(1.中国科学院自动化研究所,模式识别国家重点实验室 北京 100190; 2.中国科学院大学计算机与控制学院,北京 100190; 3.中国科学院脑科学与智能技术卓越创新中心,北京 100190)
(1.National Laboratory of Pattern Recognition,Institute of Automation,Chinese Academy of Sciences,Beijing 100190,China; 2.School of Computer and Control Engineering,University of Chinese Academy of Sciences,Beijing 100190,China; 3.Center for Excellence in
DOI: 10.1016/j.neucom.2017.01.121.
备注
Document-level sentiment classification aims to infer user's sentiment polarity in a review.However,most of existing methods only focus on text information and ignore user information and aspect information.Different users may use different words to express their opinions and pay their attentions to different aspects about a product.Words describing different aspects may induce different sentiment polarities.These two kinds of information are helpful to sentiment classification.To consider these two kinds of information,we propose a model called hierarchical user aspect attention networks(HUAAN),which can encode different kinds of information(word,sentence,aspect,document)in a hierarchical structure and import the user-and-aspect-attention mechanism to model user information and aspect information.Empirical results on two real-world document-level review datasets show that our model obtains the best classification in the same condition.The accuracy rate of sentiment classification is higher than the system of NSC+UPA-pro.
引言
高速发展的互联网给用户提供了众多的服务和产品评论平台,例如餐饮领域的大众点评和Yelp、电影领域的豆瓣电影和互联网电影资料库(IMDb)等.这些平台包含了大量的用户评论,对这些评论文本进行情感分类是自然语言处理领域的研究热点之一.本研究关注的任务是文档级别的情感分类,目的是根据文本所表达的含义和情感信息将文本划分成两种(褒义的或贬义的)或几种类型[1].传统方法[2-5]主要是从文本中抽取特征,用机器学习的方法训练分类器,分类效果取决于特征的手动设计和选择.
继深度学习方法在计算机视觉、语音识别等领域取得成功之后,越来越多的学者关注如何用这项技术来提高情感分类的效果[6-9].基于深度学习的文本情感分类较传统方法在准确率上有了大幅提升,但现有模型仍然存在着一个缺点:这些模型只考虑文本信息而忽略了评论发布者以及评论中评价对象的信息,然而这两类信息对情感分类是非常有用的,主要体现在三个方面:1)用户的用词差异.不同的用户有着各自的用词习惯和特点.假设评论的得分范围为1~3分(其中1,2和3分分别表示贬义、中性和褒义),一个苛刻的用户可能在评论中屡次出现“好”,“不错”等这样表现强烈褒义的词汇,但是最后的整体得分可能是2分.而在一个较为随意的用户发表的评论中,可能会出现“一般”“还行”等,最后的得分却是3分.充分考虑不同用户的用词习惯,对情感分类是有帮助的.2)用 户对不同评价对象的不同偏好.面对同一个产品,不同的用户可能会关注它的不同属性,这些属性也常被称为评价对象.例如在酒店领域,评价对象包括“服务”、“价格”、“地理位置”等,在选择酒店时,一些用户可能会比较在意“价格”,而另外一部分用户可能会更关注于“地理位置”.针对不同的用户,区别对待这些评价对象对情感极性判别会有帮助.3)评价对象的修饰词差异.同样的词汇修饰不同的评价对象可能表达不同的情感极性.比如“长”这个评价词,修饰“手机的待机时间”时,表示的是褒义,修饰“酒店的服务等待时间”时,表示的是贬义.因此需要根据不同的评价对象区分对待词汇.
针对用户的用词差异,文献[10-12]在传统的神经网络的模型中融入了用户信息,使得该模型可以捕捉用户在选词上的差异性,然而上述工作没有考虑用户对不同评价对象的不同偏好以及评价对象的修饰词差异.为了能将这两类信息充分考虑,本研究提出了一个基于用户和评价对象的层次化注意力网络(hierarchical user aspect attention networks,HUAAN)模型,该模型首先利用一个层次化的神经网络结构来编码不同层级的信息,包括词汇层、句子层、评价对象层以及文档层; 然后为了同时考虑用户在用词上的差异和对评价对象的不同偏好,在得到词汇层和评价对象层的表示之后,引入了基于用户的注意力机制来区分对待不同的词汇和不同的评价对象; 最后为了考虑评价对象的修饰词差异,还引入了基于评价对象的词汇层注意力机制来区分对待不同的评价对象对上下文词汇的影响.
1 HUAAN模型
HUAAN模型的整体结构如图1所示,一共包含了5个部分:词汇层编码、词汇层注意力机制、句子层编码、句子层注意力机制和评价对象层注意力机制.表1给出了本研究使用的一些数学符号及其物理意义.
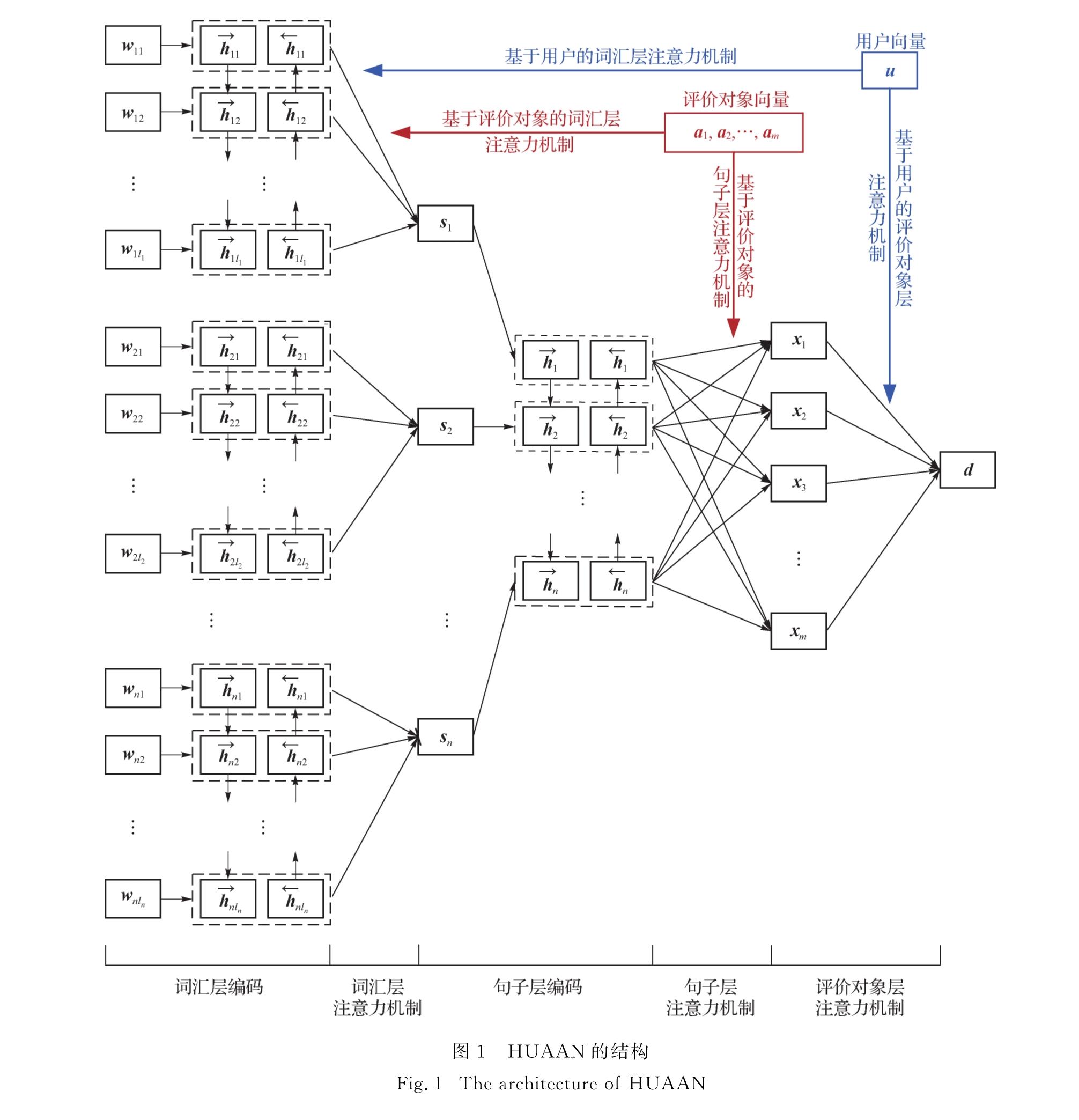
图1 HUAAN的结构
Fig.1 The architecture of HUAAN
表1 本研究使用的一些数学符号
Tab.1 Summary of notations used in this paper假设有一个关于某个领域(例如酒店)的评论文本的数据集D,该领域有m个评价对象a1,a2,…,am, 它们分别表示“服务”、“位置”和“食物”等.d是D中的一篇评论文本,它的发布者为u.为了获取评论文本描述的评价对象,本研究采用文献[13-14]提出的关联规则挖掘算法为每个句子赋予一个评价对象集合,这部分内容将在2.1节详细介绍.下面将介绍HUAAN基于长短时记忆网络(long short-term memory network,LSTM)[15]的序列编码模块及HUAAN的其它各个组成部分.
1.1 基于LSTM的序列编码由于HUAAN的建模过程是从词汇到句子,再从句子到文档,并且句子是一个词汇的序列,文档是句子的序列,因此序列模型是HUAAN的一个基本模块.该模块使用的模型是LSTM模型.LSTM是循环神经网络的一种特殊形式,它通常被用于处理序列数据并且可以避免传统循环神经网络出现的梯度爆炸或者是梯度消失的问题.LSTM通过引入记忆单元和门的机制来捕捉序列中长距离的依赖关系.LSTM的计算公式如下:
it=σ(Wixt+Uiht-1),(1)
ft=σ(Wfxt+Ufht -1),(2)
ot=σ(Woxt+Uoht -1),(3)
ct^~=tanh(Wcxt+Ucht -1),(4)
ct=ft⊙ct-1+it⊙ct^~,(5)
ht=tanh(ot⊙ct),(6)
其中:σ表示logistic sigmoid函数; ⊙表示点乘的操作符; it、ft、ot和ct分别表示t时刻的输入门、遗忘门、输出门和记忆单元的激活向量,这些向量和隐层向量ht拥有相同的维度; Wi、Wf、Wo、Wc和Ui、Uf、Uo、Uc分别表示LSTM模型输入门、遗忘门、输出门和记忆单元的关于输入向量和隐层向量的模型参数.
1.2 HUAAN模型基本部分介绍词汇层编码:HUAAN首先将句子si中的每个词wij编码成向量wij,然后使用双向LSTM来编码wij的上下文信息,从而得到它的隐层表示.具体计算方法如下:
h^→ij=LSTM^→(wij),(7)
h^←ij=LSTM^←(wij),(8)
hij=h^→ijh^←ij.(9)
其中:LSTM^→(·)和LSTM^←(·)分别表示前向LSTM和后向LSTM的过程; 是连接符号,将两个向量连接在一起.
词汇层注意力机制:句子中所有的词汇在组成句子的表示时具有不同的重要性,并且不同的用户有着不同的用词习惯以及同一个词汇修饰不同的评价对象时体现的情感极性可能会有差异.于是,本研究引入基于用户和评价对象的注意力机制来区别对待句子中不同的词汇,计算方式如下:
si=∑</sub>jαijhij,(10)
其中,αij 度量的是在考虑用户信息和评价对象信息后,句子中第j个词在构建整个句子si的表示时的重要程度.用户u和评价对象ai被编码成向量u和ai. 由于句子si可能会包含多个评价对象,这些评价对象向量的平均向量ti被用来表示这个句子中评价对象的编码向量:
ti=(∑jAijaj)/(∑jAij).(11)
然后用式(12)和(13)计算αij:
mij=vTwtanh(Ww hhij+Ww uu+Ww ati+bw),(12)
αij=(exp(mij))/(∑jexp(mij)),(13)
其中,mij为未归一化的注意力权重αij对应的值,vw、Ww h、Ww u、Ww a和bw分别表示计算mij时的前馈神经网络中对应的点积权重、隐层向量权重、用户向量权重、评价对象向量权重和偏置.
句子层编码: 在得到句子向量si之后,本研究使用双向LSTM编码句子并得到隐层表示hi:
h^→i=LSTM^→(si),(14)
h^←i=LSTM^←(si),(15)
hi=h^→ih^←i.(16)
句子层注意力机制:这里介绍的是如何从句子层的表示得到评价对象层的表示.由于一篇评论中可能会有几个句子同时描述同一个评价对象,然而这些句子对形成该评价对象的表示时所起的作用是有差异的.句子的前后顺序以及句子之间的关系可能都会影响该句子在构成某评价对象表示时的重要性.于是本研究采用句子层注意力机制对这类差异进行建模,其计算公式如下:
li k=vTstanh(Ws hhi+Ws aak+bs),(17)
βi k={0,∑iAi k=0,
(Ai kexp(li k))/(∑iAi kexp(li k)), ∑iAi k≠0,(18)
xk=∑iβi khi,(19)
其中,li k为未归一化的注意力权重βi k对应的值,vs、Ws h、Ws a和bs分别指的是计算li k时的前馈神经网络中对应的点积权重、隐层向量权重、评价对象向量权重和偏置.
评价对象层注意力机制:对于同样的产品或者是服务,不同用户关注的东西会有差异.这种差异会导致最后的文档表示的不同,进而影响情感分类的结果.因此HUAAN在评价对象层时使用基于用户的注意力机制来区分对待不同的评价对象,并最终得到整个评论文本的向量表示d[16-17]:
ri=vTatanh(Wa hxi+Wa uu+ba),(20)
γi=(exp(ri))/(∑iexp(ri)),(21)
d=∑iγixi,(22)
其中,ri为未归一化的注意力权重γi对应的值,va、Wa h、Wa u和ba分别表示计算ri时的前馈神经网络中对应的点积权重、隐层向量权重、用户向量权重和偏置.
1.3 文档级别情感分类计算得到评论文本向量d后,可通过式(23)计算出评论文本d属于各个类别的概率分布P,
P=softmax(Wlhd+b),(23)
其中Wlh和b分别表示计算概率时的softmax层对应的权重参数和偏置.
最后采用最小化负对数似然为训练目标:
L=-∑d∈D∑Cc=11{gd=c}log(Pc),(24)
其中,1{·}是一个示性函数,当函数内部值为真时,返回1,否则返回0.
2 实验与分析
2.1 实验设置为了验证HUAAN的有效性,在数据集IMDb和 Yelp2014中进行测试,这2个数据集为Tang等[10]构建的公开数据集.在进行测试之前,需对数据进行预处理,本研究采用 Stanford CoreNLP[18]对数据进行预处理:词语切分、句子切分和词性标注.文献[13-14]提出的关联规则挖掘算法可以从评论文本中的每个句子挖掘评价对象.该算法从评论语料里抽取频繁出现的名词组成评价对象集合.之后,通过简单匹配句子里面的词汇和评价对象集合里面的词汇,为每个句子得到该句子描述的评价对象.假如一个句子里面的词汇都没有出现在评价对象集合中,这个句子会被赋予一个特殊的评价对象标签 “others(其他)”.这里设定评价对象的数目是100,其中包括这个特殊评价对象(others)的符号.为了提高词性标注的准确率和获取评价对象集合的质量,本研究删除了包含超过100个词的句子的评论文本.表2给出了预处理后数据集的统计数据.

表2 IMDb和Yelp2014数据集的统计数据
Tab.2 Statistics of IMDb and Yelp2014 datasets数据集按照8:1:1的比例划分为训练集、开发集和测试集,使用准确率A来度量整体情感分类的性能并使用均方根误差RMSE来度量预测的标签与标准答案标签的差异性.
采用文献[11]中训练好的词向量来初始化HUAAN中的词向量,词向量的维度取200.用户和评价对象的编码向量维度均设定为200,并且随机初始化.LSTM隐层参数和记忆单元的维度均设定为200维.训练时使用adadelta算法更新参数,并使用开发集来调整超参数.
2.2 基线系统HUAAN将与下面的基线系统进行比较.
1)Majority是一种启发式的方法.首先统计得到训练集出现最多的标签,然后用这个标签作为所有测试集样本的标签.
2)Trigram+支持向量机(SVM)是一种传统方法.以评论文本的一元语法、二元语法和三元语法作为特征来训练SVM分类器.
3)AvgWordVec+SVM是一种很简单的基于词向量的方法.通过平均评论中所有词汇的词向量得到评论向量,然后将这个评论向量作为特征来训练SVM分类器.
4)HAN[19] 用一个层次化的模型对评论进行建模,并且使用注意力机制来区分对待不同的词汇.该方法仅仅依赖文本信息,并取得了在仅仅考虑文本信息的情况下目前的最好结果.
5)NSC+UPA[11]是目前最好的模型.通过考虑用户信息和产品信息来提高文档级别情感分类的效果.
2.3 模型对比表3给出了HUAAN及基线系统的情感分类结果,这些结果可以分为2组:1)仅仅考虑文本信息的,2)同时考虑文本和用户信息.
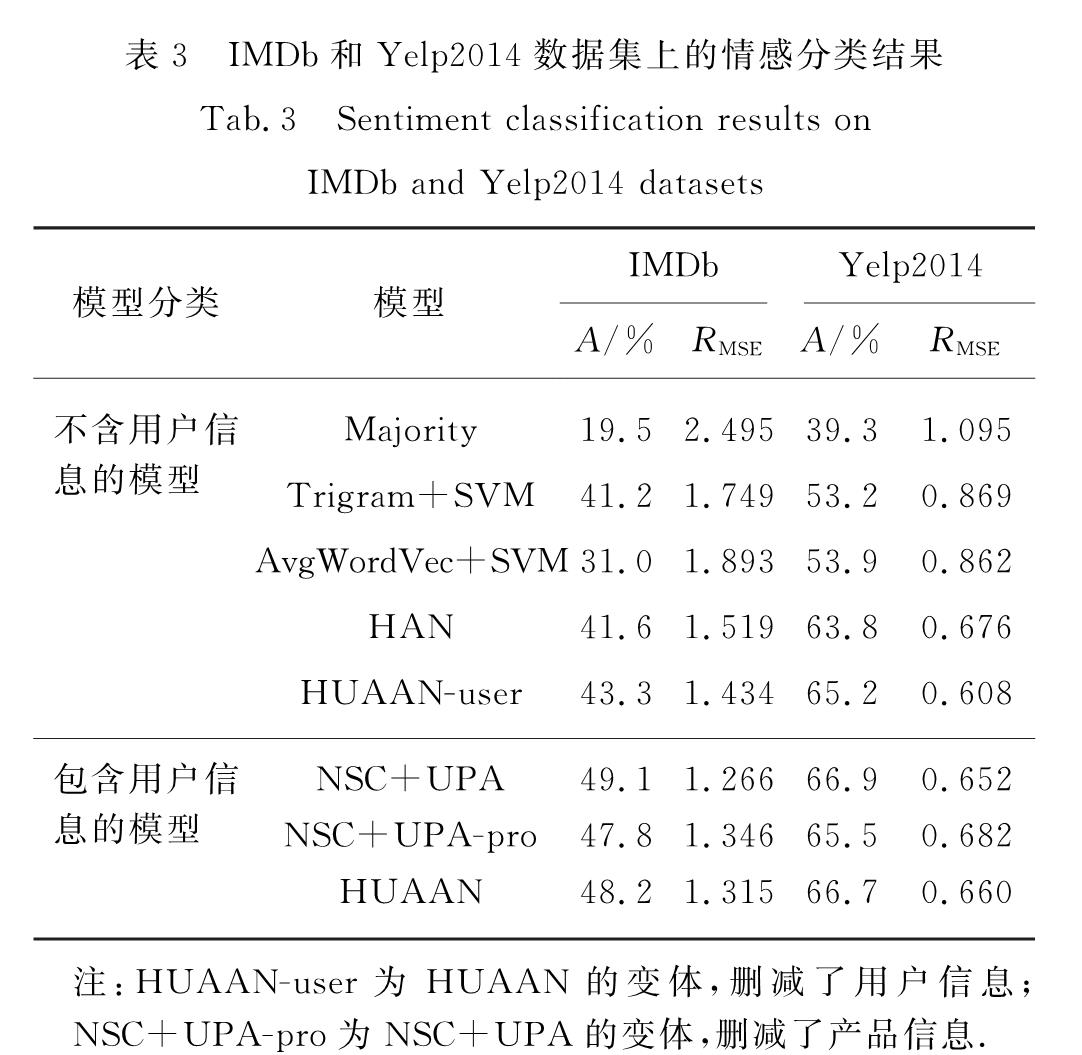
表3 IMDb和Yelp2014数据集上的情感分类结果
Tab.3 Sentiment classification results on IMDb and Yelp2014 datasets第1组的实验结果表明Majority效果非常差,因为它没有包含任何的文本信息.基于一元语法、二元语法和三元语法的Trigram+SVM模型在文档级别情感分类表现较好,远好于基于平均词向量的AvgWordVec SVM模型.HAN通过用一个层次化的模型对文本进行建模,取得了更好的结果.最后,HUAAN-user比HAN、AvgWordVec+SVM和Trigram+SVM在IMDb数据集上的情感分类准确率分别高出1.7,12.3和2.1个百分点,在Yelp2014数据集上分别高出了1.4,11.3和12.0个百分点.
第2组的实验结果表明,用户信息确实对文档的情感分类效果有帮助.当考虑了用户信息之后,HUAAN比HUAAN-user在IMDb和Yelp2014的准确率分别高出4.9和1.5个百分点.与当前最先进系统NSC+UPA相比,HUAAN也取得了接近的实验结果.值得一提的是NSC+UPA不仅考虑了用户信息,还用同样的方式考虑了产品信息,然而HUAAN却只考虑了用户信息.为了公平比较HUAAN和NSC+UPA,本研究测试了NSC+UPA去掉产品信息后的模型NSC+UPA-pro的结果.与NSC+UPA-pro相比,HUAAN在数据集IMDB和Yelp2014上的准确率分别高出了0.4和1.2个百分点.这表明在同等的条件下HUAAN模型要优于NSC+UPA.
2.4 词汇层、句子层和评价对象层的不同注意力模型的作用本研究测试了几种注意力机制模型在HUAAN不同层的作用,当测试某一层时,只改变当前层的注意力机制,其他层的注意力机制与HUAAN相同,结果如表4所示:
1)与AVG相比,词汇层、句子层和评价对象层的ATT模型都能提升情感分类的效果.
2)与ATT相比,UsrATT和AspATT在各层都对情感分类效果有提升,表明本研究提出的这两种机制可以很好地捕捉到用户和评价对象在不同层的特点.
3)HUAAN在词汇层的变体实验结果表明,引入UsrATT会比引入AspATT效果要好.这个现象说明词汇层面用户的差异性会比评价对象的差异性对情感分类的影响更大.当这两者被同时考虑时,模型可以取得最好的结果.
2.5 基于词汇层注意力权重展示的样例分析为了展示HUAAN可以很好地捕捉不同的用户

表4 不同的注意力机制模型的情感分类效果
Tab.4 Sentiment classification results of different attention mechanisms注:AVG为平均池化层注意力机制; ATT是局部语义注意力模型[13]; UsrATT为本研究提出的基于用户的注意力机制; AspATT为本研究提出的基于评价对象的注意力机制; Usr+Asp ATT为将基于用户的注意力机制和基于评价对象的注意力机制融合.HUAAN在词汇层、句子层和评价对象层分别采用的是Usr+Asp ATT,AspATT和UsrAtt.
用词偏好,给出如表5所示(词汇底色越深表示该词汇的注意力权重越大)的例子.这个例子包含的两句话,分别是“The hotel is really good with nothing.”和“The food is very good and the hotel is well located.”.前句由用户A所写,后句由用户B发布.这两句话都含有词汇“good”,但是两句话出现在不同的评论中:第一句话出现在一个评分为2星的评论里而第二句话出现在一个评分为5星的评论里,因此在预测这两篇评论时,词汇“good”的作用是不同的.HAN使用局部注意力机制来获取词汇权重无法区分这两句话中“good”的差异,均赋予了很高的注意力权重; 但是HUAAN基于用户的模型区分对待这个词汇,进而获得更高的准确率.
3 相关工作
情感分类是情感分析[20-21]中的一个很典型的问题.继深度学习方法在计算机视觉、语音识别等领域取得成功之后,越来越多的学者关注如何用这项技术来提高情感分类的效果.它最大的优势就是不依赖人

表5 词汇层注意力权重展示
Tab.5 Visualization of word-level attention工定义特征,自动从文本中抽取有用的特征来做分类.Socher等[6-7,22]构建了一系列的递归神经网络的模型来学习句子的表示,取得了很好的效果.Kim[23]采用卷积神经网络做情感分类也取得了不错的结果.
很多工作[19,24]使用层次化的模型对文档建模,通过得到词汇层和句子层的语义表示得到整个文档的语义表示,这类方法在文档级别情感分类中取得了非常好的效果.尽管如此,这些工作都只关注于文本内容本身而忽视了发布文本的用户,然而这些用户却对确定文本的倾向性有着至关重要的作用.目前已有一些工作[10-12,25-28]将用户信息引入到情感分类中:Tang等[10]在卷积网络的模型中添加用户偏好的矩阵和向量; Chen等[11]将用户表示成一个向量,然后将其融合到一个层次化的模型来考虑用户信息对情感分类的作用; Amplayo等[27]研究了针对冷启动的用户,如何融入用户信息来提升情感分类的效果.尽管这些方法都取得了较好的效果,但是它们对用户信息的考虑还不够充分,仅考虑了用户对不同词汇的偏好,而忽略了用户对不同评价对象的喜好差异.本研究提出的HUAAN模型可以充分考虑用户信息并同时考虑了这两类信息,且在相同条件下优于NSC+UPA系统.
4 结 论
本研究提出了HUAAN模型来对评论文本进行情感分类,该模型用一个层次化的结构对词汇信息、句子信息、评价对象信息和用户信息进行编码,并且引入基于用户的注意力机制来充分考虑词汇层面的用户偏好和评价对象层面的用户偏好.通过在两个公开的数据集中做的实验表明,融入了用户信息和评价对象信息之后,HUAAN能在同等条件下超过NSC+UPA系统的情感分类准确率.
进一步的研究工作将着重从以下两个方面入手:
1)本研究仅使用了最简单的评价对象抽取算法来抽取文本中的评价对象,下一步可以尝试更加复杂的评价对象抽取的方法,对比不同评价对象抽取算法对模型的影响.
2)本研究仅使用了用户本身信息,还可以拓展为用户的属性,如年龄、地域等,下一步可以尝试考虑如何引入这类信息到本研究的模型中,用来更好地提升情感分类的效果.
- [1] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013:430-431.
- [2] PANG B,LEE L,VAITHYANATHAN S.Thumbs up? Sentiment classification using machine learning techniques[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Philadelphia:ACL,2002:79-86.
- [3] XIA R,ZONG C Q,LI S S.Ensemble of feature sets and classification algorithms for sentiment classification[J].Information Sciences,2011,181(6):1138-1152.
- [4] WANG S D,MANNING C D.Baselines and bigrams:simple,good sentiment and topic classification[C]∥Proceedings of the Annual Meeting of the Association for Computational Linguistics.Jeju Island:ACL,2012:90-94.
- [5] LI S S,XUE Y X,WANG Z Q,et al.Active learning for cross-domain sentiment classification[C]∥Proceedings of the International Joint Conference on Artificial Intelligence.Washington DC:IEEE,2013:2127-2133.
- [6] SOCHER R,PENNINGTON J,HUANG E,et al.Semi-supervised recursive autoencoders for predicting sentiment distributions[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Scotland:ACL,2011:151-161.
- [7] SOCHER R,PERELYGIN A,WU J Y,et al.Recursive deep models for semantic compositionality over a sentiment treebank[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Seattle:ACL,2013:1631-1642.
- [8] TANG D Y,WEI F R,YANG N,et al.Learning sentiment-specific word embedding for twitter sentiment classification[C]∥Proceedings the Annual Meeting of the Association for Computational Linguistics.Maryland:ACL,2014:1555-1565.
- [9] TANG D Y,QIN B,LIU T.Document modeling with gated recurrent neural network for sentiment classification[C]∥Proceedings of the international conference on Empirical Methods in Natural Language Processing.Lisbon:ACL,2015:1422-1432.
- [10] TANG D Y,QIN B,LIU T.Learning semantic representations of users and products for document level sentiment classification[C]∥Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing.Beijing:ACL,2015:1014-1023.
- [11] CHEN H M,SUN M S,TU C C,et al.Neural sentiment classification with user and product attention[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Texas:ACL,2016:1650-1659.
- [12] DOU Z Y.Capturing user and product information for document level sentiment analysis with deep memory network[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Copenhagen:ACL,2017:532-537.
- [13] HU M Q,LIU B.Mining and summarizing customer reviews[C]∥Proceedings of the International Conference on Knowledge Discovery and Data Mining.Seattle:ACM,2004:168-177.
- [14] HU M Q,LIU B.Mining opinion features in customer reviews[C]∥Proceedings of the International Joint Conference on Artificial Intelligence.California:IEEE,2004:755-760.
- [15] HOCHREITER S,SCHMIHUBER J.Long short-term memory[J].Neural Computation,1997,9(8):1735-1780.
- [16] TANG D Y,QIN B,LIU T.Aspect level sentiment classification with deep memory network[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Texas:ACL,2016:214-224.
- [17] WANG Y Q,HUANG M L,ZHU X Y,et al.Attention-based LSTM for aspect-level sentiment classification[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Texas:ACL,2016:606-615.
- [18] MANNING C D,SURDEANU M,BAUER J,et al.The stanford corenlp natural language processing toolkit[C]∥Proceedings of the Annual Meeting of the Association for Computational Linguistics:System Demonstrations.Maryland:ACL,2014:55-60.
- [19] YANG Z C,YANG D Y,DYER C,et al.Hierarchical attention networks for document classification[C]∥Proceedings of Annual Conference of the North American Chapter of the Association for Computational Linguistics.California:ACL,2016:1480-1489.
- [20] PANG B,LEE L.Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1/2):1-135.
- [21] LIU B.Sentiment analysis and opinion mining[J].Synthesis Lectures on Human Language Technologies,2012,5(1):1-167.
- [22] SOCHER R,HUVAL B,MANNING C D,et al.Semantic compositionality through recursive matrix-vector spaces[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Jeju Island:ACL,2012:1201-1211.
- [23] KIM Y.Convolutional neural networks for sentence classification[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Doha:ACL,2014:1746-1751.
- [24] BHATIA P,JI Y F,EISENSTEIN J.Better document-level sentiment analysis from RST discourse parsing[C]∥Proceedings of the International Conference on Empirical Methods in Natural Language Processing.Lisbon:ACL,2015:2212-2218.
- [25] LI J J,YANG H T,ZONG C Q.Sentiment classification of social media text considering user attributes[C]∥Proceedings of the Conference on Natural Language Processing and Chinese Computing.Kunming:CCF,2016:583-594.
- [26] GUI L,ZHOU Y,XU R F,et al.Learning representations from heterogeneous network for sentiment classification of product reviews[J].Knowledge-Based Systems,2017,124:34-45.
- [27] AMPLAYO R K,KIM J,SUNG S,et al.Cold-start aware user and product attention for sentiment classification[C]∥Proceedings of the Annual Meeting of the Association for Computational Linguistics.Melbourne:ACL,2018:2535-2544.
- [28] WU Z,DAI X Y,YIN C Y,et al.Improving review representations with user attention and product attention for sentiment classification[C]∥Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence.Louisiana:IEEE,2018:5989-5996.
