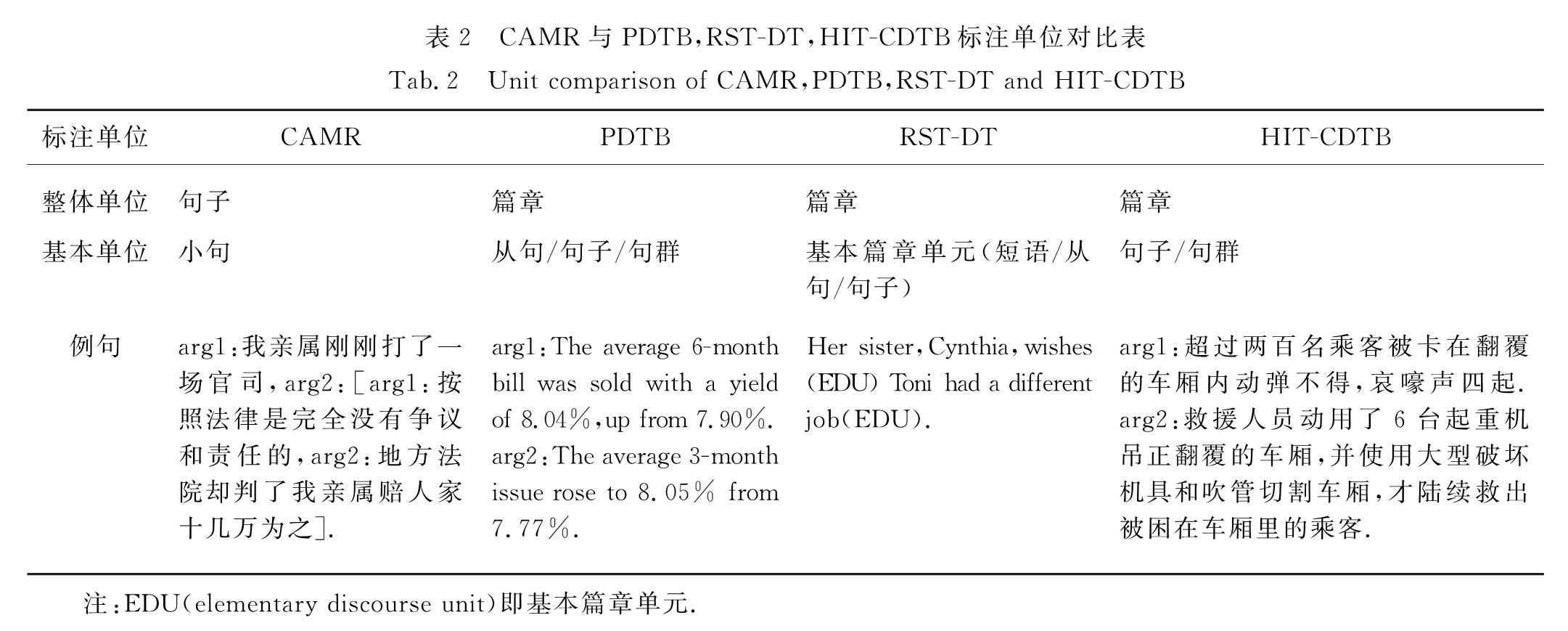
3.3.1 显式关系识别
1)关系词识别
复句中的显式关系指的是包含关系词的复句所表示的逻辑语义关系.英语中的关系词大部分是非歧义的[27],因此只要识别出关系词,基本就可以推断出其表示的语义关系.对于有歧义的关系词,Pitler等[28]使用词汇和句法特征来判断其是否为篇章关系词,准确率可以达到96.26%,F值达94.19%,Lin等[24]在此基础上抽取了词性、上下文等特征来构建其关系词分类器,最终准确率达到97.25%,F值达到95.36%.与英语相比,汉语篇章中关系词的语法性质和词性分布更加复杂.李艳翠等[29]指出,汉语中的关系词不限于传统连词,还有介词、副词等诸多语法类型.胡金柱等[30]建立了一个复句关系词库,将复句中的关系词分为3类,第1类为语义单一型典型关系词,如“因为、所以”等,这些词能够固定地表示分句间的某种语义关系; 第2类为语义多样型非典型关系词,如“就、才、也”等副词,可以兼表几种语义关系; 第3类为语义单一型非典型关系词,如“别管、怪不得、谁知道”等形式上处于实义短语与关系词的共存状态.因此,汉语中关系词消歧任务比英语更加复杂和艰巨.李艳翠等[31]利用词的词汇、句法、位置特征使用决策树分类器在清华树库上进行是否为关系词的识别,在不带功能标记的词上达到了92.1%的准确率,但该研究只识别单个关系词,而汉语中关系词常常是成对成组出现的.针对这一问题,杨进才等[32]使用贝叶斯模型对关系词的特征集合进行训练和测试,将基于统计过程的结果转换为规则,在汉语复句语料库上取得了95.4%的准确率.该研究实验数据较小,只验证了15组关系词在1 000句上的准确率.总的来说,目前汉语关系词识别效果较好,但研究多是着眼于典型关系词,对于非典型关系词的识别较少.
2)显式语义关系判定
在连接关系识别领域,Pitler等[28]仅使用关系词特征,在PDTB分类体系下将篇章语义分成因果、比较、时序和扩展,取得了93.9%的准确率.Lin等[24]在特征中加入了关系词,上下文等特征,在自动句法树上取得了86%的准确率.汉语中由于关系词歧义情况较为复杂,目前取得的效果较英文稍差.李艳翠等[31]在PDTB分类体系下使用最大熵分类器对连接词语义进行分类,4分类的准确率仅有78.9%,F值也仅有69.3%.张牧宇等[33]使用极大似然估计法,利用关系词特征进行关系分类,在因果、条件、比较关系上都取得比较好的效果,准确率均超过95%,但在并列关系上效果较差,准确率只有63.6%.以上研究都是在4大类分类上实验,没有将语义关系进一步细分为小类.杨进才等[34]对于只有部分分句含有关系词的非充盈态有标复句计算分句核心词的语义相关度,作为判断复句语义关系的依据,准确率达到了89%,但没给出各类别的准确率.可以看到,汉语显式语义关系识别仍有一定的提高空间.
3.3.2 隐式关系识别
显式复句关系词可以作为判定语义关系的强力标志,而不含关系词的隐式关系判定则给复句语义关系识别带来巨大挑战,也是目前篇章关系研究领域的热点.
1)基于特征的方法
Marcu等[35]抽取论元的词对信息,利用互联网抽取大量词对信息实例,并将其中的关系词移除构建一个隐式关系语料库,然后使用贝叶斯分类器对隐性语义关系进行识别.Pitler等[36]则将词的情感特征、动词类别、动词短语长度、情态、上下文和词汇特征等用于篇章关系识别,在PDTB 4类语义关系分类任务上,各类特征的使用对于结果的F值提升都有明显作用.Lin等[37]使用前后论元信息、词对信息、论元内部成分和依存句法信息作为特征,利用最大熵分类器,在PDTB第2层11类语义关系上进行识别,取得了40%的准确率,比baseline提高了14.1%.Louis等[38]尝试将文本中的指代信息以及指代词的句法结构和特征用于隐性语义关系的识别,效果虽较baseline有提升,但比传统利用词法特征的方法仍然相差较多.Rutherford 等[39-40]针对有些显性关系移除关系词后意义改变不能用于构造隐性关系的问题,通过计算关系词的省略率来选出合格的关系词论元对,进而扩大训练数据集,提升了识别效果,在PDTB 4分类上准确率达到40.5%.车婷婷等[41]挖掘词级和短语级的功能连接词,建立功能连接词的概念模型与篇章关系的映射体系,实现隐式篇章语义关系的推理,虽然结果取得了不错的效果,准确率达53.84%,但是只比全部标为最大类别扩展关系的baseline准确率高0.1%,这也说明目前隐式篇章关系识别的难度.
在汉语隐式篇章关系研究方面,张牧宇等[33]基于有指导方法的关系识别模型,利用核心动词、极性特征、依存句法特征、句首词汇特征等,对因果、比较、扩展、并列4类关系进行分类,结果只有扩展关系的识别效果不错,F值达到72.3%,其他3类效果不佳,比较关系的F值最低,只有16.2%.孙静等[42]利用上下文特征、词汇特征、依存树特征,采用最大熵分类法对因果、并列、转折、解说4大类关系进行识别,总准确率为62.15%,但除了并列类效果很好之外,其他3类效果都不佳,特别是转折类完全没有识别出来.李国臣等[43]利用汉语框架语义网识别11种篇章语义关系,结果显示只有属于关系识别效果较好,准确率超过70%,其他关系效果都不尽理想,均低于40%.
可以看到,无论是在英语还是汉语中,传统基于特征的方法准确率都不高,扩展或并列类准确率较高的原因是自然语言中这类语义关系本身占比就较大,若剔除这个因素,准确率可能还要更低.想要提高性能,必须表征句子更深层的语义关系.
2)基于神经网络的方法
随着近些年神经网络研究的兴起,学者们发现相比于传统方法使用浅层特征易于丢失文本序列、结构等重要信息,使用词嵌入(word embedding)对句子进行表示更能获取句子深层的语义信息.在机器翻译、阅读理解等领域取得卓越效果之后,一些学者也开始将神经网络用于隐式篇章关系的识别.Ji等[44]最早将神经网络技术应用于篇章隐式关系,他们用循环神经网络(recurrent neural network,RNN)对句子的论元及实体进行编码,在PDTB 4类语义分类任务中将准确率提升到了43.56%.Zhang等[45]则是使用了只有一个隐藏层的浅层卷积神经网络(SCNN)在PDTB上进行隐式关系识别,并在4个关系分类任务中的3个(因果、扩展、时序)上取得了优于基于SVM方法的结果.Liu等[46]使用双向长短期记忆网络(Bi-LSTM)将隐式关系中的论元编码,同时模仿人类重复阅读习惯,引入了多重注意力(multi-attention)机制,对隐式篇章关系进行识别,在PDTB 4类关系的分类中准确率和F值分别为57.57%和44.95%.Li等[47]对论元、句子和段落都进行分布式语义表示并将之组合,使得最终每个论元的embedding中都含有词语、句子和段落信息,在PDTB第1层4类分类任务上F值分别为41.91%,54.72%,71.54%,34.78%,同时在第2层分类任务上取得44.75%的准确率.另外,他们还将该模型用于宾州汉语树库篇章隐式关系的识别,准确率达到82.56%,与全部标记为最大类别扩展关系的baseline相比,提高了11.63%.Qin等[48]提出了一个挖掘关系特征的对抗网络来进行隐式关系识别,在4类关系分类上取得46.23%的准确率.Geng等[49]认为句子结构信息对隐式关系的判定有十分重要的作用,因此应该将句法树信息融入论元的语义编码,他们在将关系论元使用Bi-LSTM编码后,将句子的句法树转换成一个二叉树,然后将子节点的信息经过转换后计入父节点信息,最后取得了62.4%的准确率和44.2%的F值.Wang等[50]在使用句法树信息之外,也使用了句法树每个节点标签的embedding,分别在第1层和第2层语义关系分类中取得了59.85%和45.21%的准确率.Dai等[51]借鉴序列化标注思想,认为句间关系要放在整个篇章中来考察,因此建立了一个篇章级神经网络模型,对显式关系和隐式关系训练不同的分类器,同时在模型最后一层加入了条件随机场(CRF)层,最终取得了4分类任务中隐式关系58.2% 的准确率和显式关系94.46%的准确率.神经网络的应用提高了隐式篇章关系的识别性能,但仍仅有60%左右的准确率,F值也不到50%,仍然无法满足实际应用的需求.
3.4 结构层次树的生成
目前,篇章层次树生成的研究大多基于RST-DT展开.Soricut等[22]使用概率模型构建句级篇章结构树,并在18类篇章关系标注上取得49.0%的F值.LeThanh等[52]分别在句子层面和篇章层面进行篇章结构树的构建,在句子层面使用句法信息和短语信息切分EDU,以生成句子的篇章结构树,并取得了66.2%的F值.在汉语的篇章关系构建中,张益民等[53]利用主位模式等多个语言学特征,使用向量空间模型对篇章结构进行自动分析.涂眉等[54]先使用序列化标注方法对篇章语义单元进行切分,然后使用最大熵模型对篇章结构进行推导,在清华汉语树库上的实验结果为,当篇章语义结构树高度不超过6层时,篇章语义关系标注的F值为63%.可以看到,过去对结构层次树生成的评测主要仍是针对层次生成后的语义关系标注,对结构层次本身的正确与否并无考察.对于含有多个分句的复句或篇章来说,句子之间的层次关系直接反映了它们之间的逻辑语义关系,因此对层次结构树本身的考察是今后研究亟待解决的关键问题之一.