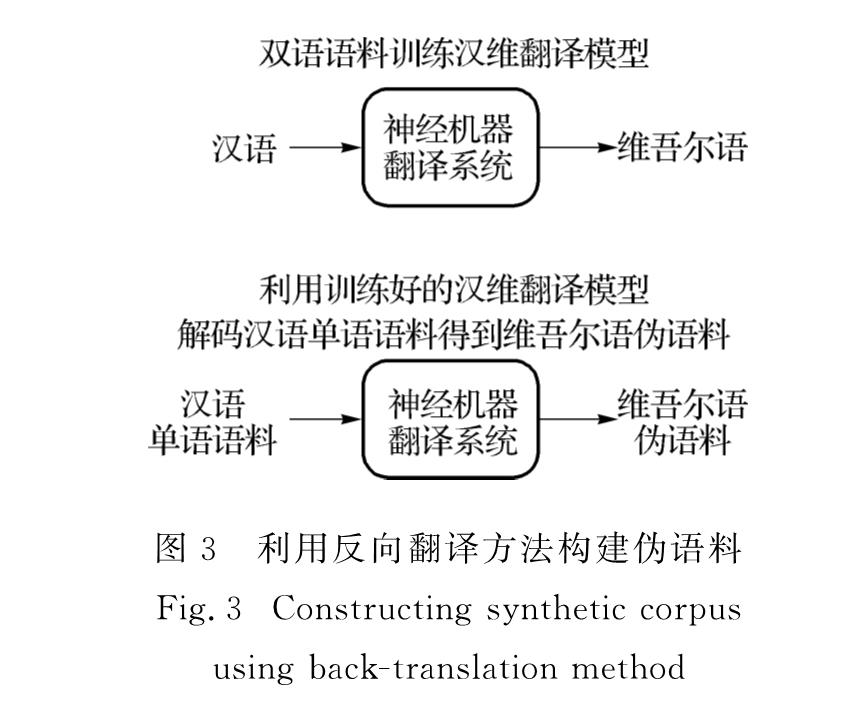
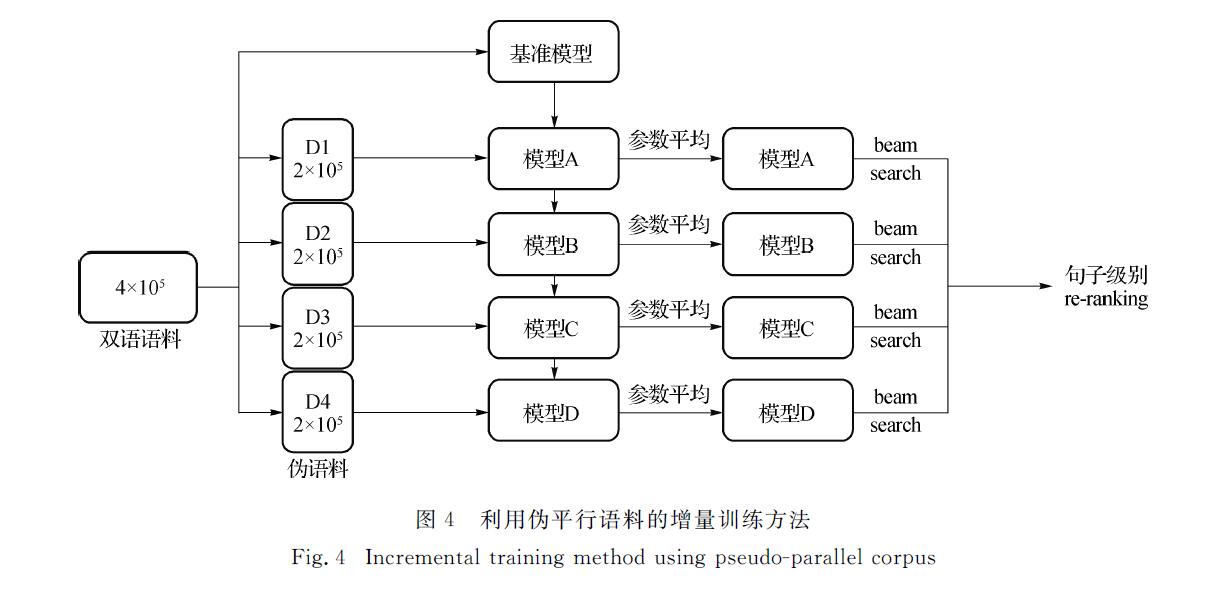
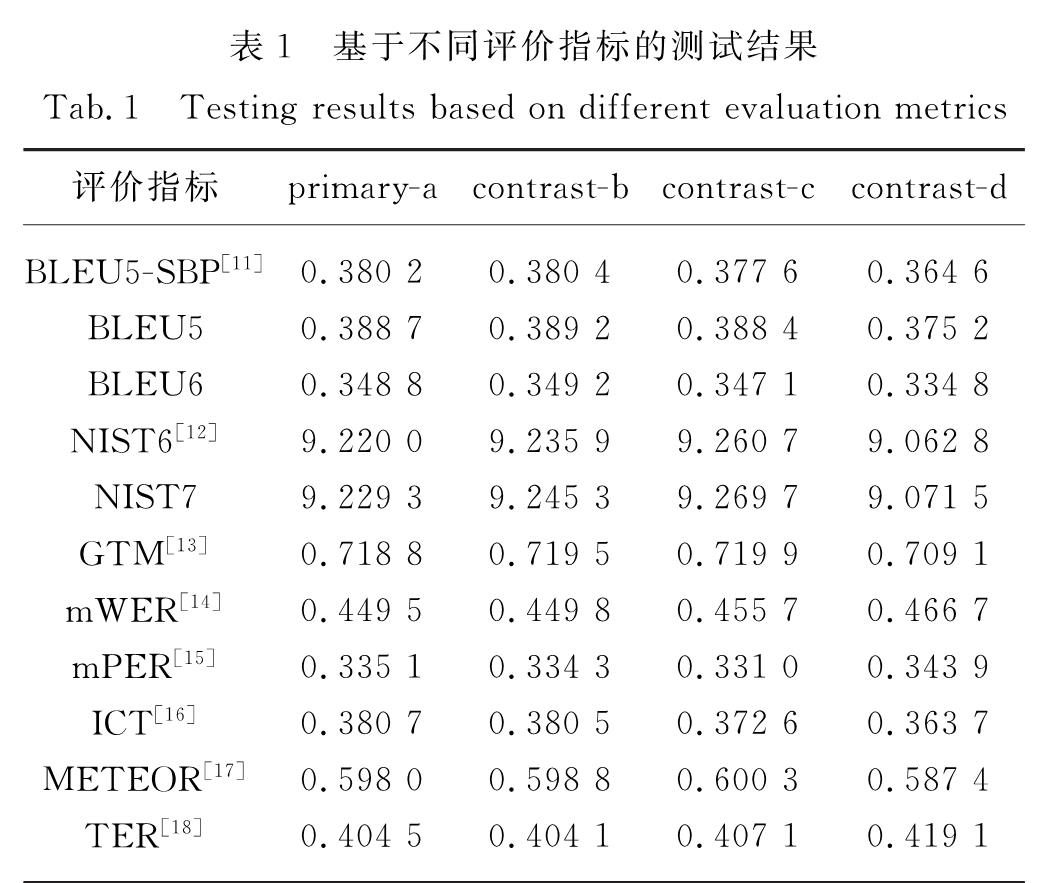
目前,基于深度学习的神经机器翻译已经成为机器翻译领域的主流方法.神经机器翻译模型相较于统计机器翻译模型具有更庞大的参数规模,因此其翻译质量取决于训练数据是否充足.由于与维吾尔语相关的平行语料资源严重匮乏,神经机器翻译模型在维汉翻译任务上表现不佳,为此提出了一种利用伪语料对神经机器翻译模型进行增量训练的方法,可有效提升神经机器翻译在维汉翻译任务上的质量.
At present,the neural machine translation based on deep learning has become the mainstream method in the field of machine translation.The neural machine translation model requires a larger parameter size than the statistical machine translation model does. Therefore, its translation quality depends on the sufficiency of the training data.Due to the serious lack of parallel corpus resources related to Uyghur,the neural machine translation model performs poorly on Uyghur-to-Chinese translation tasks.This paper proposes a method of incremental training of neural machine translation models using pseudo-corpus,which effectively improves the quality of neural machine translation in Uyghur-to-Chinese translation tasks.
![图1 Transformer模型架构(修改自文献[4])<br/>Fig.1 Architecture of the Transformer model(modified from reference[4])](2019年02期/pic53.jpg)
![图2 多头自注意力模块(修改自文献[4])<br/>Fig.2 Multi-head self-attention module(modified from reference[4])](2019年02期/pic54.jpg)