收稿日期:2018-11-09 录用日期:2019-01-12
基金项目:国家重点研发计划(2016YFE0132100); 国家自然科学基金(61673289)
基金项目:国家重点研发计划(2016YFE0132100); 国家自然科学基金(61673289)
(School of Computer Science and Technology,Soochow University,Suzhou 215006,China)
DOI: 10.6043/j.issn.0438-0479.201811012
现有最先进的神经机器翻译模型大都依赖于多层神经网络结构,针对多层网络结构易导致信息退化的问题,提出通过融合层与层之间的输出信息来改善各个层之间的残差连接关系的方法,从而使得层与层之间联系更紧密.相比于原来的残差网络连接,进一步优化了深层网络的信息流动结构,使得整个结构有效信息流动更充分.在Transformer模型和序列到序列的卷积(convolutional sequence to sequence, Conv S2S)模型上进行相关实验,大规模中-英翻译任务的实验结果表明,该方法提高了Transformer和Conv S2S的翻译性能.
Since most advanced neural machine translation models depend on the multi-layer structure,it is easy to cause information degradation for multi-layer network structure.This paper improves the residual connection between layers by fusion the output information between layers and layers,thus shortening the layer-to-layer connection.Compared to the original residual network connection,this paper further optimizes the information flow structure of the deep network,making the whole structure more closely connected.In this paper,experiments are performed on the most advanced models "Transformer" and "convolutional sequence to sequence(Conv S2S)".Experimental results in large-scale Chinese-English translation tasks show that the information between layers and layers enhances translation performances of the Transformer and the Convolutional Sequence to Sequence.
机器翻译[1](machine translation, MT)是用来进行大规模语言翻译的有效工具,可以分为神经机器翻译[2](neural machine translation, NMT)和传统统计机器翻译[3](statistical machine translation,SMT).其中NMT因其翻译性能突出,已成为当下工业界和学术界研究热点.
Sutskever等[4]在2014年提出的一种基于编码器-解码器模型的MT方法; 2015年,Bahdanau等[5]在此工作的基础上通过引入注意力机制(attention mechanism)使得端到端的序列建模性能大幅度提升,NMT的性能达到了一个新的高度,超越了传统的SMT.Gehring等[6]提出了一个完全基于卷积神经网络(convolutional neural network,CNN)的体系结构——序列到序列的卷积(convolutional sequence to sequence[6], Conv S2S),使NMT的翻译速度和准确率进一步提升.之后Vaswani等[7]提出了一个新的模型架构Transformer,其既不基于循环神经网络(recurrent neural network, RNN),也不依赖CNN,仅通过注意力机制进行建模,其模型架构已成为目前最先进的MT模型架构,并应用到了其他领域.
由于多层网络能够捕获的特征信息更丰富而使得模型的表现更好,现在大部分先进的NMT模型均采用多层的深度神经网络架构,如Conv S2S、谷歌NMT(Google's NMT[8],GNMT)系统、Transformer[6]、基于RNN的NMT+(RNN-based NMT+[9],RNMT+)系统等,但多层的神经网络结构往往会存在梯度消失或者梯度爆炸的问题.这是因为深度神经网络中的梯度是不稳定的,梯度在层与层之间传播时有可能会非常大,也有可能会消失.这种不稳定性是深度神经网络中基于梯度学习的根本问题.
为使NMT捕获更充分的句子信息,Zhang等[10]通过联合一个相关网络到标准的端到端翻译系统,确保源端句子信息能够充分流动到解码端来提高神经系统的信息捕获能力,从而提升翻译性能.残差网络[11](residual network,ResNet)由于能够解决深层网络的退化问题,在深度学习图像识别领域中,有许多研究者对多层ResNet展开了研究.其中:Shen 等[11]提出了一个密度连接的 NMT架构,在多层神经网络架构中用密度连接替代残差连接,改善了翻译性能; Targ 等[12]提出了一个残差嵌套(ResNet in ResNet,RiR)网络,RiR是一个泛化ResNets和标准CNN的双流深度架构,在表现上超过了ResNet,并且没有增加额外的计算开销,在CIFAR-100中成为了最先进的架构; Veit[13]等提出了关于ResNet的新颖解释,ResNet是通过收集许多不同长度传输的信息来缩短信息传输路径,使神经网络能够在很深的网络中通过梯度传播; Yu等[14]提出的ε-ResNet架构相当于在原始ResNet中添加了一个修正线性单元,通过给定一个阈值ε来自动丢弃一些冗余层,以减少参数,加快训练速度并且不降低

图1 Transformer基准系统及其改进
Fig.1 Transformer baseline system and its improvement
性能.尽管采用了ResNet[15]能有效解决退化问题,但深层网络固有的信息捕获不充分的问题不能全部解决.为此,本研究参考Zhang等[16]改进Transformer加速模型,同时融合多层的信息来增加新的信息流动路径.与Zhang等[16]所提出的加速模型不同的是:Zhang等对解码端的自注意力机制层(self-attention layer)进行改进,提出平均注意力网络(average attention network)方法取代原有自注意力机制,使得模型在解码时,注意力仅依赖于当前时刻的输入以及上一个时刻计算的注意力权重,不需要对计算时刻前面所有时刻的注意力再进行计算,以此提高了模型解码速度; 而本研究则是对层的输出信息进行融合,即本研究在残差连接的基础上,通过融合多个层的输出信息得到一个融合信息,将融合信息连接到多层网络最终的输出上,以改善层与层之间信息流动关系,加强多层神经网络对信息的捕获能力,来提高NMT性能.
现有的NMT模型的架构大多基于注意力机制端到端建模方法,其中Transformer和Conv S2S也不例外.Transformer和Conv S2S的差异在于Transformer的子层结构采用自注意力机制,而Conv S2S采用卷积操作; 相同之处在于均采用多层结构对输入x=(x1,x2,…,xm)进行编码及解码,在生成y=(y1,y2,…,yn)的过程中,解码端多层解码依赖于解码端的最后一层(即第L子层)的输出,决定了yi+1对T个可能的候选目标词的概率分布可用式(1)描述:
P(yi+1|y1,…,yi,x)=softmax(WohLi+bo),
P∈RT.(1)
其中:hLi∈Rd表示第L个子层的第i个词的输出; Wo∈RT×d和bo∈RT是对解码端第L子层输出的线性变化权重和偏置量.
Transformer的主要特点在于它既不依赖于RNN,也不依赖于CNN,而仅通过自注意力机制计算输入x=(x1,x2,…,xm)和输出y=(y1,y2,…,ym)的表示,实现了端到端的NMT.自注意力机制是将句子中的每个词和该句子中的所有词进行注意力计算,目的是学习句子内部的依赖关系,捕获句子的内部结构.
Transformer的编码端和解码端的结构都是多层网络结构,如图1所示.其中编码端由N个相同的层组成,每一层有2个子层,第1个子层是自注意力机制层,第2个子层是一个前馈神经网络.
解码端也是由N个相同的层组成,每一层有3个子层,第1个子层是一个掩码多头的自注意力机制,第2个子层是对解码器输出的多头注意力机制,最后一个子层是前馈神经网络.
编码端和解码端的子层数目不同,可用变量L代表编码端(解码端)的最后一个子层,故编码端L=2N,解码端L=3N.对每一子层的输出都进行层的归一化处理,子层之间均采用残差连接进行连接,残差连接具体可以用式(2)表示:
hl=hl-1+sublayer(hl-1).(2)
其中:hl表示第l个子层的输出; sublayer表示该层中的函数功能; 如无特殊说明,本研究中均使用“+”表示采用残差连接.
Conv S2S的主要特点为:不依赖RNN,仅基于CNN实现序列到序列的建模; 相比于RNN模型,Conv S2S对所有元素的计算完全并行,可以在训练时充分利用硬件.Conv S2S编码端和解码端均是多层卷积结构,不同之处在于解码端的每一层中有一个独立的注意力模块,其具体结构如图2所示.在Conv S2S中由于没子层结构,故L=N.
为了实现很深的网络,同样采用了残差连接,其中残差连接同样可以用式(2)表示,在Conv S2S中卷积层的sublayer函数功能采用CNN实现,每一个卷积核的参数权重矩阵和偏置量为wl∈R2d×kd和bw∈R2d,将k个词的输出合并得到卷积层的输入X=[hli-k/2; …; hli+k/2],用卷积映射成输出元素Y=wlX+hlw,Y∈R2d,故第l个子层的输出可以用式(3)表示:
hli=hl-1i+v(Y).(3)
其中:v(Y)表示卷积操作函数功能; v是门控线性单元[17](gated linear units, GLU),其对输入矩阵Y=[A; B]的运算可用式(4)表示:
v([Y])=Aσ(B).(4)
其中:A,B∈Rd是门控线性单元的输入; 是矩阵对应元素相乘,故v([Y])∈Rd; σ是非线性激活函数.
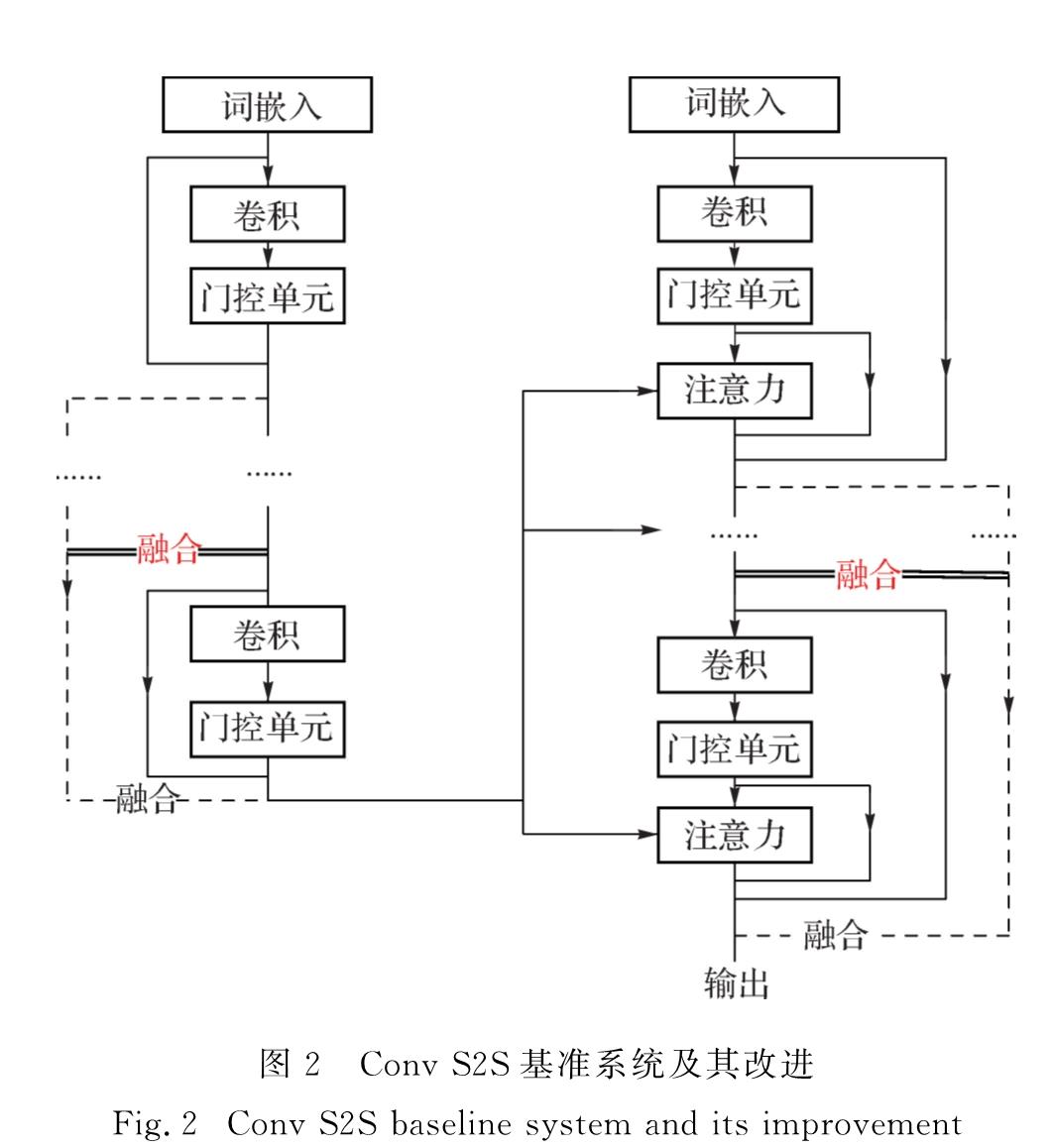
图2 Conv S2S基准系统及其改进
Fig.2 Conv S2S baseline system and its improvement
本研究用线性变换融合、算术平均融合和门机制融合3种不同的融合方法来融合层与层之间信息,得到融合后的信息f,再将f添加到最后一层的输出上,可以用式(6)描述:
hL=hL+f.(5)
1)线性变换融合方法可用式(6)所示.
f=Wconcat([h1; …; hL]),(6)
其中:concat(·)是一个拼接函数,对高维矩阵进行拼接操作; f∈Rd表示多层输出的融合信息; W∈Rd×Ld表示线性变换权重矩阵.
2)算术平均融合方法.即通过算术平均得到融合信息f,具体实现公式如式(7)所示.
f=(∑Ll=1hl)/L.(7)
3)门机制融合方法.由于层与层之间的信息彼此独立,融合时可考虑给不同层设置不同的权重来确定各层输出的融合比例(简称:门机制-层),本研究运用门机制作为信息融合方法.其具体实现主要是首先通过两次线性变换,分别采用tanh函数和softmax函数作为激活函数,如式(8)~(10)所示.
y1=concat([h1; …; hL]),(8)
y2=concat([h1,…,hL]),(9)
f=softmax(W2tanh(W1y1+b))y2,(10)
其中W1∈Rd×Ld,W2∈RL×d是可训练参数,y1∈RLd,y2∈RL×d分别表示不同维度上的合并操作.
门机制还可考虑对不同层间的隐藏层单元进行权重求和融合机制(简称:门机制-元)来对比分析,具体可以用式(11)表示:
f=∑Ll=1αhl.(11)
其中:α=hl
○ /
(∑Ll=1hl),
○ /
表示矩阵对应元素相除.
对于2.1节提出的多层融合机制,本研究进一步提出用多层信息进行多层融合的方法,以算术平均融合方法在Transformer模型架构上的应用为例进行描述.
Transformer模型中编码器的每一层由两个不同的子层组成,本研究在多层信息多层融合时对编码器端的第N层进行2层信息融合机制,即对编码器中的第N层的子层多头注意力机制层和前馈神经网络层进行融合.同理,解码器每一层由3个不同的子层组成,因此本研究多层信息多层融合时对解码端的最后一层(第N层,亦即第(L-2)~L子层)进行信息融合,即3个子层融合多层信息.以算术平均融合为例可用式(12)~(15)表示.
fl=(∑lj=1hj)/l,(12)
hL-2=hL-2+fL-2,(13)
hL-1=hL-1+fL-1,(14)
hL=hL+fL.(15)
其中:hl为第l个子层的输出,fl是第l个子层的融合信息.
由于Conv S2S层结构不同于Transformer,Conv S2S只有卷积层,无子层的结构,故本研究用最后2层进行信息融合实验,可用式(12),(14)和(15)表示.
本小节主要介绍多层信息融合与多层信息多层融合的Transformer和Conv S2S的改进系统,如图1和2所示.两幅图中,左右两个输入分别代表源端输入X和目标语言Y∧的位置编码以及词嵌入,每一个实线框代表基准模型的一个模块,“融合”表示加入融合方法,融合方法可以为3种融合方法中的任意一种.图1和2中虚线表示本研究多层信息融合新增的信息流动路径,对于多层信息融合,在双实线处不引入融合方法,只增加信息流动路径; 对于多层信息多层融合,在双实线处引入融合方法.
Transformer多层信息融合系统中包含掩码多头注意力机制,这是因为在Transformer的测试过程中,无法看到目标端的未来信息,故在训练时需要通过掩码注意力机制将未来信息进行掩码处理.解码端和编码端均是N层网络,中间重复部分图中未画出.Conv S2S信息融合模型系统中虚线表示的是最后一层应用融合方法的信息流动路径.
汉英语料的训练数据采用语言数据联盟(Linguistic data consortium,LDC)提供的汉-英平行语句对,分别选用美国国家标准与技术研究院2002年发布的数据NIST02、NIST03、NIST04、NIST05和NIST08作为测试集,NIST06作为开发集,其中每个测试集对应4个参考译文.训练集中过滤了长度超过50个单词的句子,过滤后的训练集为125万个句对.设置LDC语料中前3万个高频词作为词表,词表大小为3万,其余低频词用<UNK>替换.
英德语料,在IWSLT2016(https:∥wit3.fbk.eu/archive/2016-01/texts/en/de/en-de.tgz)英德语料上进行实验.实验前对原始数据进行预处理,对于训练语料,首先去掉文本中的标签,然后过滤源端和目标端的长度比超过1.5的语料对,过滤句长小于1或者大于175的句子,之后再将源端和目标端的语料统一为小写字符,最后在训练集中每23句取1句为验证集.预处理后,英德训练集包含185 148句对平行语料,验证集包含8 415个句子.对于测试集,将2010/2011/2012/2013/2014/去掉标签,进行分词后将字符统一为小写字符,然后合并成为测试集,包含大约8 000个句对.对语料进行比特对编码(byte-pair-encoding,BPE)(https:∥github.com/rsennrich/subword-nmt)处理,BPE是一种将低频词切分为更小的子词单元的组合,从而减少或消除词典中的低频词,在切分的字词单元前添加分割符@@,用以表示切分点,便于还原成源文本.本研究对训练集的源端和目标端进行联合BPE,设置BPE切分规则为1万,分别对训练集和验证集的源端和目标端进行BPE处理,对测试集的源端进行BPE处理,对于生成的测试集翻译文本,评测时去掉BPE分隔符@@,再使用multi-bleu.perl 脚本计算机器双语互译评估(BLEU)值[18].
基于开源代码tensor2tensor(https:∥github.com/tensorflow/tensor2tensor)实现本文提出的实验方法,将模型设置为Transformer,基本的超参数设置为tensor2tensor中的默认参数选项transformer_base_single_gpu.训练时,schedule设置为train,训练步数设置为250 000轮,最大保存模型数目设置为5; 解码时,采用集束搜索(beam search),其中beam_size设置为4,ALPHA设置为0.6,其余参数采用默认设置; 训练和测试均基于单个NVIDIA TITAN Xp GPU,对于评测,首先对最后5个模型进行模型平均,将平均后得到的平均模型作为评测模型.
本研究以tensor2tensor中实现的MT系统作为基准系统,并在其基础上实现了融合方法,通过对比实验,对比了Transformer基准系统和不同融合方法下的Transformer系统在汉英语料上的翻译结果,实验结果如表1~3所示.
由表1可知,在汉英语料上基准系统的BLEU值为40.51%.相对于基准系统,线性变换融合方法的BLEU值提升了0.16个百分点,算术平均融合方法提升了0.41个百分点,门机制-层融合方法的得分提升0.30个百分点,门机制-元融合方法的BLEU值提高了0.17个百分点.可见门机制-层的效果更好,故下文仅对门机制-层进行讨论.对比几种融合方法可以得出结论:本研究用3种不同机制融合层与层之间的信息,算术平均融合机制的翻译得分最高.

表1 Transformer及不同融合方法的BLEU值
Tab.1 BLEU score of Transformer with different fusion%
根据上述结论,在进一步进行多层信息多层融合方法时,均采用算术平均融合方法,实验结果如表1最后一行所示.多层信息多层融合方法比基准系统的BLEU值提高了0.51个百分点,达到41.02%,同时高于基于算术平均的多层融合方法,说明多层信息多层融合方法能更进一步提高NMT系统在汉英语料上的翻译性能.
根据表2可知,算术平均融合方法未引入新的模型参数,对Transformer模型的运算速度影响较小,而线性平均和门机制-层融合方法引入了新的权重参数,运算速度明显降低.由此可知,算术平均融合方法在速度上表现更好.
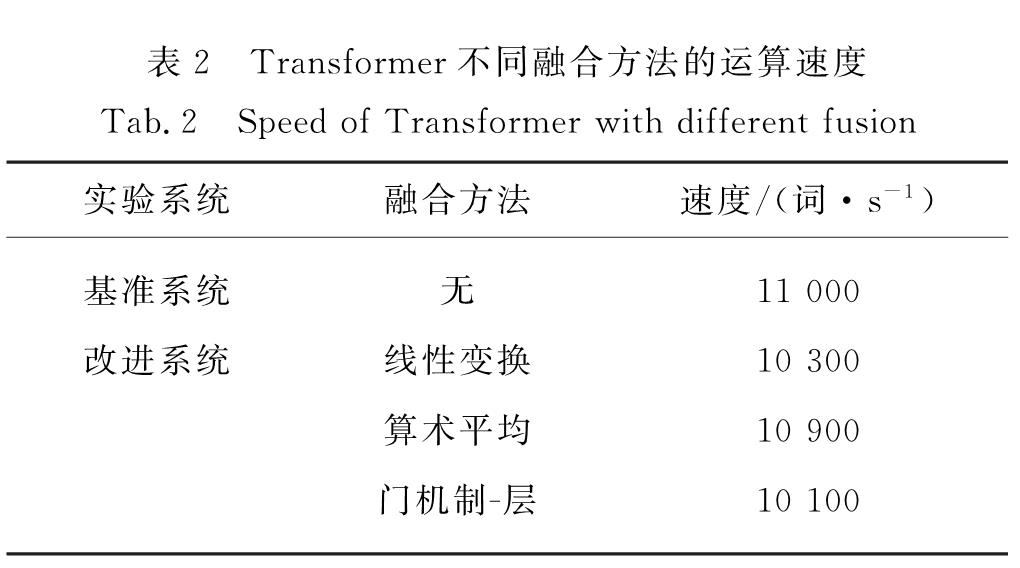
表2 Transformer不同融合方法的运算速度
Tab.2 Speed of Transformer with different fusion
层与层之间的信息流动主要改善的是对信息的捕获能力,通过漏翻情况可以用来评估信息捕获能力.本研究用通过不同融合方法改进得到的Transformer模型的一元语法BLEU值来评价MT中的漏翻情况.一元语法BLEU值能够真实地翻译源端词正确出现在翻译文本中的比率,有效地评价漏翻现象[19].一元语法BLEU值越高,表明对源端输入文本的翻译词越准确,不容易出现漏翻情况.实验结果如表3所示.
由表3可知基准系统的一元语法BLEU值达到了76.7%,算术平均融合方法的一元语法的BLEU值仍提升了0.4个百分点,表明算术平均融合方法对汉英翻译的信息捕获能力有所帮助,降低了出现漏翻的可能性.
进行英德语料实验时,由于英德语料数据量小于汉英语料数据量,故训练步数设置为80 000轮, 其余与汉英实验相同.
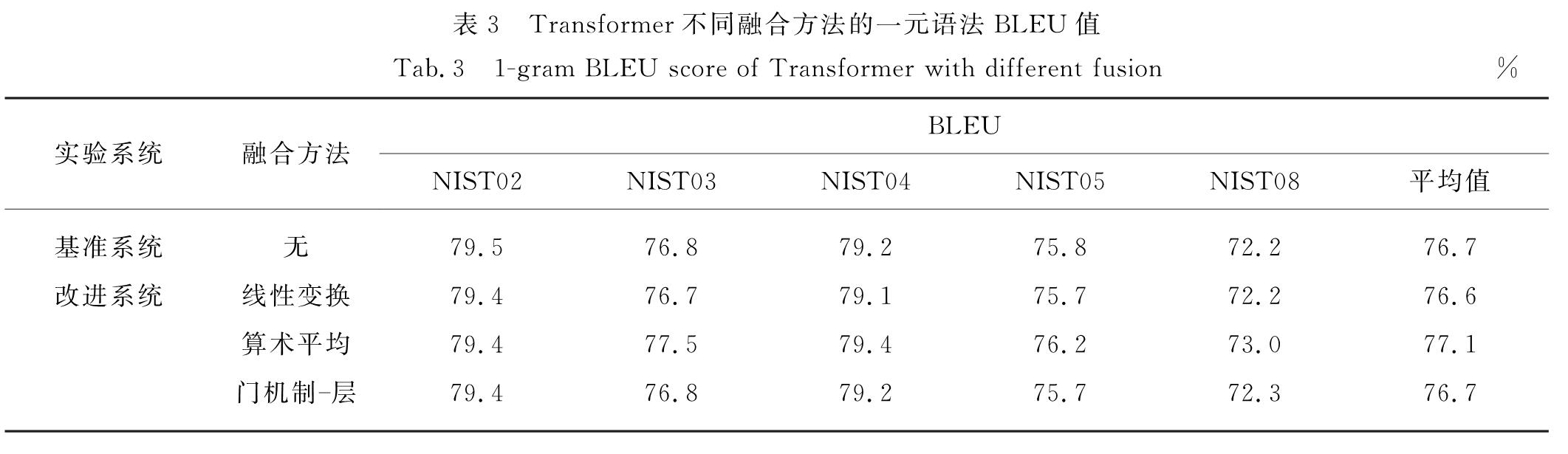
表3 Transformer不同融合方法的一元语法BLEU值
Tab.3 1-gram BLEU score of Transformer with different fusion%
本研究对比了在Transformer基准系统以及引入了不同融合方法的Transformer改进系统在英德语料IWSLT 2016上的翻译结果,如表4所示.
据表4第3列可知,线性变换和算术平均融合方法对翻译性能都有明显的改善,分别提升了0.36和0.37个百分点; 显著性检验表明,线性变换和算术平均融合都显著改善了翻译文本的BLEU值得分. 同样对多层信息多层融合在IWSLT2016英德语料上进行实验,实验结果如表4最后一行所示.相比于基准系统,其BLEU值提升了0.35个百分点; 同样经过显著性检验,具有显著性提升.
数据规模越大会模型的泛化性能越强[20],反之亦然.由于英德语料小于汉英语料,德英语料的实验效果会与汉英语料的实验表现存在一定差异,从德英语料实验结果来看,线性融合、算术平均、门机制-层以及多层信息多层融合的BLEU值非常接近,其中多层信息多层融合的实验效果也未能在算术平均的基础上有进一步的提升.

表4 不同融合方法下Transformer系统的英德语料翻译结果
Tab.4 Translation results of German-English on Transformer systems with different fusion ways%
同样对英德语料实验进行信息捕获分析,一元语法BLEU值分析结果如表4第3列所示.结果表明:线性变换、算术平均和门机制-层融合方法均在一定程度上改善了英德语料中一元语法的BLEU值,改善了漏翻的情况.
Conv S2S模型在开源工具fairseq(Facebook AI research sequence-to-sequence toolkit, https:∥github.com/pytorch/fairseq)中已经实现.本研究使用该工具实现本研究所提出的方法.基本参数设置:Conv S2S模型在编码端和解码端的卷积层数都设置为16层,维度都设置为256维; 同时所有的词嵌入和输出层的大小都设置为256维,包括从词嵌入的大小映射到隐藏层维度的时候; 卷积核设置为固定大小3; 实验依旧调用了fairseq自带的优化器nag,学习率设置为0.25,在学习率低于10-5时结束训练,超参数max_tokens设置为6 000,神经元随机失活率(dropout)为0.2,其余参数都为默认值.实验在训练和评测的时候,均采用单个NVIDIA GTX 1080 GPU.汉英语料实验和英德语料实验设置相同.
本研究在Conv S2S上进行实验,运算中将每层ResNets的输出信息先用中间变量对值进行存储,并在卷积的最后一层之后将获取的信息运用不同融合方式融合到最后的输出结果,基于Conv S2S系统的实验结果如表5所示.
由表5可知,线性变换融合方法性能有微小的下降,算术平均和门机制-层融合方法均显著提升,其中算术平均融合方法的BLEU值为38.43%,与Conv S2S基准系统的BLEU值比较提升了1个百分点.由于Conv S2S没有子层结构,本研究在Conv S2S的最后2层加融合方法,实验结果如表6最后一行所示.在最后2层加融合方法,最终在基准系统的BLEU值上提升了0.86个百分点,得分达到了38.29%.结论:在Conv S2S上最
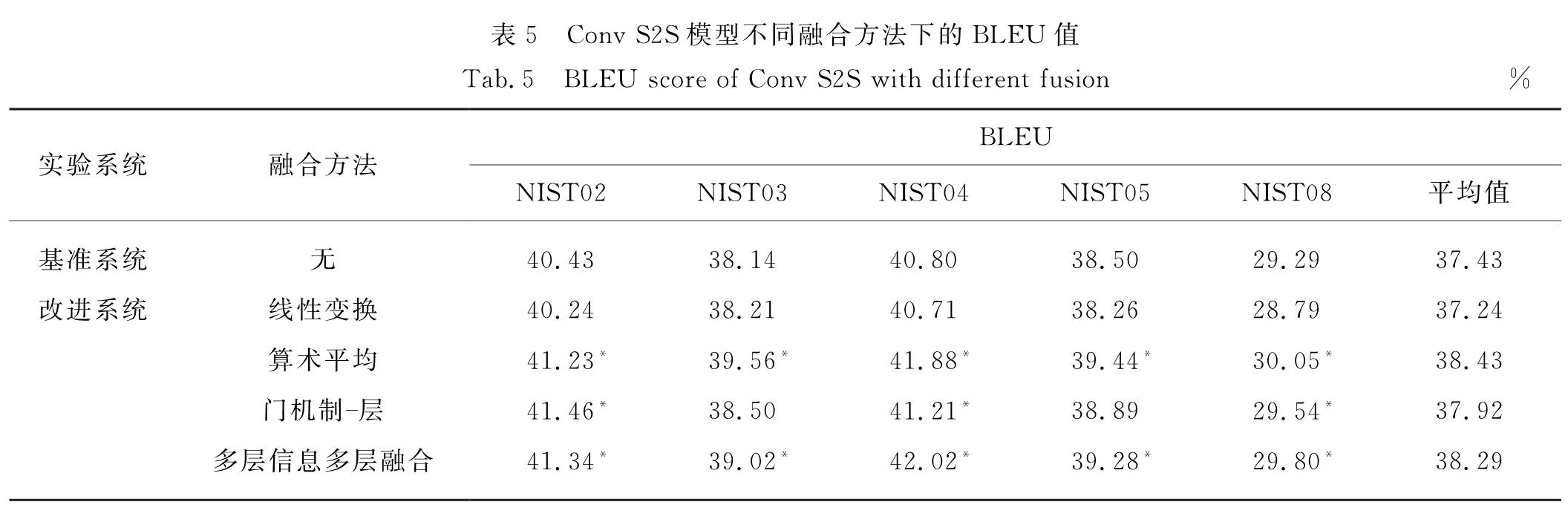
表5 Conv S2S模型不同融合方法下的BLEU值
Tab.5 BLEU score of Conv S2S with different fusion%
后2层进行融合方法,有显着提升.但是总体上,仅在最后一层上用算术平均融合的方法表现更好.
根据表6所示,与其他2种融合方法的速度相比,算术平均融合方法对运算速度影响较小,优于其他2种方法.

表6 Conv S2S系统不同的融合方法下的运算速度
Tab.6 Speed of Conv S2S with different fusion method
同样,本研究根据翻译结果的一元语法BLEU值来统计Conv S2S的漏翻情况,实验结果如表7所示.表7结果显示:3种不同的信息融合方法相较于基准系统的一元语法 BLEU值,均有一定程度的提升,说明融合方法有助于信息捕获,同时也可以看到算术平均融合方法的一元语法BLEU值比基准系统的一元语法BLEU值(74.7%)提升了1.1个百分点.
本研究对比了Conv S2S基准系统与本研究提出的3种不同的融合方法改进的Conv S2S系统的英德语料翻译效果,结果如表8所示.
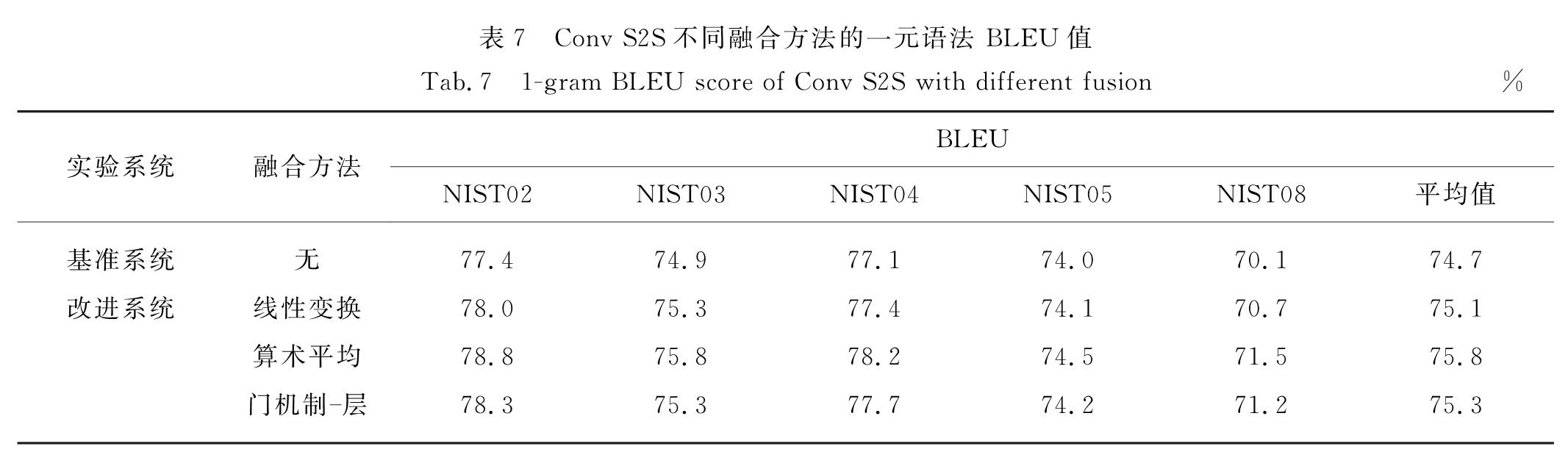
表7 Conv S2S不同融合方法的一元语法 BLEU值
Tab.7 1-gram BLEU score of Conv S2S with different fusion%
由表8第2列知,线性变换、算术平均和门机制-层融合机制对Conv S2S系统在英德语料上的翻译性能均有明显的改善,其BLEU值相对于Conv S2S基准系统,提升了1.04~2.31个百分点; 显著性检验表明:线性变换、门机制和算术平均融合都显著改善了翻译文本的BLEU值得分.
同样对多层信息多层融合在IWSLT2016英德语料上进行对比实验,实验结果如表8最后一行所示.相比于基准系统,BLEU值提升了2.66个百分点,同样经过显着性检验,具有显着性提升.
进一步对英德语料进行信息捕获分析,一元语法的BLEU值分析结果如表8第3列所示.结果表明:线性变换、算术平均和门机制-层融合方法均改善了英德语料的一元语法 BLEU值,其中算术平均融合方法改善的最为明显,相比于基准系统的一元语法的BLEU
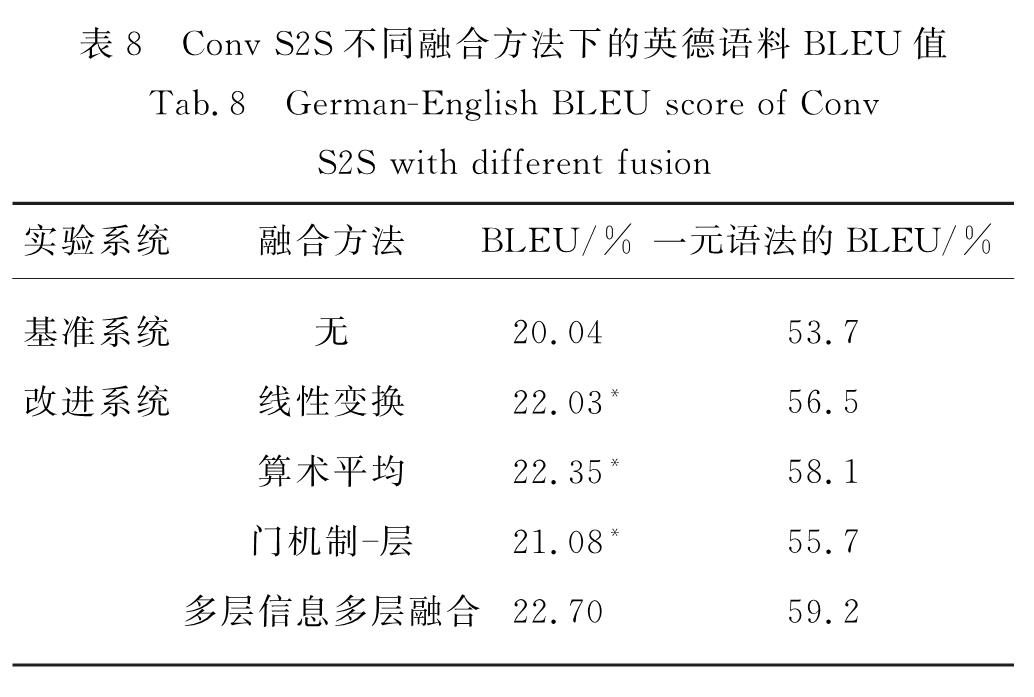
表8 Conv S2S不同融合方法下的英德语料BLEU值
Tab.8 German-English BLEU score of Conv S2S with different fusion
值提高了4.4个百分点.
表9给出了从汉英平行语料的测试集中挑选出的句子,用于说明多层信息多层融合技术对NMT系统翻译效果的改善.对比参考译文,Conv S2S基准系统生成的译文丢失了主语“公众”.Conv S2S加上算术平均融合方法后的翻译译文对“公众”的翻译为“the public”,翻译正确,相比于基准系统译文,也显得更加通顺.

表9 译文示例
Tab.9 Example of translation
本研究针对多层神经网络的信息捕获不足问题,提出了多层信息多层融合的方法.本研究在Transformer模型和Conv S2S模型上进行了相关实验.实验的结果表明,多层信息多层融合技术可以捕获更多有效信息表征,提高NMT模型的性能.在未来的工作中,将对多层信息融合位置、多层信息融合方法、信息流动等方面做进一步探讨.
