DOI: 10.1007/978-981-10-3635-4_2.
备注
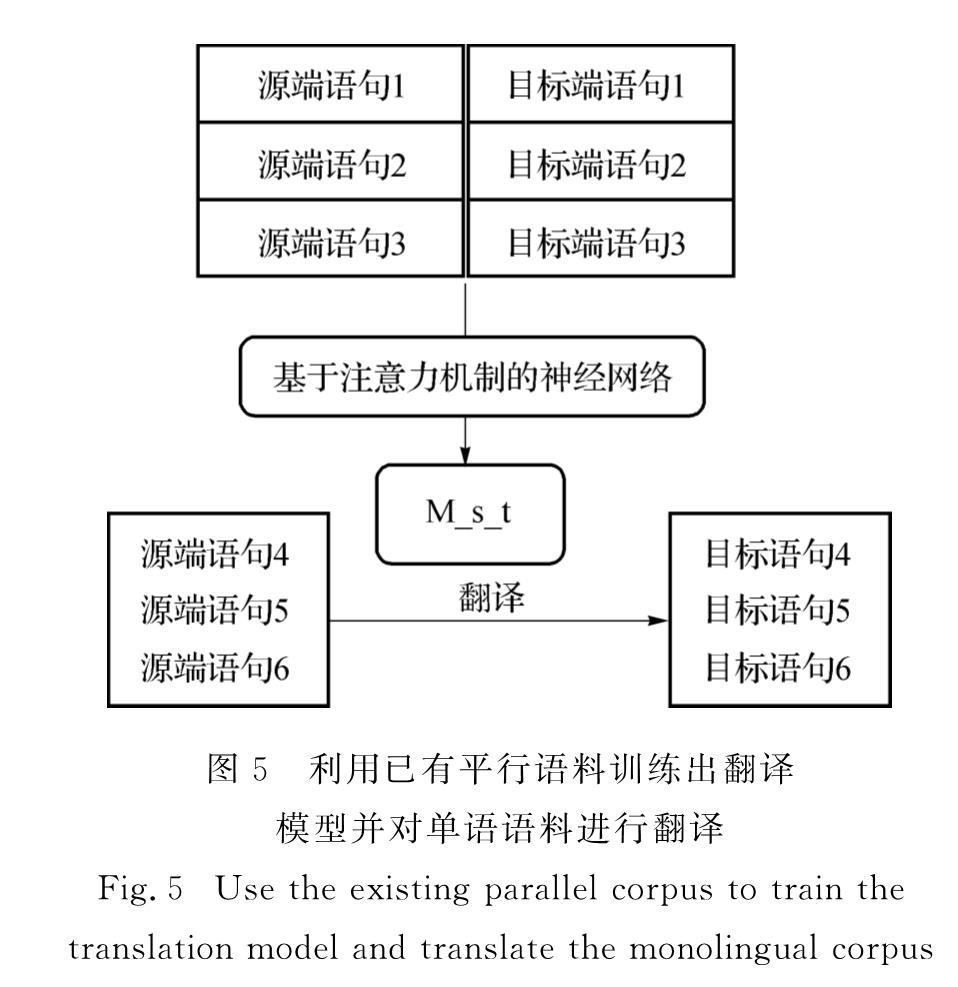
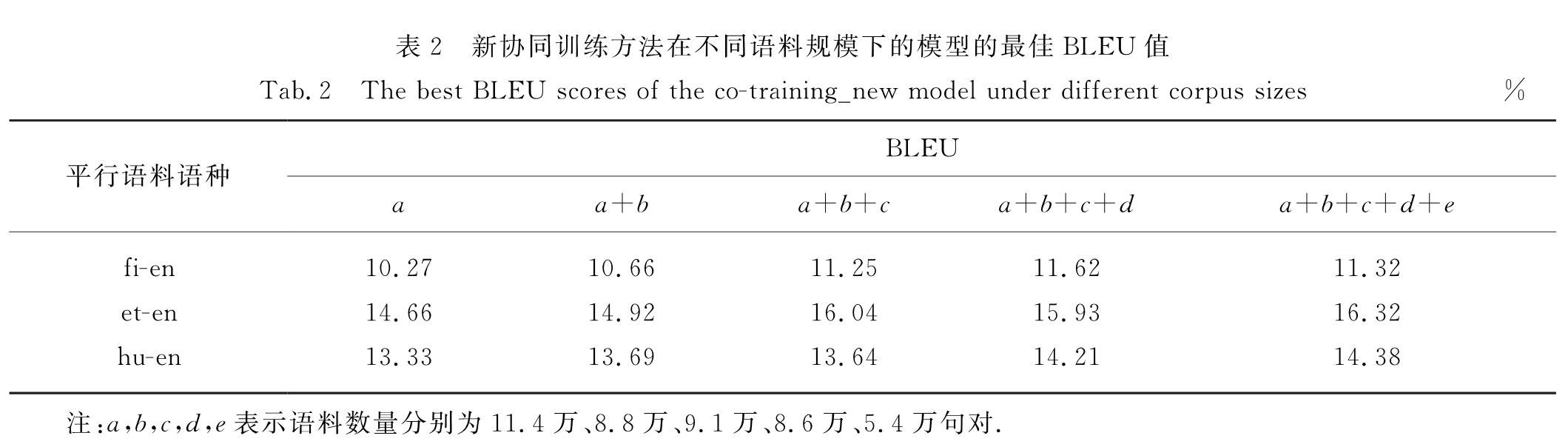
如何改善神经机器翻译模型的翻译性能一直是学术界研究的热门课题,特别是在低资源语种的翻译任务上,如何提高原有平行语料训练出来的翻译模型的翻译质量是一个迫切需要解决的问题.为此,对传统的统计机器翻译任务上使用的协同训练方法进行优化,进一步提出新的协同训练方法,并应用于神经机器翻译任务中,改善原有神经机器翻译模型的翻译质量.实验表明神经机器翻译中使用协同训练的方法能显著提高翻译质量,在语料数量稀少(低资源语料)的情况下提升效果更为显著.
Improving the performance of neural machine translation system is a hot research topic in the academia,especially for the low-resource language translation tasks.Co-training is a method which uses large amounts of unlabeled data in addition to a small labeled data set.It is used to label unlabeled data with high quality.Such additional labeled data is further used to enlarge the original labeled data set and finally retrain the translation model to obtain a better translation model.In this paper we propose to use the co-training method in neural machine translation.In order to make this method more applicable,we introduce a new co-training method to improve its practicality.Experimental results show that the proposed co-training in neural machine translation can significantly improve the translation performance,especially for low-resource language translation tasks.