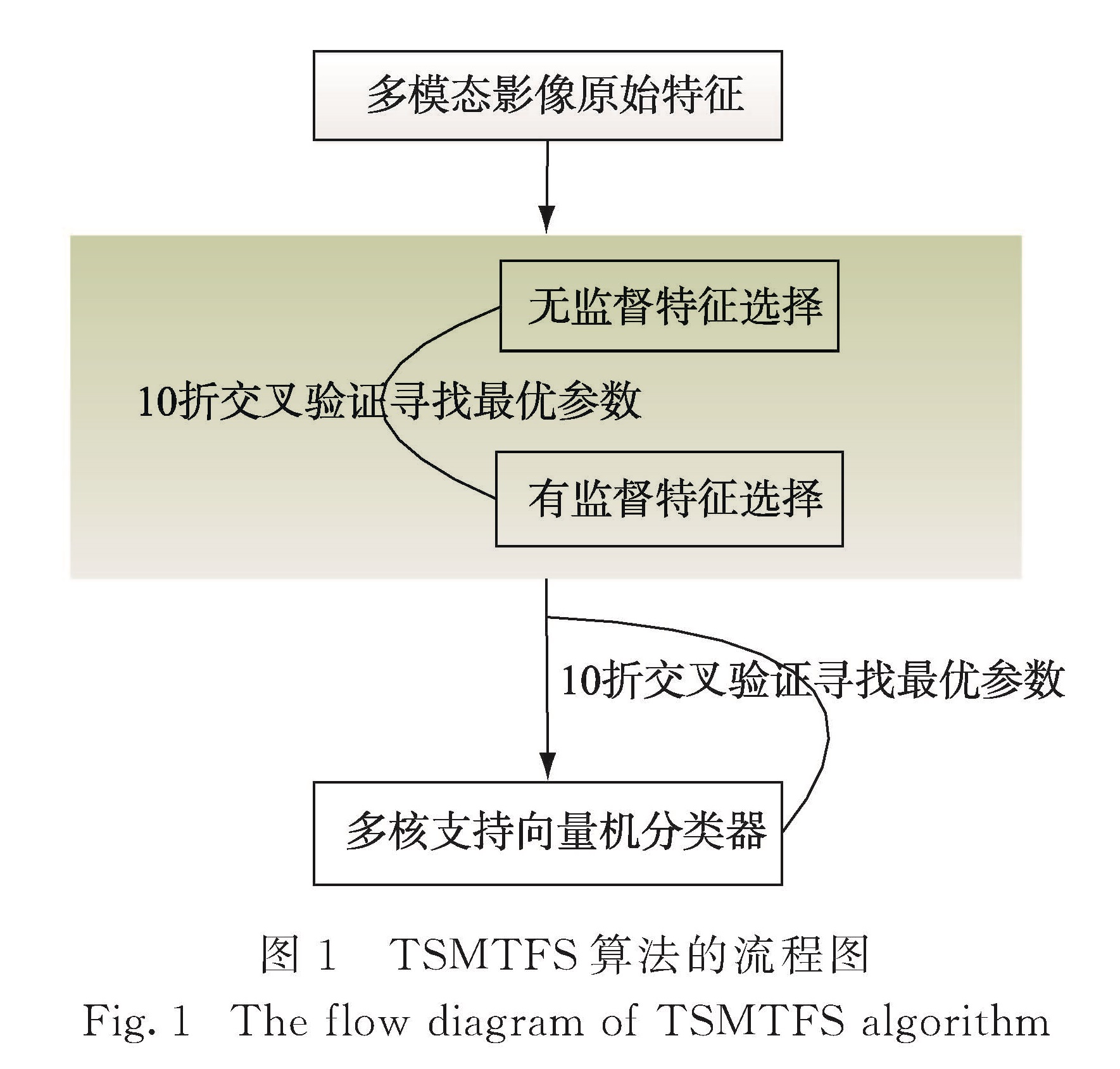
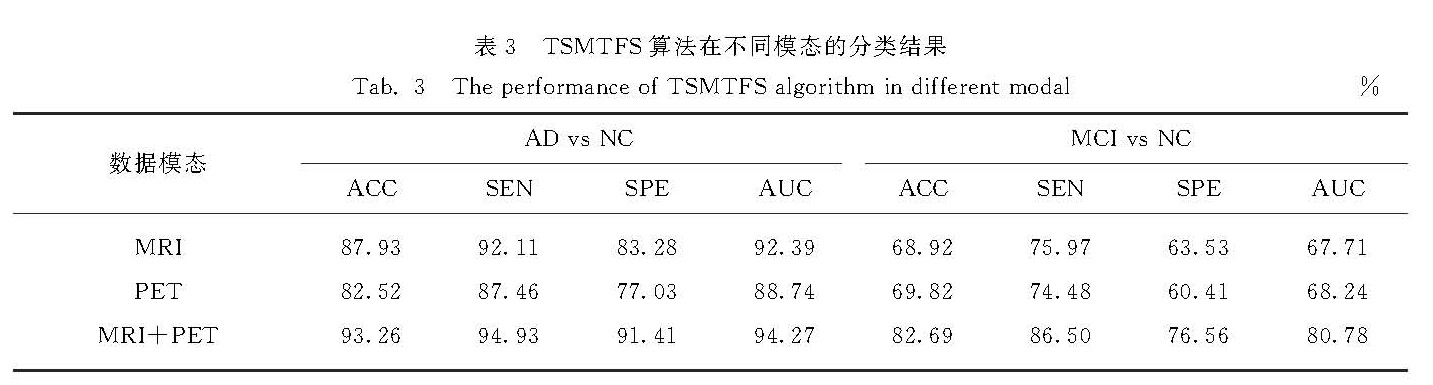
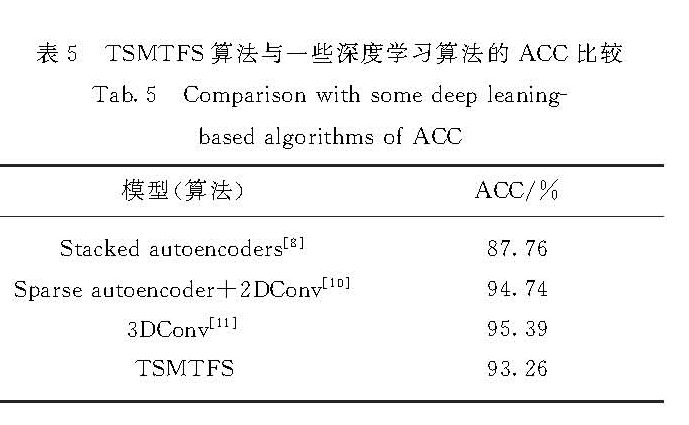
阿尔茨海默病(Alzheimer's disease,AD)具有数据量少、多模态以及高维度等特点.为了对AD进行有效的预测,首先提出一个基于类内方差最小化的多任务特征选择(minimum intra-class variance-based multitask feature selection,MIVMTFS)算法,然后结合基于有效距离的拉普拉斯分数特征选择(effective distance-based laplacian score feature selection,EDLSFS)算法和MIVMTFS算法,提出一种二阶段多任务特征选择(two-stage multi-task feature selection,TSMTFS)算法.TSMTFS算法先利用EDLSFS算法在保持特征局部结构的情况下对原始样本特征进行无监督预降维,再利用MIVMTFS算法对降维后的特征进行有监督地再降维,最终获得一个精简特征子集.实验部分主要包括AD的2个二分类任务,并分别对单模态数据和多模态数据进行实验.实验结果验证了TSMTFS算法在AD领域能够缓解单模态特征选择的信息不够充分、样本量少以及特征维度高等不足.
Alzheimer's disease(AD)is characterized with few samples,multi modes,and high dimensionality.In this article,we first propose a minimum intra-class variance-based multitask feature selection(MIVMTFS)algorithm.Then,we propose a multi-task feature selection method of two-stage strategy based on combining effective distance-based Laplacian score feature selection(EDLSFS)algorithm and MIVMTFS algorithm.The former is used to pre-reduce feature dimension of label data,keeping the local structure of the original sample feature.The latter has been used to reduce the dimensionality of the reduced feature further.Finally,we can obtain a simplified feature subset.The experimental part of this paper includes two binary classification tasks,and we have also used the single modal and multi modal data to test algorithms' performances.Experimental results show that TSMTFS algorithm can alleviate these shortcomings including information deficiency,few samples and feature of high-dimensional during the feature selection of single modal in the field of AD.