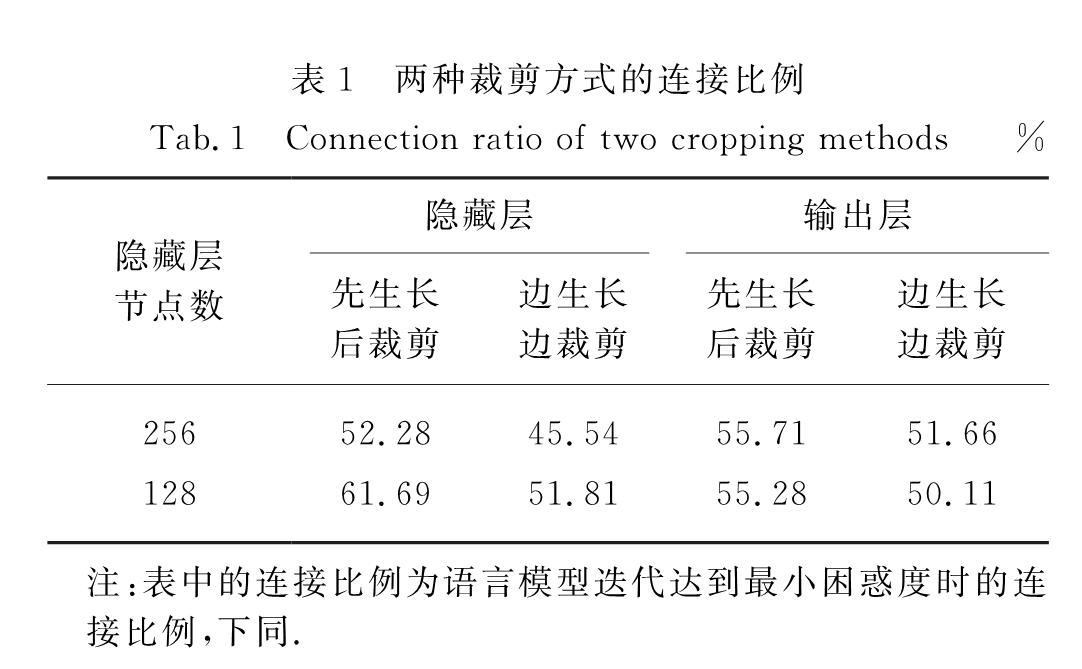
本研究将生长剪枝的结构学习模式应用到自然语言处理任务中来,针对语言建模任务对该方法的有效性以及实现策略进行探索.并在前馈神经语言模型任务中分析了不同的生长剪枝策略对网络结构压缩效果的影响.