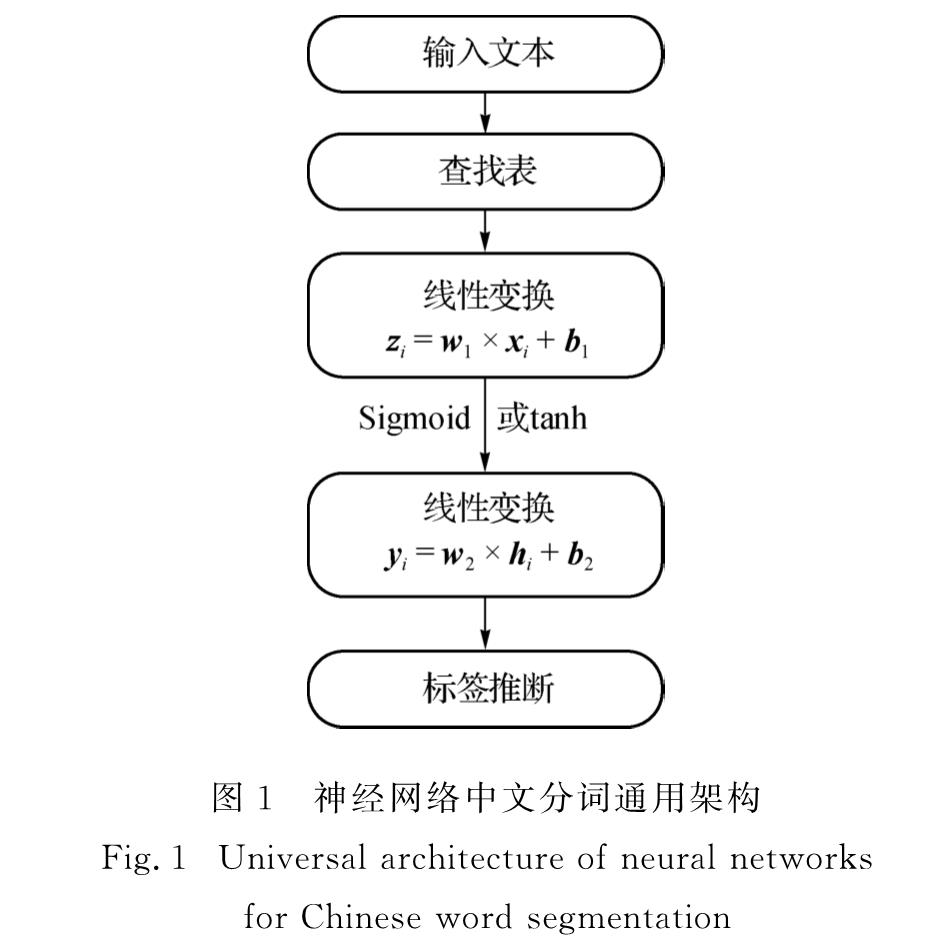
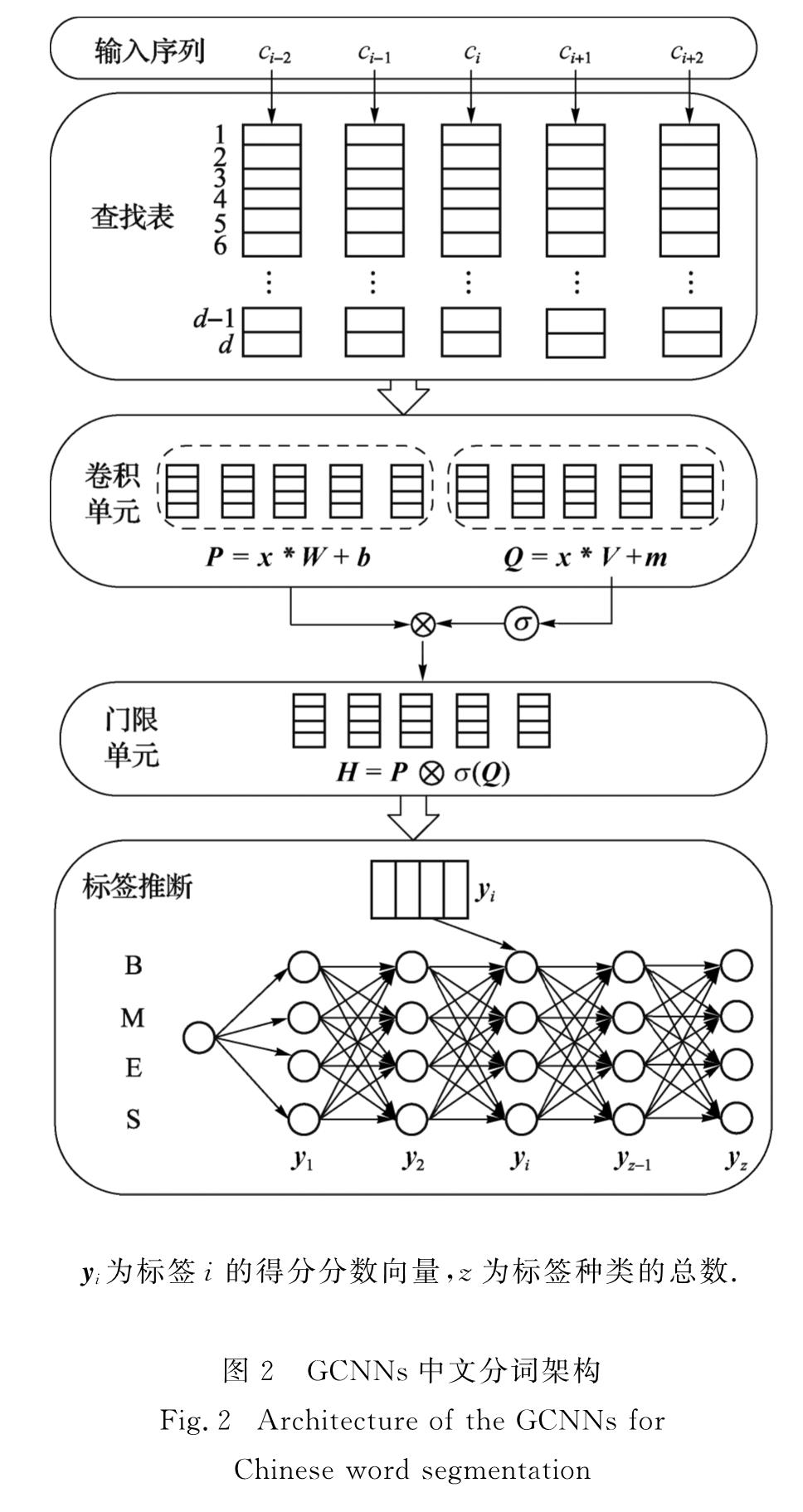
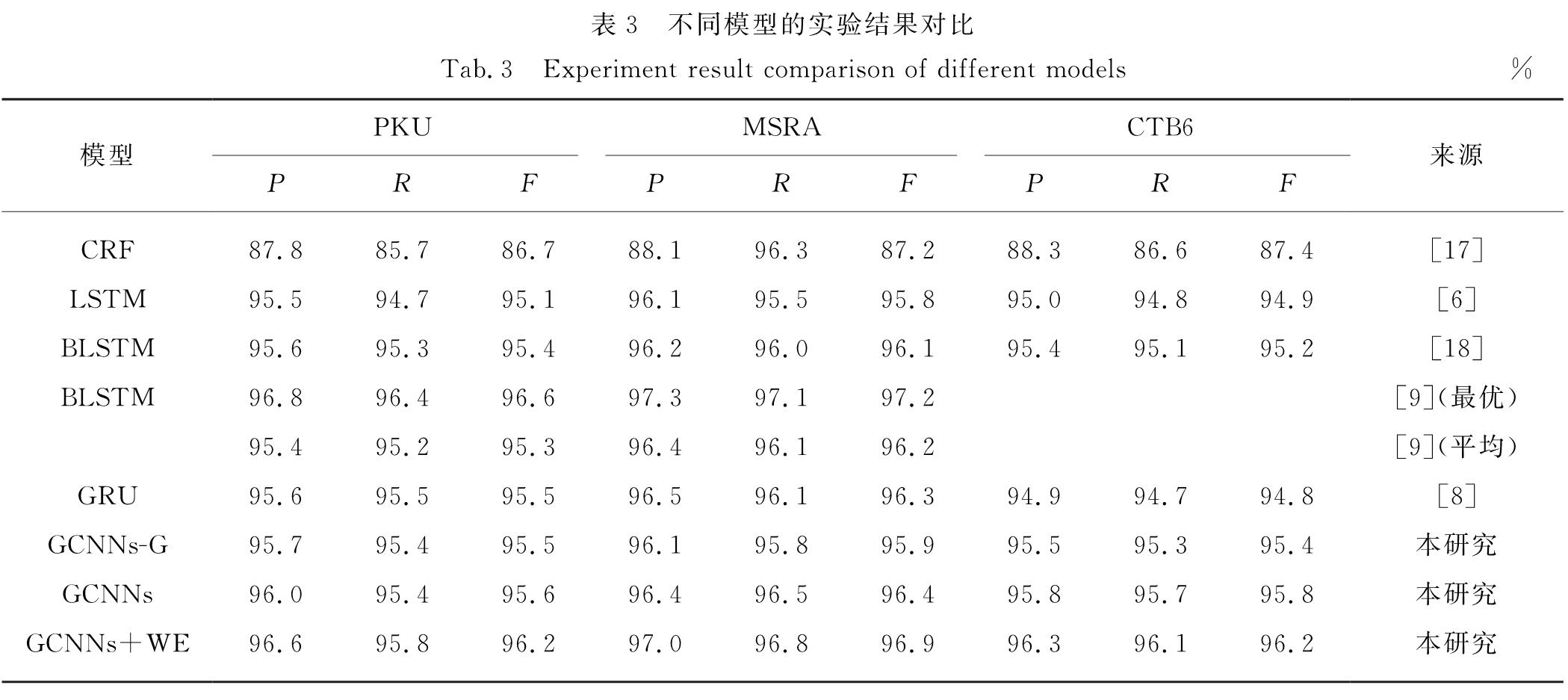
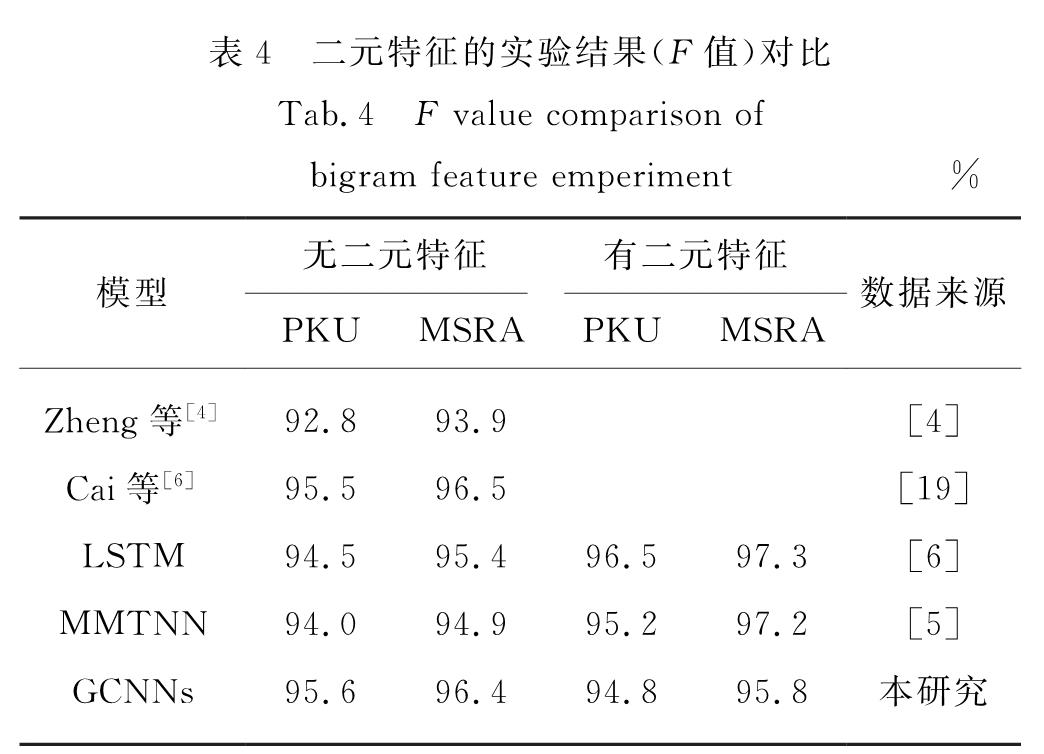
基于GCNNs模型的中文分词架构如图2所示,包括输入层、具有门限机制的卷积层以及标签推断层.对于输入句子c,GCNNs先用多个具有门限机制的卷积层来获取上下文的向量表示,再用标签推断进行分词预测.此外,本研究还利用半监督学习的方法将词向量融入到GCNNs模型中.
yi为标签i的得分分数向量,z为标签种类的总数.
图2 GCNNs中文分词架构
Fig.2 Architecture of the GCNNs for Chinese word segmentation
2.1 输入层
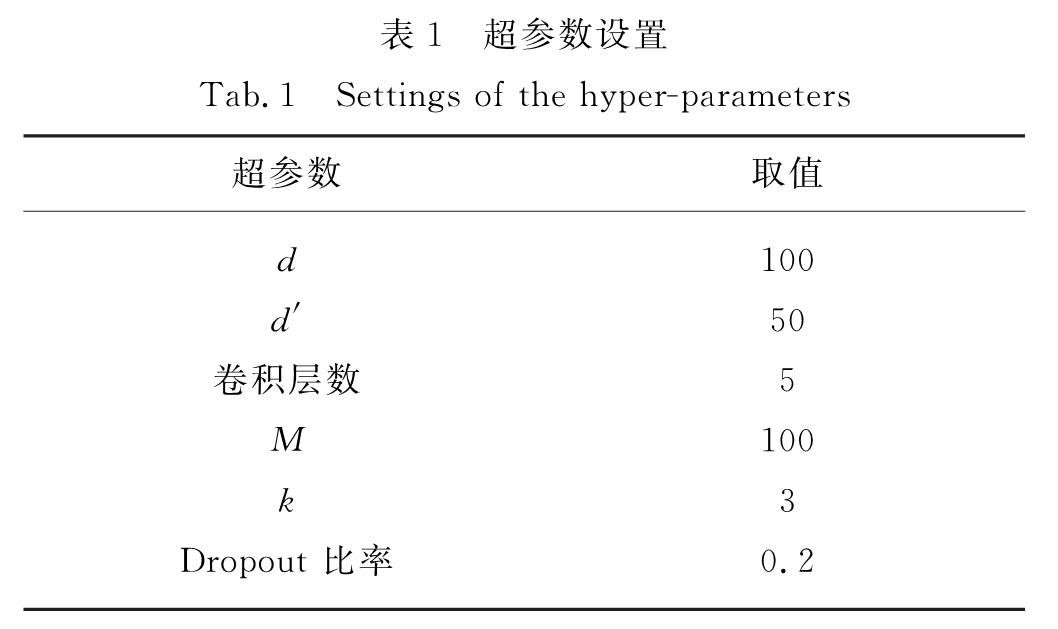
利用深度神经网络处理一个句子时,主要是将句子中的字符借助于查找表转换成以向量表示的形式.查找表可以视为一个投影层,通过字符在词汇表中的索引得到对应的字向量.从字符到字向量的查找表定义为Lchar∈R|Vchar|×d,其中|Vchar|表示词汇表的长度大小,即词汇表中词的数量,d表示字向量的维度.对于一个给定的c,其经查表后得到的表示矩阵x∈Rn×d,其中第i行就是字符ci的字向量.
2.2 具有门限机制的卷积层
基于卷积训练速度快、自我学习能力强的特点,GCNNs模型引入了门限结构单元(gated linear unit,GLU)[12].与LSTM中的门限机制相比,GLU舍弃输入门和遗忘门,仅保留输出门,能够在保留非线性功能的同时,允许梯度沿着线性单元进行传播而不会被缩减.GLU的梯度表达式为
Δ[Xσ(X)]=ΔXσ(X)+Xσ'(X)ΔX,(1)
其中,表示元素积运算,ΔXσ(X)没有缩减因子[12],因此梯度弥散问题便得以缓解.将GLU作为非线性结构单元与卷积单元结合,形成一个卷积层.与普通卷积不同的是,门限卷积H在这里分为两部分:一部分是卷积激活值P,本研究没有使用tanh函数,而是用线性函数.另一部分是σ(Q),其中门限值Q是通过直接线性函数得到,具体如图2所示.具有门限机制的卷积层的具体表达式为:
H(x)=(x*W+b)σ(x*V+m),(2)
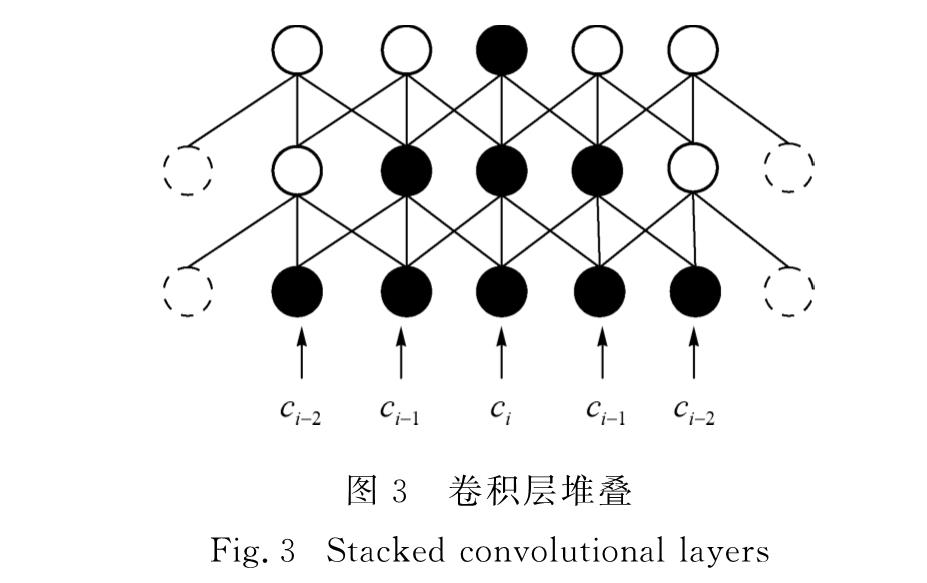
其中:W和V是卷积层的权重,b和m是卷积层的偏置项,*表示卷积操作运算,W∈Rk×d×M,b∈RM,V∈Rk×d×M,m∈RM分别是要学习的参数,M为每个卷积层中输出节点的个数.本研究使用多个卷积层堆叠进行标识长文本,学习更高层、更抽象的特征,从而解决长距离依赖问题.图3所示为两层卷积堆叠时的处理过程,其中最底端为输入层,虚线圆圈表示边界填充.在最顶端,通过线性变换将该层的输出转换为标签集中的得分矩阵E=(yi)∈Rn×z.
图3 卷积层堆叠
Fig.3 Stacked convolutional layers
2.3 标签推断
由于在一个c中,相邻字符标签之间有很强的依赖性,所以对于序列标注任务,通常要考虑相邻标签之间的依赖性.本研究采用文献[13]中提出的权重转移矩阵T来表示这个依赖关系,矩阵中的每一个元素Tyi,yj表示从标签yi到标签yj的转移概率,其数值越大,转移的概率越大,数值由训练得到.对于句子c,其对应标签序列yi的得分S定义为:
S(yi)=∑nt=1(T(yi-1)t,(yi)t+Et,i).(3)
2.4 词嵌入
对于基于字符的中文分词模型,具有灵活、高效的优点,但这类模型很难融入词向量信息.而基于词的中文分词模型,不仅可以运用字向量信息,还能使用词向量信息,字向量和词向量的最大区别在于二者是语言表示的两个粒度,其包含的信息不同.本研究使用词嵌入方法将词向量和GCNNs模型相融合.由于汉语中很少出现长度大于4个字符的词,所以本研究将最大的词长度设置为4,即给定句子中的一个字符ci,其可能和周围字符组成词的最大长度为4,如cici+1ci+2ci+3和ci-1cici+1ci+2等.为了利用一个字符ci周围的词信息,本研究将表示ci的字向量和包含该字符的词向量进行串联拼接,同时为了避免拼接后出现控制输入大小不同的问题,利用前文中以数字0作为填充的方法使输入大小保持一致.此外,由于所有可能的四元特征的数目是巨大的,会产生极大的特征空间O(|V|4),其中|V|为语料库的大小.所以,本研究采用如下方法来缩小特征空间并避免数据稀疏问题:1)训练一个不依赖于词特征的父模型(parent-model); 2)用该模型对无标签数据D进行分词得到D'; 3)从D'构建一个词汇表Vword,其中出现次数小于5的词会被舍弃,并将没有出现在词汇表Vword中的词替换为UNK; 4)利用word2vec[14]在D'上训练词向量; 5)使用上一步训练好的词向量作为词特征训练子模型(sub-model).本研究令GCNNs模型作为父模型,使用词嵌入方法引入词向量,经上述步骤训练得到最终子模型GCNNs+WE.值得指出的是,在进行词嵌入时,查找表获得词向量的过程与上文查找表获得字向量的过程不同,为了提高计算效率,词向量的维度d'小于d.
2.5 模型训练
模型训练的目标是使分值最高的标签序列和正确的标签序列得分相同.对于输入句子c和正确的标签序列y,设模型预测的标签序列为y',则分数最高的标记序列y*可表示为
y*=argmax(S(y')),y'∈Y,(4)
其中,y*∈Y,Y是该句子所有可能标签序列的集合.对于y和y',定义结构损失函数为
Δ(y,y')=∑zi=1γ1{yi≠yi'},(5)
其中γ是调节比例的参数.该损失函数表示在模型预测的标记序列中,预测结果不正确的标签数量占总数量的比值,为了使y*与y相同,定义训练目标函数为
J=1/(|N|)∑c∈Nl,(6)
其中,N为训练集大小,l=max(0,S(y')+Δ(y,y')-S(y)).在模型训练过程中,通过反向传播[15]使损失函数最小.