本研究进行了以下5组实验:1)RNNSearch与Transformer翻译模型; 2)使用斯坦福分词(https:∥nlp.stanford.edu/software/segmenter.shtml)、Mecab(http:∥taku910.github.io/mecab/)、Moses预处理(http:∥statmt.org/moses/)、英语字节对编码(byte pair encoding,BPE,https:∥github.com/rsennrich/subword-nmt)[17]、句块(Sentencepiece,https:∥github.com/google/sentencepiece)等工具进行数据处理并进行对比; 3)增量式自学习的模型训练; 4)将基于中介语翻译、扩充伪训练数据与基于增量式自学习的方法进行对比; 5)单模型、模型平均(avgbest2)和模型集成(essemble4)的对比.
3.1 架构选择和超参设置
为了实现更好的翻译效果,在架构的选择上本研究对比了清华大学机器翻译演示系统(THUMT,https:∥github.com/thumt/THUMT)提供的RNNSearch和Transformer两个架构,在JAZH数据集上进行实验,采用相同的预处理方法,在日中开发集上检验模型的翻译性能,采用BLEU[18]作为评价指标,实验结果如表2所示,可见Transformer架构显著优于RNNSearch架构.本研究分析认为:深层模型和自注意力对于捕获长距离信息更为有效,而该翻译任务是专利领域,句子较长,所以Transformer的优势较为明显.因此,本研究选择Transformer模型进行后续的实验.
通过大量调参实验,本研究发现当Transformer的批处理(batch)设置为24 000(6 000词/显卡×4显卡)、训练步数设为20万步、其他超参数与Transformer默认设置一致时,训练过程能够较稳定地收敛,模型性能较优.所以在后续实验中均采用这一设置.
表2 神经网络机器翻译架构对比实验结果
Tab.2 Comparative experiments of neural network machine translation architectures
3.2 数据处理对比实验
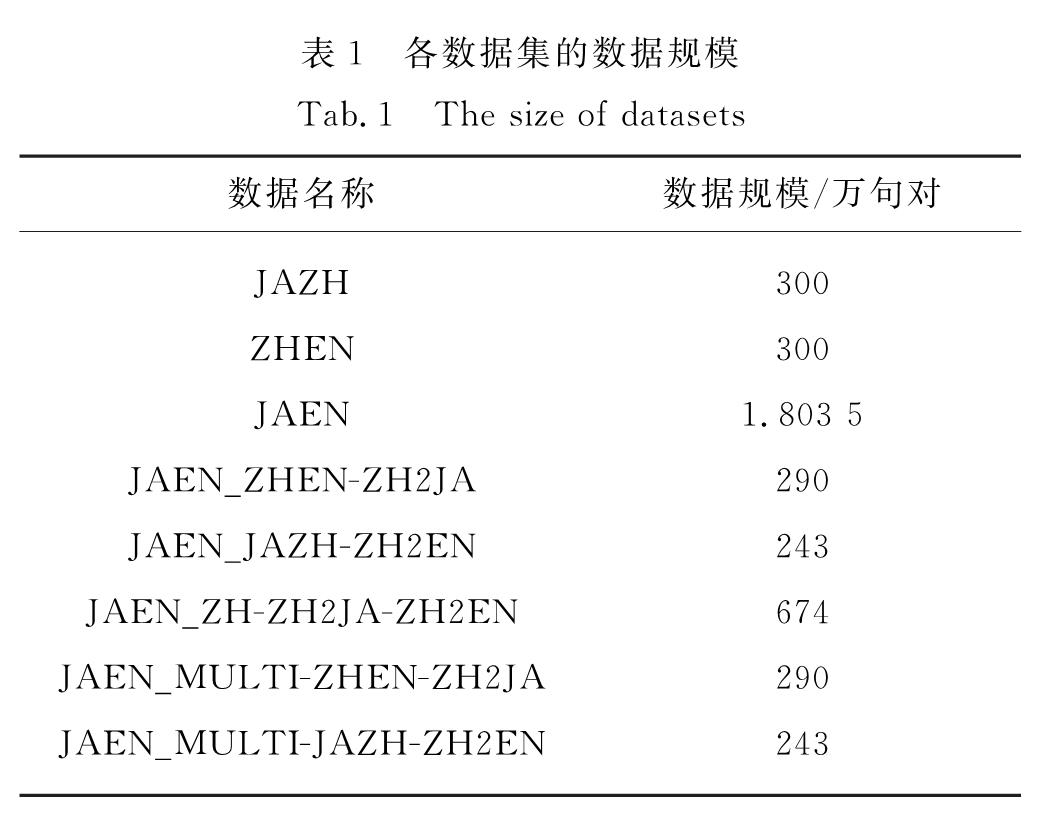
首先,不同语言的数据处理方法不同,则翻译效果不同.在某些特定情况下,英语和日语分别使用BPE分词和SentencePiece分词的效果会更好.其次,对于共享字母表的语言,在两个或更多相关语言的串联上学习BPE可以提高分词的一致性,并减少在复制或音译专有名词时插入或删除字符的问题.因此,两端分开处理和联合BPE处理数据两种方式对于模型训练效果也会有一定的影响.除此之外,词表大小也会影响模型的训练效果.
在数据处理方式的选择上,本研究在Transformer模型架构下,对JAEN_ZHEN-ZH2JA和JAZH两个合并数据集上进行实验,采用相同的超参数设置,对比了日语SentencePiece/英语BPE的两端分开处理与采用不同词表大小联合BPE处理,对翻译结果的影响.实验结果如表3所示,可见在日英翻译任务上,词表大小为2万个时,联合BPE的效果最好.
表3 亚词处理方式对比实验结果
Tab.3 Comparative experiments of subword segmentation methods
3.3 增量式自学习训练实验
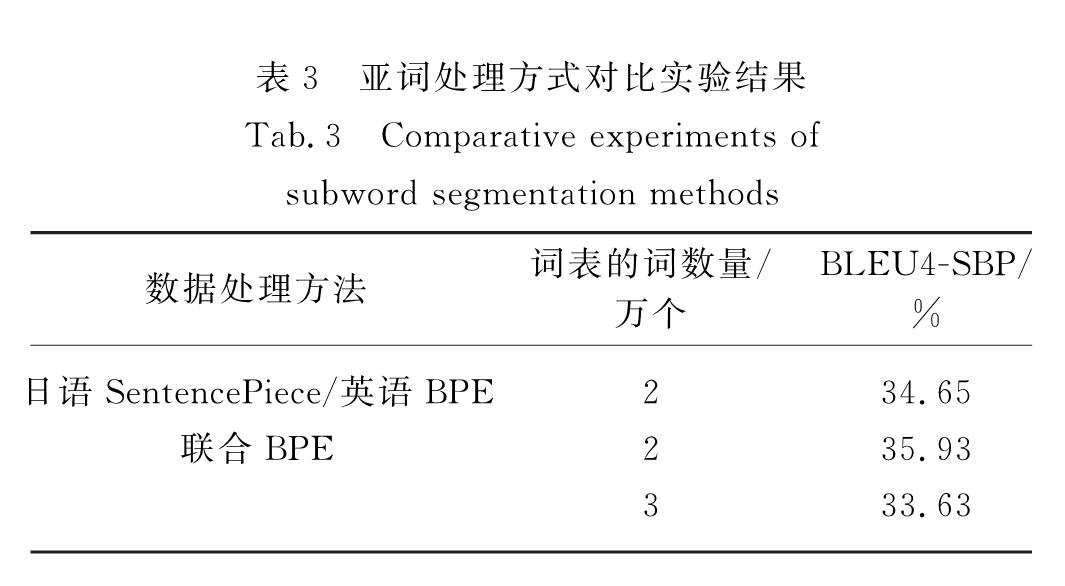
在增量式自学习过程中,本研究采用的策略:首先,使用原始数据即评测提供的数据进行模型的训练,将该模型作为基线系统; 然后,在该基线系统的基础上尝试加入不同的数据进行训练; 最后,以BLEU值作为参考,观察在开发集上日英翻译的性能.如表4,仅列举了增量式自学习方法部分迭代轮次的大致情况,展示了数据规模逐渐加大,以及在同一轮次加入不一样的数据,导致模型训练的结果不一样.可以看出第一轮在基线的基础上加入JAEN_ZHEN-ZH2JA,其翻译效果提升明显.第二轮在加入JAEN_MULTI-ZHEN-ZH2JA后,对翻译也有帮助,但是第三轮实验1和2分别加入数据集JAEN_JAZH-ZH2EN和数据集JAEN_MULTI-JAZH-ZH2EN后,BLEU值逐渐下降,说明在某种程度上这2个数据不能为翻译提供有用的信息.第四轮时在C4数据集上接着加入数据集JAEN_MULTI-ZHEN-ZH2JA-ZH2EN,此时BLEU值与第二轮相同,所以该数据集可以做更多实验进行观察.
由此可知,实验数据的规模以及数据的有用性对于翻译质量非常重要,鉴于时间的原因,后续将继续进行更深层次的增量式自学习实验,挖掘更多有效信息.
表4 增量式自学习部分迭代的BLEU值
Tab.4 BLEU scores in iterations of incremental self-learning
3.4 不同数据训练策略的翻译结果对比
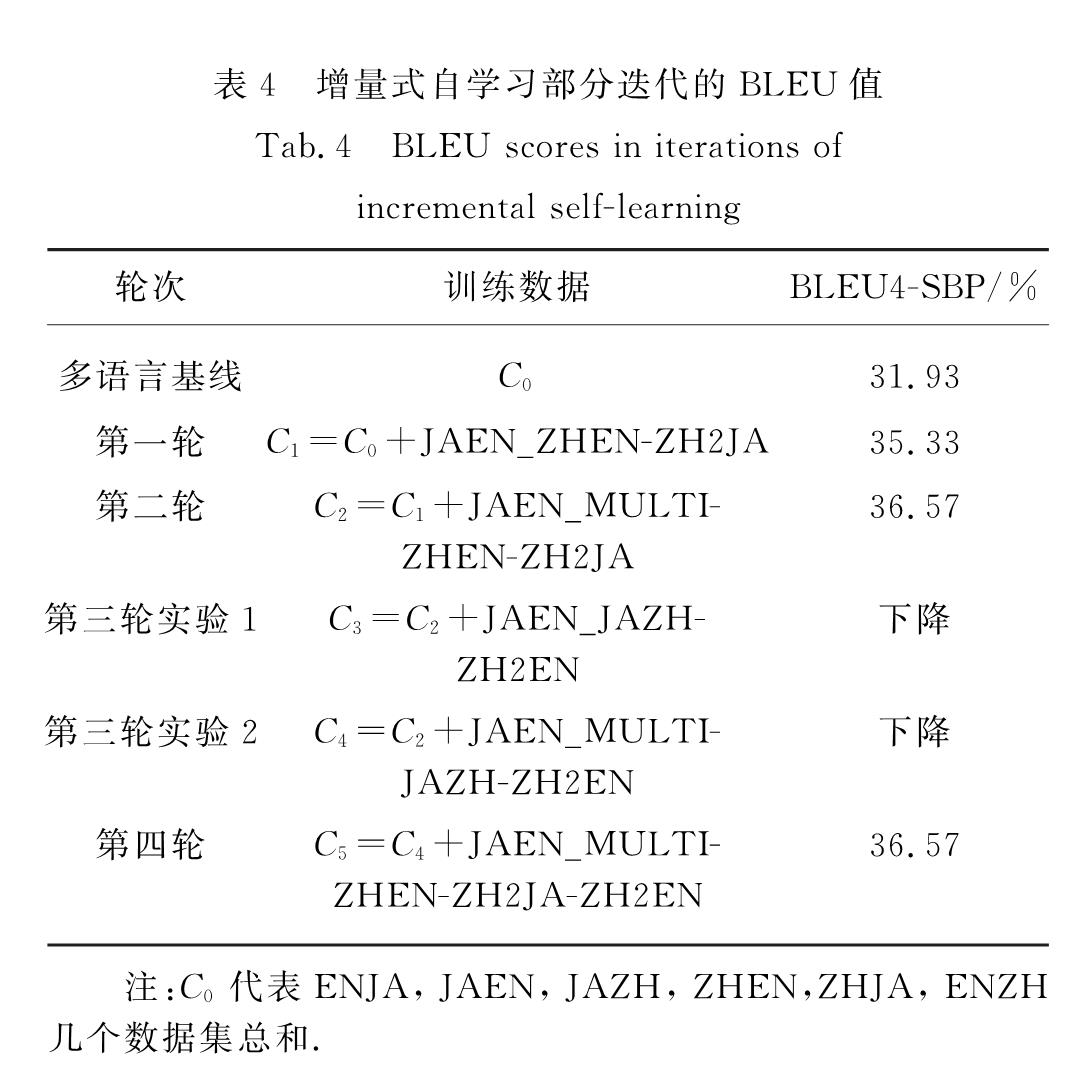
在相同数据预处理方法及相同超参数设置的情况下,本研究进一步对以下3种数据训练策略进行了对比:
1)pivot:训练日汉、汉英单语向翻译模型,采用中介语翻译方法利用二者进行组合解码;
2)direct:利用小规模日英真实语料和大规模日英伪语料直接训练日英NMT模型;
3)multilingual:采用增量式自学习方法训练多语翻译模型.
实验结果如表5所示,可见增量式自学习策略的性能显著优于中介语翻译和直接在伪平行语料上训练的普通双语翻译模型.对比表4与表5的数据可以发现,虽然多语言基线模型的性能比直接在伪平行语料上训练的双语模型低,但采用增量式自学习方法进行迭代训练,Transformer模型的翻译性能会不断提高.说明训练中加入的小规模真实日英平行语料对于翻译效果有提升作用,通过不断迭代生成的伪平行语料能够促进模型训练更快达到收敛,减少迭代的次数.在完成两轮迭代训练,增量式自学习方法比直接在伪平行语料上训练的普通双语模型在日英开发集上BLEU值高0.98个百分点.
表5 NMT训练策略对比实验结果
Tab.5 Comparative experiments of NMT training strategies
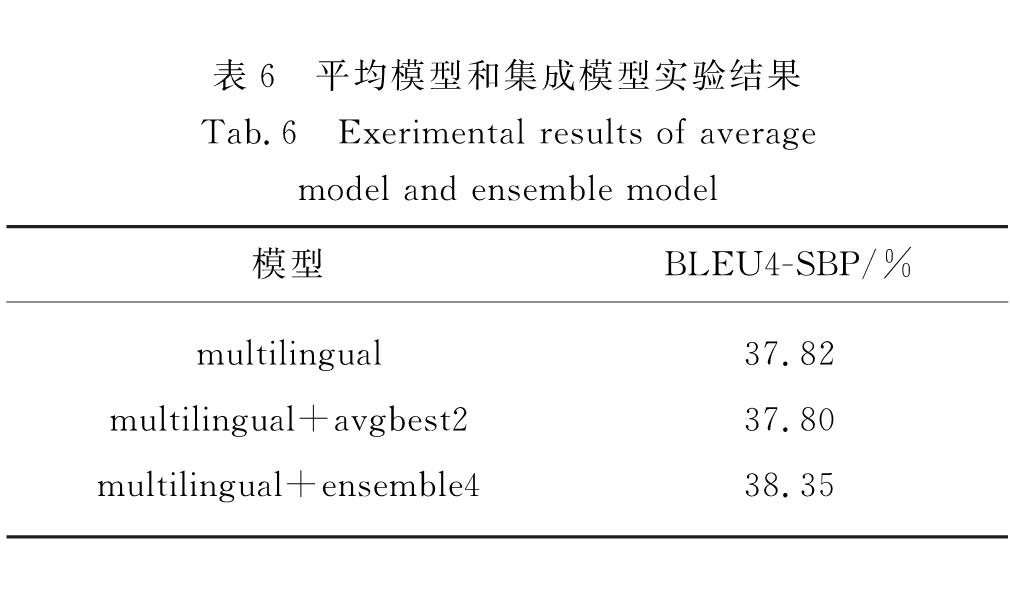
3.5 多模型的平均和集成策略对比
为了进一步提升翻译质量,本研究尝试了采用多模型平均和集成策略.
多模型平均为平均可训练参数,当模型接近收敛时,这些参数在单个模型的最后时间步长进行保存.由于使用随机梯度下降算法来优化模型,所以在每个步骤中仅使用一小批数据,导致参数可能过度适应一个小批量的数据,通过模型平均可以获得更强大的参数[19].在本实验中取同一个训练过程中验证集分数最高的前后k个模型进行平均,取k=2,3,4进行实验,最终发现k取2时效果最好,该模型记为avgbest2,但仍比单模型差(如表6所示).
多模型集成为在预测下一个目标单词之前整合多个模型的概率分布的方法,它已被证明在神经机器翻译中有效.本实验用不同的初始化方式在相同的架构上独立训练N个模型,将N个模型以不同的初始化方式组合为一个集合模型可以避免仅做局部优化,进而获得更好的结果[19].实验中取这N个模型中验证集分数最高的k个模型进行集成解码,取k=2,3,4进行实验,最终发现k取4时效果最好,该模型记为ensemble4,与单模型相比BLEU值提升0.53个百分点(如表6所示).
表6 平均模型和集成模型实验结果
Tab.6 Exerimental results of average model and ensemble model