机器翻译主要研究如何利用计算机将一种语言自动翻译为另一种语言.近年来,基于序列到序列的机器翻译方法[1]显著提高了机器翻译的质量,神经机器翻译(neural machine translation,NMT)[2-4]得到了广泛的关注和应用.同时,随着国内外文化的交流、经济贸易的增加,普适性的机器翻译系统的需求也愈来愈大.谷歌、百度、微软等公司也在不断发展和完善机器翻译系统,逐步将其从传统的统计机器翻译(statistic machine translation,SMT)系统[5]发展到NMT系统.
NMT模型使用的是编码器-解码器(encoder-decoder)框架,随着Bahdanau等[2]提出在NMT系统中融入注意力机制,使NMT的效果得到进一步提升,国内外的科研人员也以此为基础逐步完善了机器翻译的模型.
2017年,Wu等[6]针对目标端序列融合的依存信息,在训练过程中通过读取目标端语料的依存信息,生成由入栈(shift)、左归约(left-reduce)和右归约(right-reduce)组成的动作序列,在测试时根据模型生成的动作预测当前时刻目标端单词.同年,Wu等[7]继续对依存信息进行研究,通过对源端依存树的不同种遍历方式得到源端序列,并将该序列信息融入基准NMT系统中以获得更好的上下文向量表示,以此促进NMT性能的提高.同年,Hashimoto等[8]在源端建立多层编码器,通过计算源端单词之间依存关系的强弱,来捕捉源端长距单词之间的依存关系,以提高机器翻译的性能.
2017年,Chen等[9]在全局注意力的基础上,提出融入语法距离约束的局部注意力机制,使得当前目标端单词更关注于源端语法相关的的源端单词.
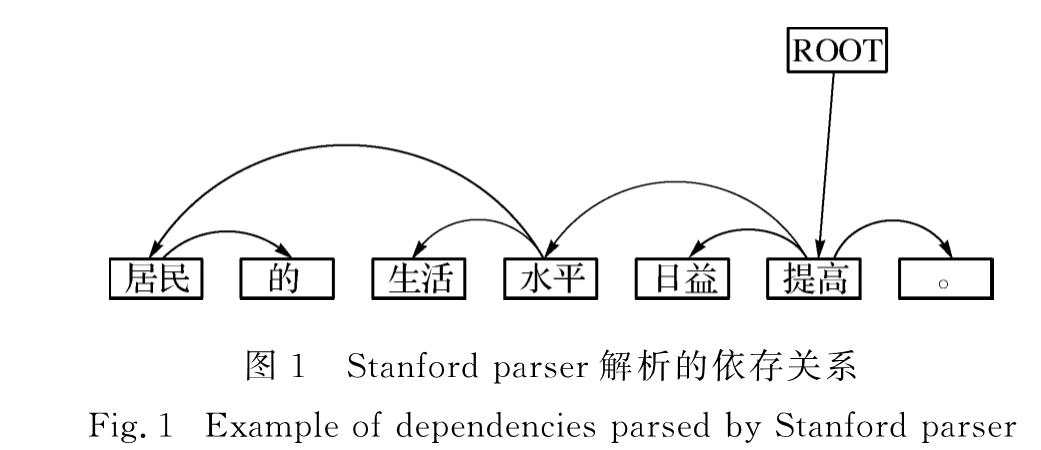
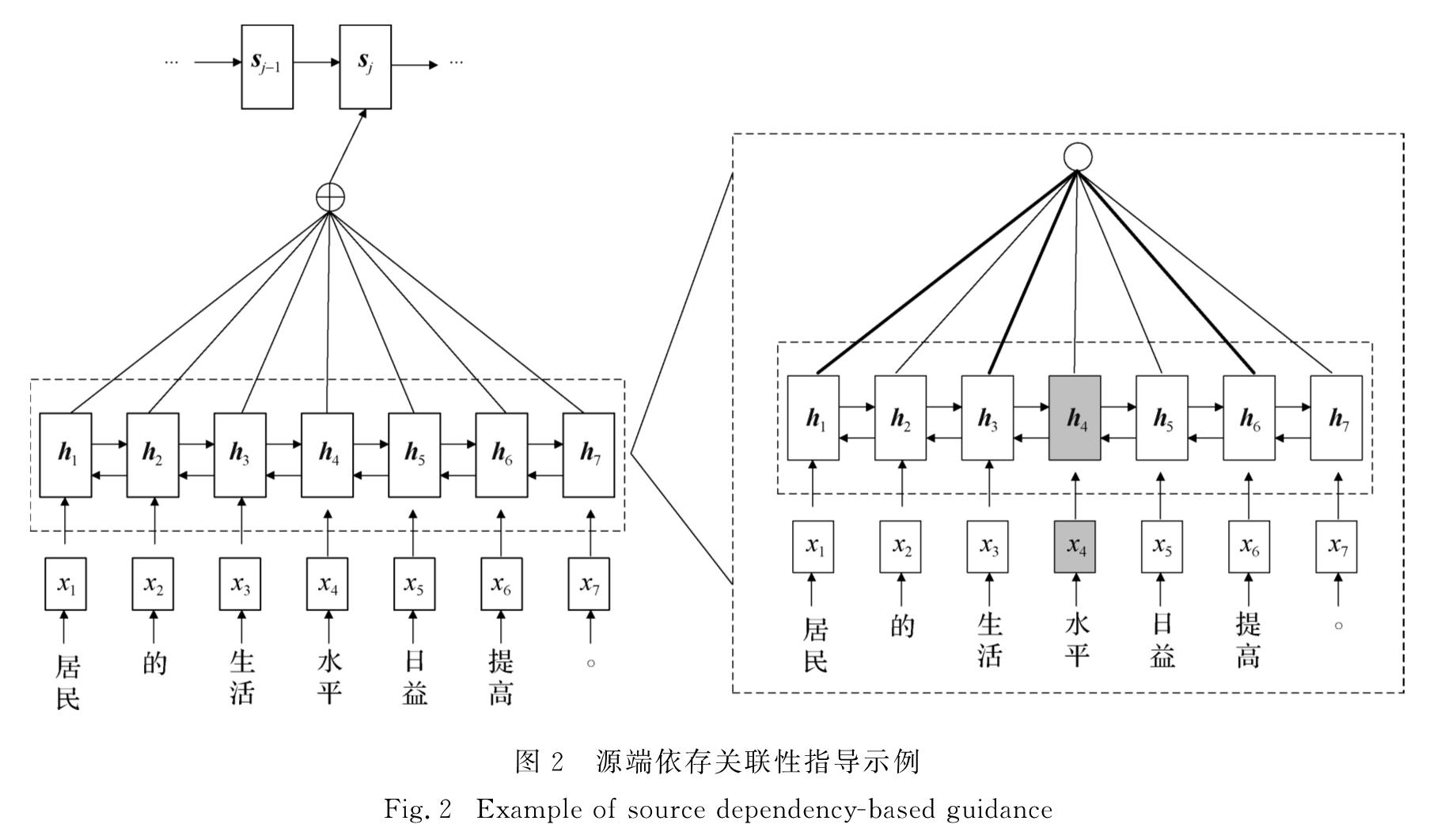
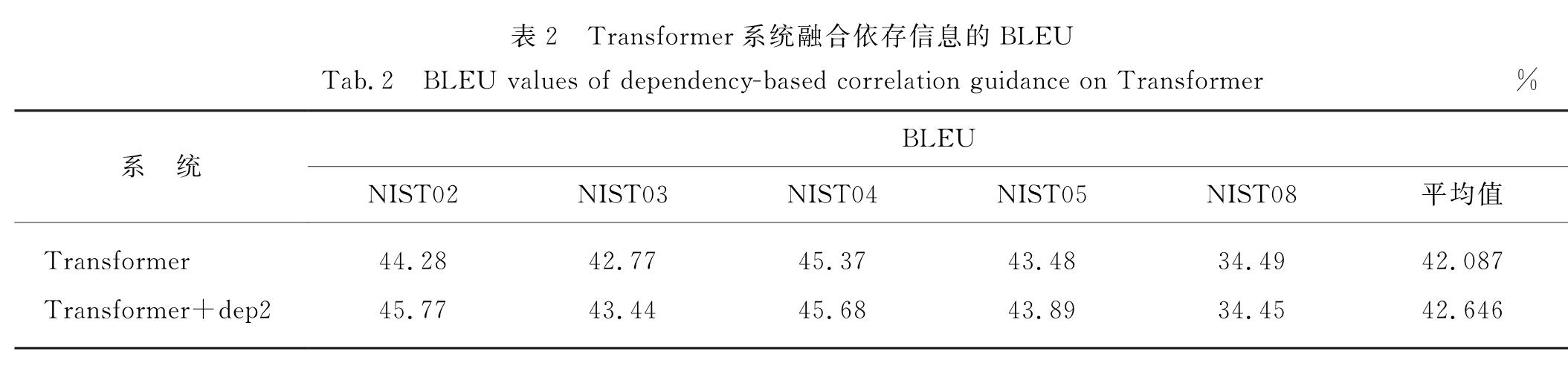
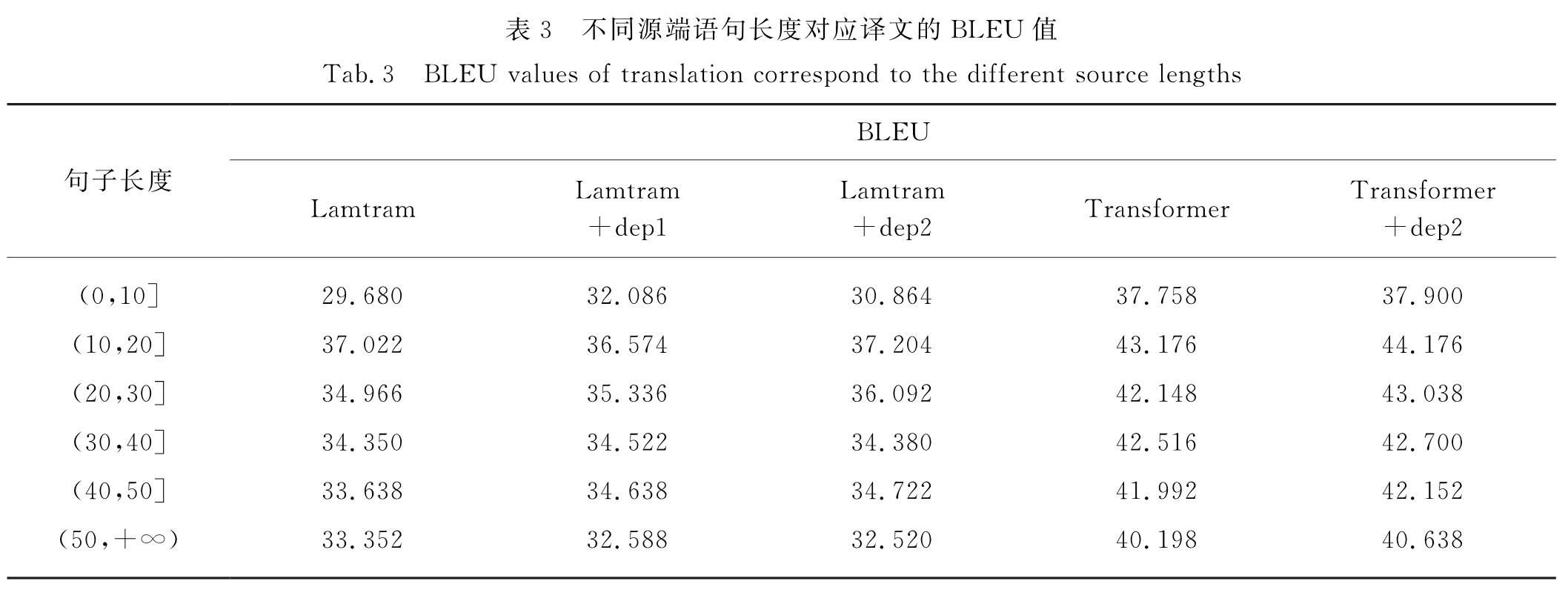
现有NMT模型注意力机制考虑目标端对应源端的关联信息,未对源端关联性进行建模.本文中提出对源端关联性建模,并融入依存关联指导,具体表现为:首先读取源端语句的依存信息,获取与当前时刻单词存在直接依存关系的词,对当前时刻的源端单词与和其有直接依存关系的词建立注意力机制,强化两者之间的权重关系,使源端单词与和其有直接依存关系的单词更相关.通过融入依存关联来指导机器翻译模型,构建更好的源端内在关联表示可以充分利用源端单词之间的关联性,加强单词之间的联系,提高机器翻译的质量.