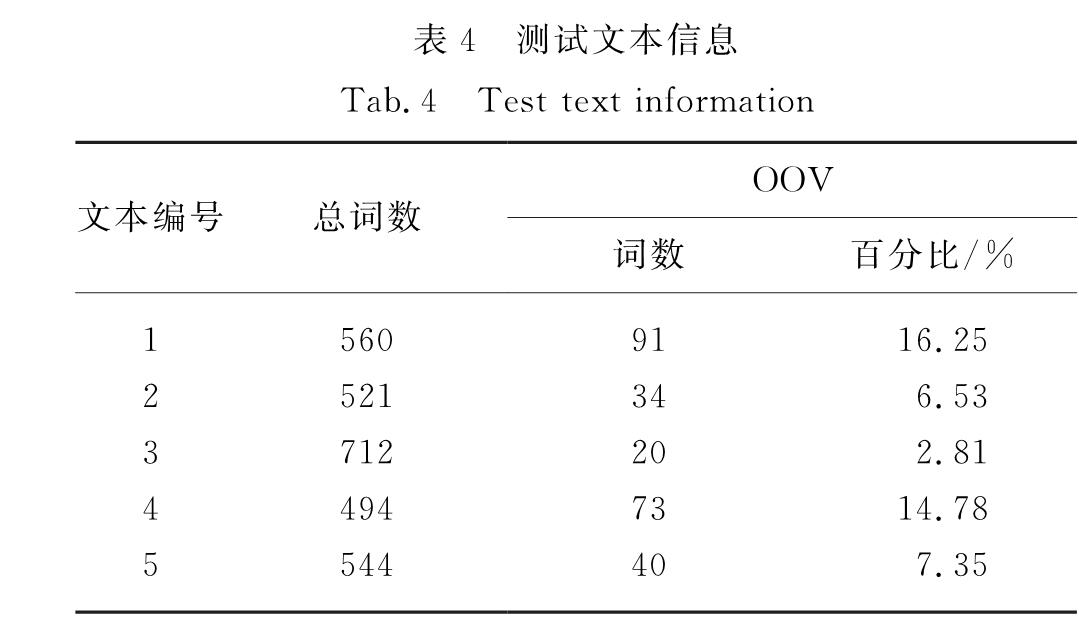
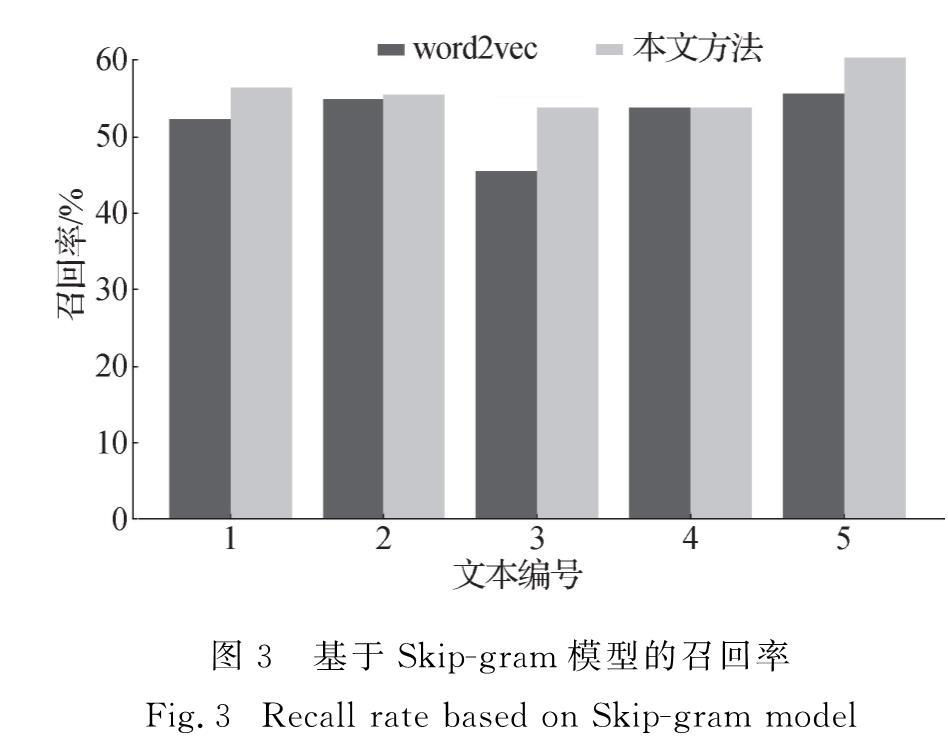
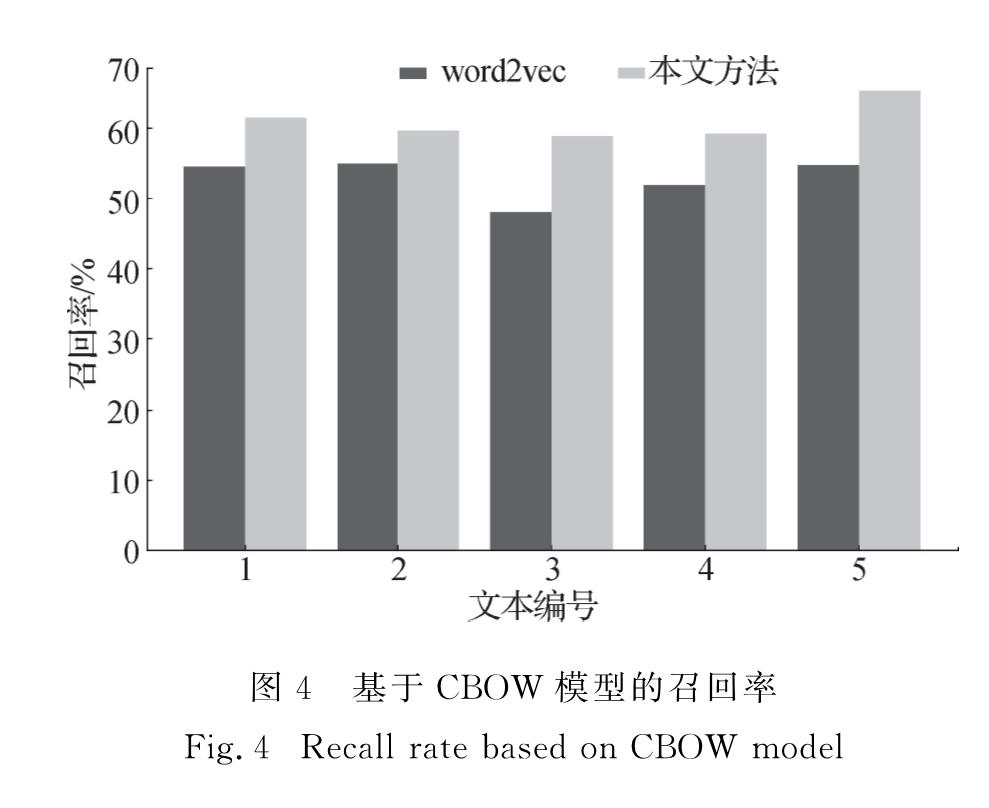
本研究主要针对拉丁维语中的不规则转换来进行文本规范化处理.基于维吾尔语本身的特点,文本规范化模型主要分为以下两个步骤:首先对于含有不规则转换的语料生成词嵌入表示,在这一部分提出了基于子词信息的词表示方法,该方法通过计算子词单位信息来构建词法模型,使用字符级的n-元语法(n-gram)之和表示词,将词信息映射到向量空间模型; 然后对于含有不规则转换的词,通过词之间的余弦相似度选择与之最相近的词作为候选词.
2.1 基于子词信息的分布表示
词是承载语义的最基本单元,而最初的词独热(one-hot)表示仅仅将单词符号化,不包含任何语义信息.Harris[19]提出“上下文相似的词,其语义也相似”的分布假说,为将语义融入词表示中提供了理论基础.
Mikolov等[20]提出的word2vec工具能够基于海量文本库和无监督策略实现高效的词向量学习.如图1所示,连续词袋(CBOW)和跳字(Skip-gram)模型是word2vec工具中用于描述词间共现关系的统计模型,其中V表示词表(词的集合),wi表示文本序列中第i个词,m表示上下文词的范围.设计2个模型主要是希望用更高效的方法获取词向量.
图1 CBOW(a)和Skip-gram(b)模型结构图[20]
Fig.1 Structure diagrams[20] of CBOW(a)and Skip-gram(b)models
在word2vec工具中针对每个词会生成不同的向量表示,然而这种表示会忽视词的内部形态结构,因此本研究在这些模型的基础上将词的n-gram考虑进去.以拉丁化的维吾尔语单词médiyeliri(赞赏)为例,在实验中选择n的范围为3~6,将每个词切分成大小长度为n的子字符串,则它的n-gram有如下几种形式:
n=3 “<mé”, “méd”, “édi”, “diy”, “iye”, “yel”, “eli”, “lir”, “iri”, “ri>”;
n=4 “<méd”, “médi”, “édiy”, “diye”, “iyel”, “yeli”, “elir”, “liri”, “iri>”;
n=5 “<médi”, “médiy”, “édiye”, “diyel”, “iyeli”, “yelir”, “eliri”, “liri>”;
n=6 “<médiy”, “médiye”, “édiyel”, “diyeli”, “iyelir”, “yeliri”, “eliri>”.
同时还要将词本身考虑在内,即
<médiyeliri>,
其中,<表示前缀,>表示后缀.可以用这些范围内的n-gram向量叠加来表示médiyeliri这个词.
对于给定的语料库,设基于词表所获得的词w的字符级n-gram的规模大小为G,则给定一个词w,可以通过gw{g1,g2,…,gG}将词w表示为n-gram的字母组合,将每个n-gram的字符g生成一个向量表示zg; 其上下文c的向量表示为vc,可以通过对词 n-gram的向量与上下文向量的乘积进行求和来表示一个词.因此得到一个得分函数:
s(w,c)=∑g∈gwzTgvc.(1)
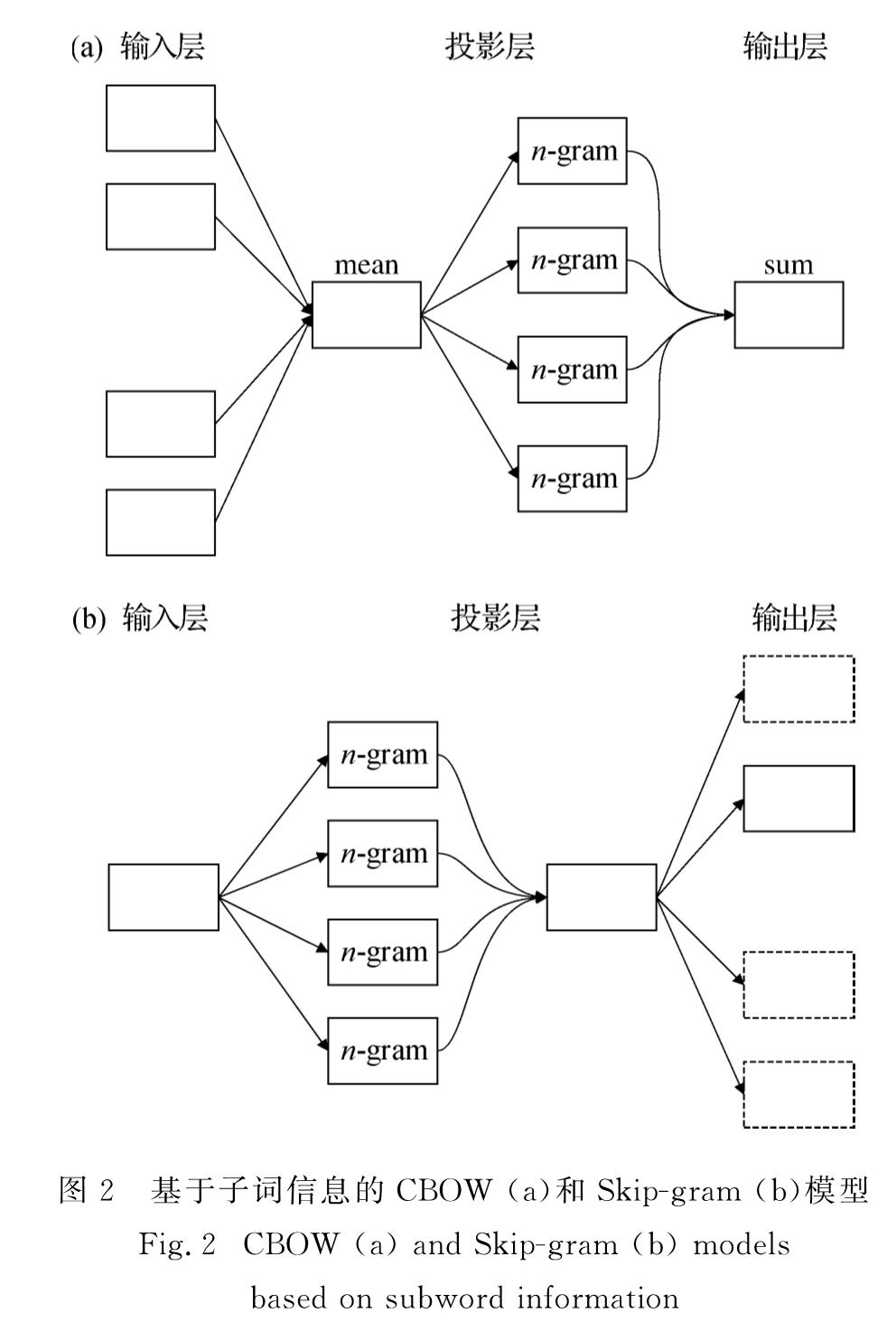
将得分函数应用于CBOW和Skip-gram模型词向量的生成(图2).为了限定模型的内存要求,使用散列函数将字符级的n-gram映射到1~K的整数中,采用Fowler-Noll-Vo散列函数来映射字符序列,并将K设置为2×106.每个词根据它在单词字典中的索引及其包含的哈希值的集合来获得相应的表示.
图2 基于子词信息的CBOW(a)和Skip-gram(b)模型
Fig.2 CBOW(a)and Skip-gram(b)models based on subword information
CBOW模型如图2(a)所示,使用一段文本的中间词作为目标词,在神经网络语言模型的基础上做了两方面的简化:1)不包含隐藏层,该模型从神经网络结构直接转化为对数线性结构,与logistic回归一致,对数线性结构比三层神经网络结构少了一个矩阵运算,大幅度地提升了模型的训练速度; 2)去除了上下文各词的词序信息,使用上下文各词词向量的平均值代替神经网络语言模型使用的上下文各词词向量的拼接[21].对于一段训练文本wi-(m-1)/2,…,wi,…,wi+(m-1)/2,则输入层为
x=1/(m-1)∑wj∈ce(wj),(2)
其中x为上下文词向量的表示,即为前文中的vc.
设目标词w和上下文c分别为
w=wi,(3)
c={wi-(m-1)/2,…,wi-1,wi+1,…,wi+(m-1)/2},(4)
CBOW模型的输入层为上下文的表示,则可根据上下文的表示直接对目标词进行预测:
P(w|c)=(exp(s(w,x)))/(∑w'∈Vexp(s(w',x))),(5)
其中w'为词表中的词.
对于整个语料而言,该模型的优化目标为最大化
∑(w,c∈D)log P(w|c),(6)
其中D表示训练词向量的语料.
Skip-gram模型如图2(b)所示,与CBOW模型一致,该模型中也没有包含隐藏层; 而与CBOW模型不同的是,该模型每次从w的c中选择一个词,将其词向量作为模型的输入x,即上下文的表示.由于模型需要遍历整个语料,任意一个窗口中的两个词wa和wb都需要计算P(wa|wb)+P(wb|wa),因此Skip-gram模型同样是通过上下文预测目标词[22],对于整个语料的优化目标为最大化
∑(w,c)∈D ∑wj∈clog P(w|wj),(7)
其中,
P(w|wj)=(exp(s(w,wj)))/(∑w'∈Vexp(s(w',wj))).(8)
在词向量的表示中,融入子词信息可以学习到词内部的形态知识,当两个词有相同的词缀时,其语义也具有一定的相似性.例如英语单词disagree和discover,从词层面上看是两个不同的词,但是如果用字符级的n-gram来表示,则有相同的前缀dis来表示否定的含义.对于维吾尔语这种形态丰富的语言来说,这种方式可以更好地表现出词的含义.


![图1 CBOW(a)和Skip-gram(b)模型结构图[20]<br/>Fig.1 Structure diagrams[20] of CBOW(a)and Skip-gram(b)models](2019年02期/pic81.jpg)