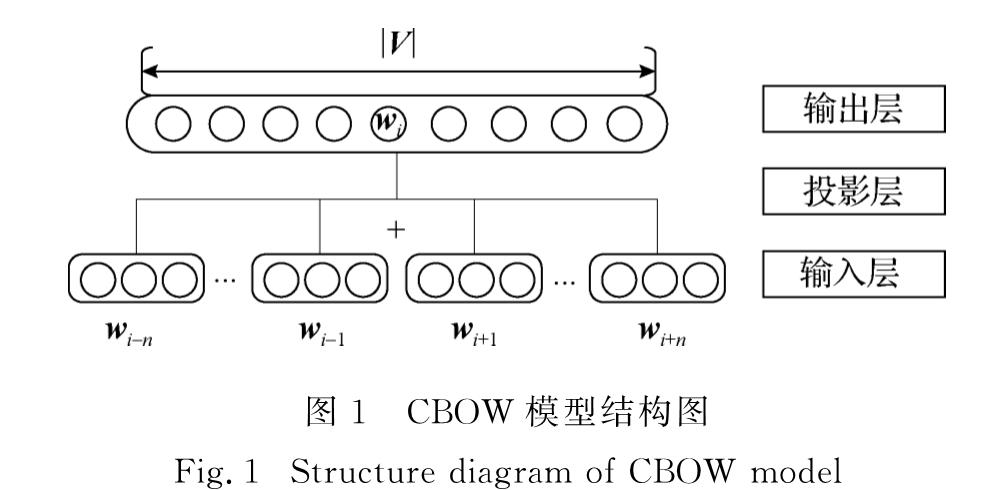
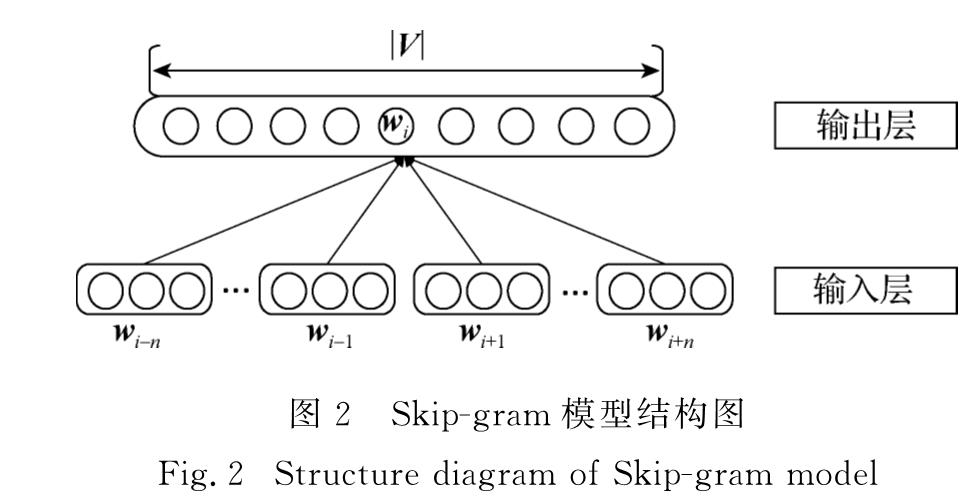
早期对于单词的处理采用独热表示(one-hot representation),即将单词作为一个独立的符号表示,这种单词表示没有任何语义关联.Harris[1]在1954年提出了关于上下文的分布假说(distributional hypothesis),认为“上下文相似的词,其语义也相似”.基于分布假说,研究人员提出了一系列训练单词表示的模型,后续的词向量一般以一组低维(通常50~1 000维)、稠密的实数向量来表示单词.1992 年Brown等[2]提出了基于聚类的词向量表示模型,1998年Landauer等[3]提出了基于矩阵的词向量表示模型.同时期,基于人工标注的单词表示如WordNet[4]和知网Hownet[5-6]均能在一定程度上较好地表示单词语义,但其规模小,成本高.2003年,Bengio等[7]用神经网络训练语言模型,2010年Mikolov等[8]进一步提出用循环神经网络训练语言模型,词向量作为副产品可从完成训练的语言模型的权值矩阵中抽取得到.2013年Mikolov等[9-10]提出了当前主流的词向量训练模型:连续词袋(continuous bag of words,CBOW)和跳字(Skip-gram)模型,利用窗口化的上下文对词向量进行训练.2014年Pennington等[11]提出了基于词共现矩阵的Glove模型,利用全局信息训练词向量.还有一些学者在词向量模型上融合了更细粒度的特征(字符、单字)对其进行改进:Huang等[12]提出一词多义的训练方法,Chen等[13]在中文上提出加入字向量的字词联合训练方法.2016年来斯惟等[14-15]通过详细的对比实验比较了各模型在中文上的性能和质量,并提出训练意见以及order模型.同时期,户保田[16]提出了结合动名词性训练词向量的方法.
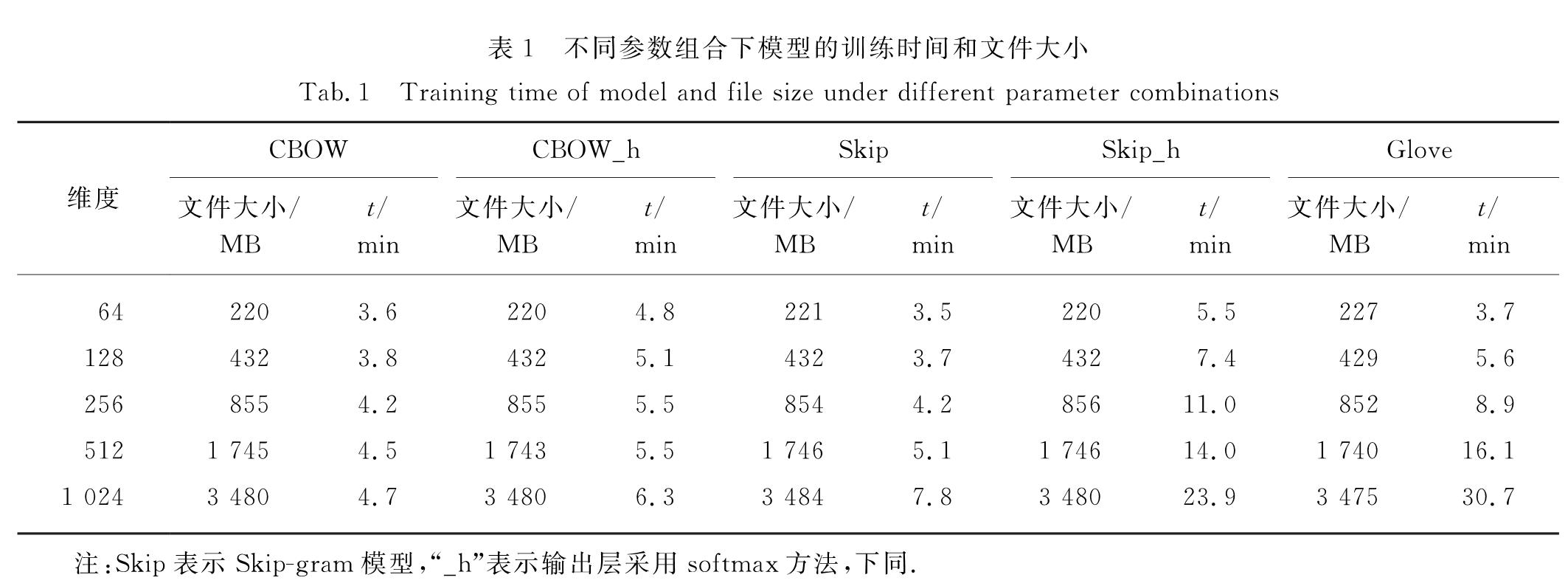
维吾尔语属于黏着性语种,词形变化丰富,通过词本身形式的变化表示语法关系,可利用不同词干和词缀的组合构成具有丰富语义与句法信息的词汇[17].但是鉴于维吾尔语的黏着性,目前探究维吾尔语词向量表示对其进行语言处理的研究报道很少.在维吾尔语的自然语言处理过程中,词向量表示对后续很多自然语言处理任务(如词性标注[18]和命名实体识别[19]等)具有较大影响.在这些工作中,主要通过更换参数组合(模型、维度、输出层方法等)训练得到词向量,将其作为初始输入应用于具体任务进行对比实验,以确定实验中效果较好的参数组合,但存在以下3个问题:1)如果具体任务模型较为复杂,更换参数组合带来的大量重复实验成本较大; 2)维吾尔语词向量的研究缺乏公开的词向量评测数据集,无法使用统一的评测数据有效地评价维吾尔语词向量质量; 3)受限于语料规模,汉英常用的两种评测方法在维吾尔语词向量上的评测结果缺乏区分度,无法有效鉴别不同参数组合下的维吾尔语词向量质量.
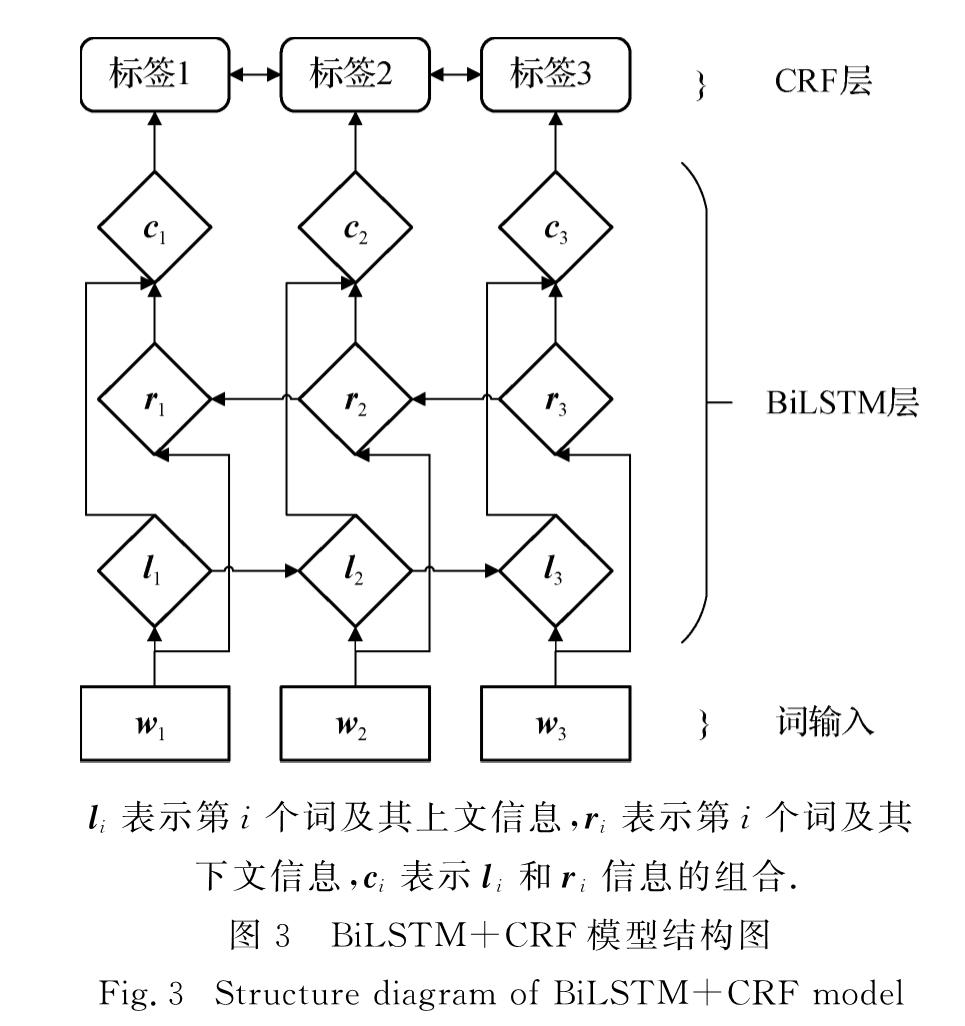
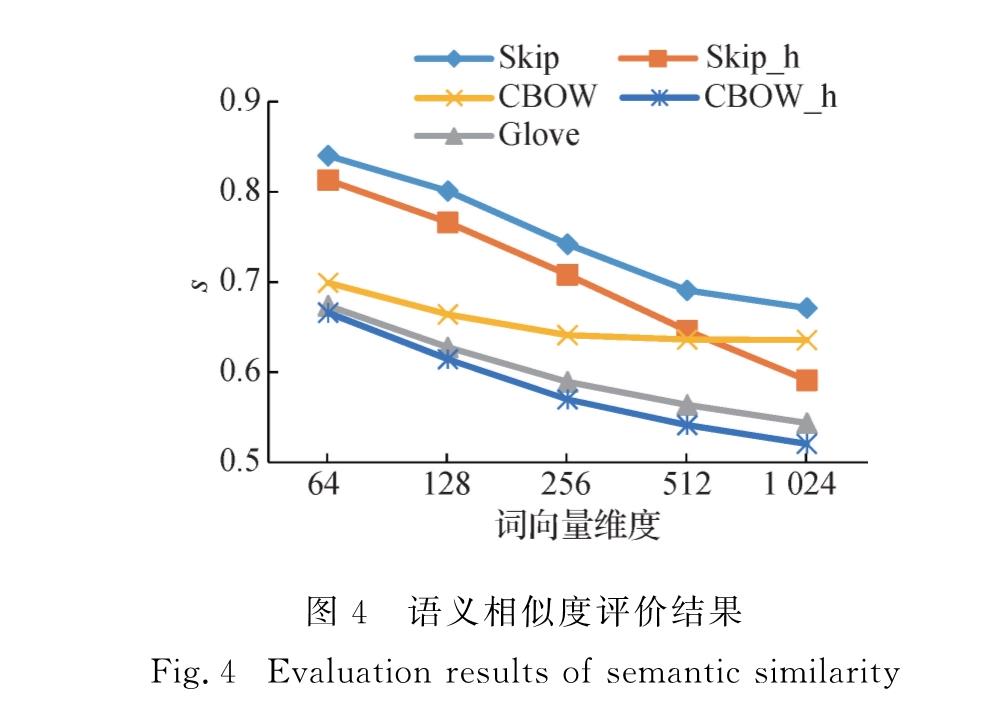
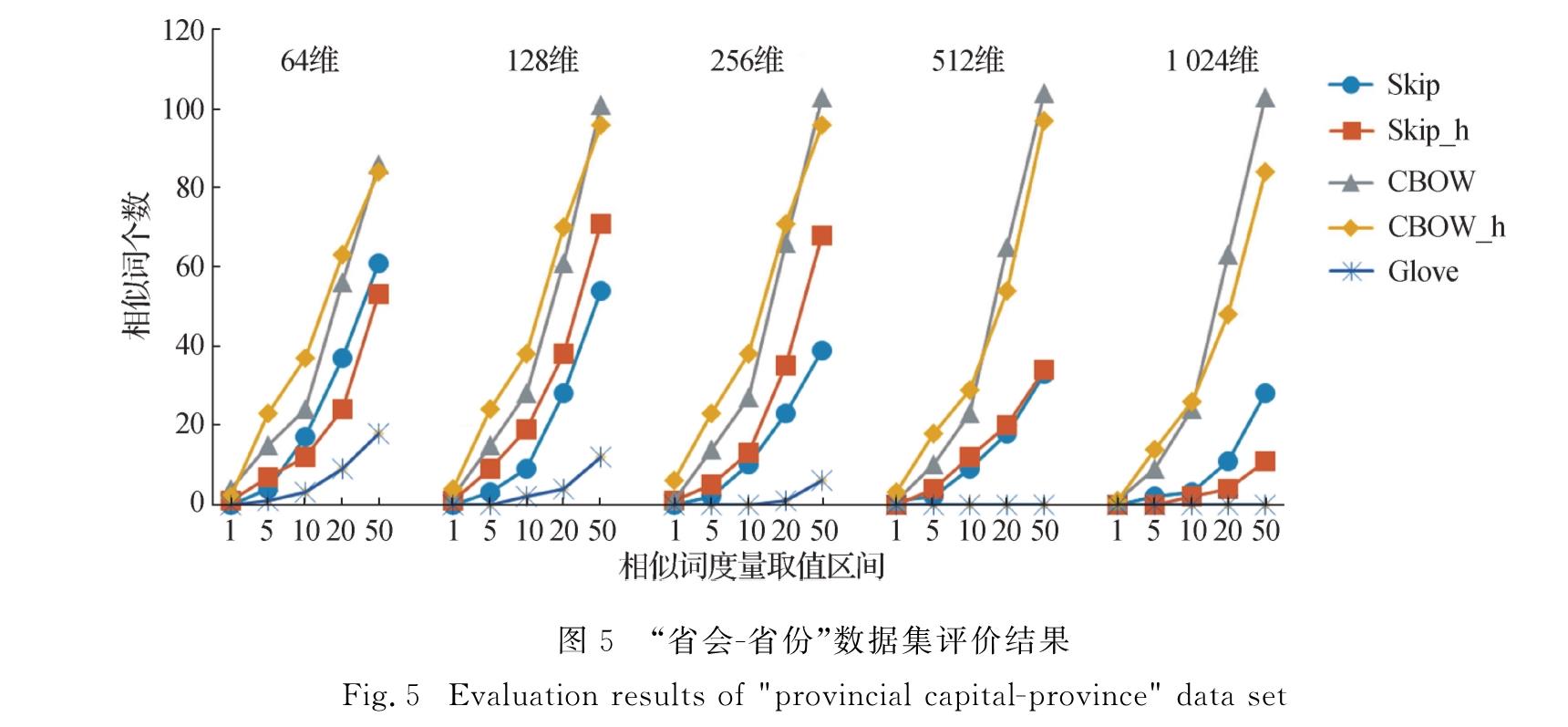
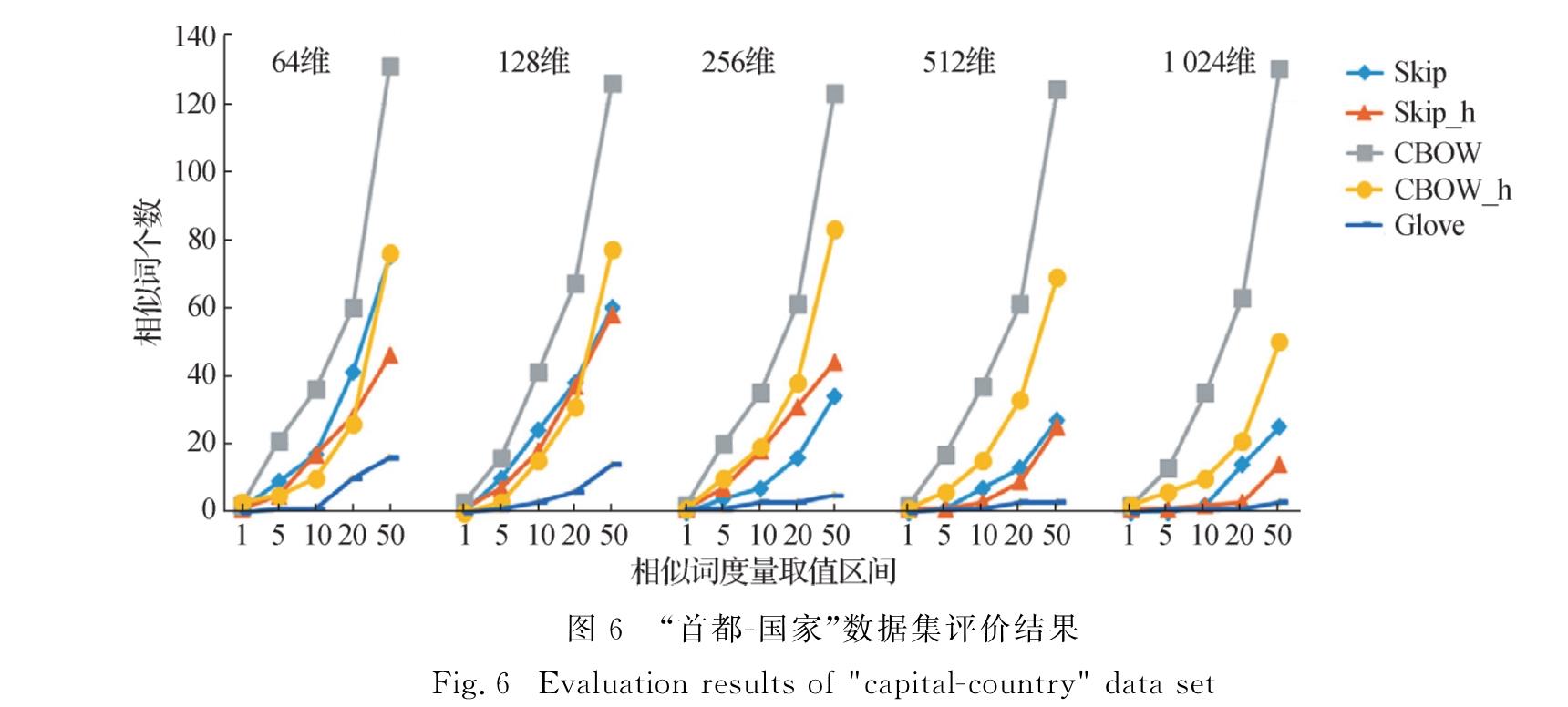
为解决上述3个问题,本文中使用CBOW、Skip-gram和Glove模型对维吾尔语词向量表示进行研究,分析这3种模型各自的原理,进而采用多种参数组合训练得到词向量,并进行评测实验.首先,通过人工翻译构建维吾尔语版本的词向量评测数据集wordsim240[20]和word analogy[13],缓解了评测数据缺失的问题.在汉语与维吾尔语翻译过程中,出现了单词一对多的情况,对这些单词数据进行过滤,最终所得维吾尔语版的数据集比汉语的数据集规模要小.然后,针对汉英评测方法在维吾尔语词向量质量评测上存在区分度不高、评测方法失效等问题,本文中提出了新的单词语义相似度评测方法,并改进语义类比推理的评测方法.同时,采用双向长短时记忆神经网络(BiLSTM)和条件随机场(CRF)结合模型BiLSTM+CRF的命名实体识别任务[21]作为实际任务,对词向量在具体任务上的表现进行分析,验证本文评测方法的有效性.最后,综合各项评测任务和命名实体任务的实验结果,提供了当前语料规模下较为理想的参数组合建议.本文将公开维吾尔语版本的词义相似度数据集、语义类比推理数据集,为后续维吾尔语词向量的模型改进、对比研究以及实际应用提供参考.