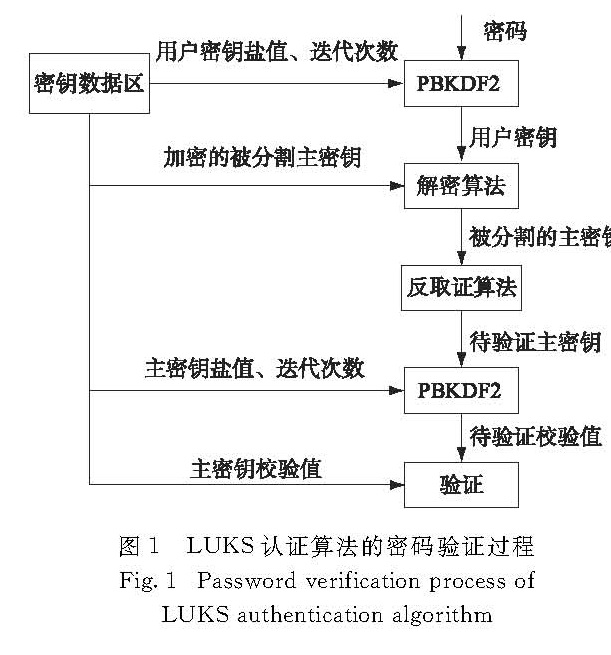
2.1 整体架构设计
本设计的整体架构分为两个部分,即主控处理器部分和LUKS硬件协处理器部分,分别基于FPGA的硬件处理器(PS)和可编程逻辑(PL)资源实现.两者之间采用先进可扩展接口(AXI)进行通信,主控处理器通过AXI与片内BRAM和LUKS电路模块相连,输入数据并获得LUKS协处理器的运算结果.在BRAM中,储存有主密钥的相关数据,作为AES解密模块的输入.其他LUKS模块所需要的数据可以从AXI相关的寄存器中获取.
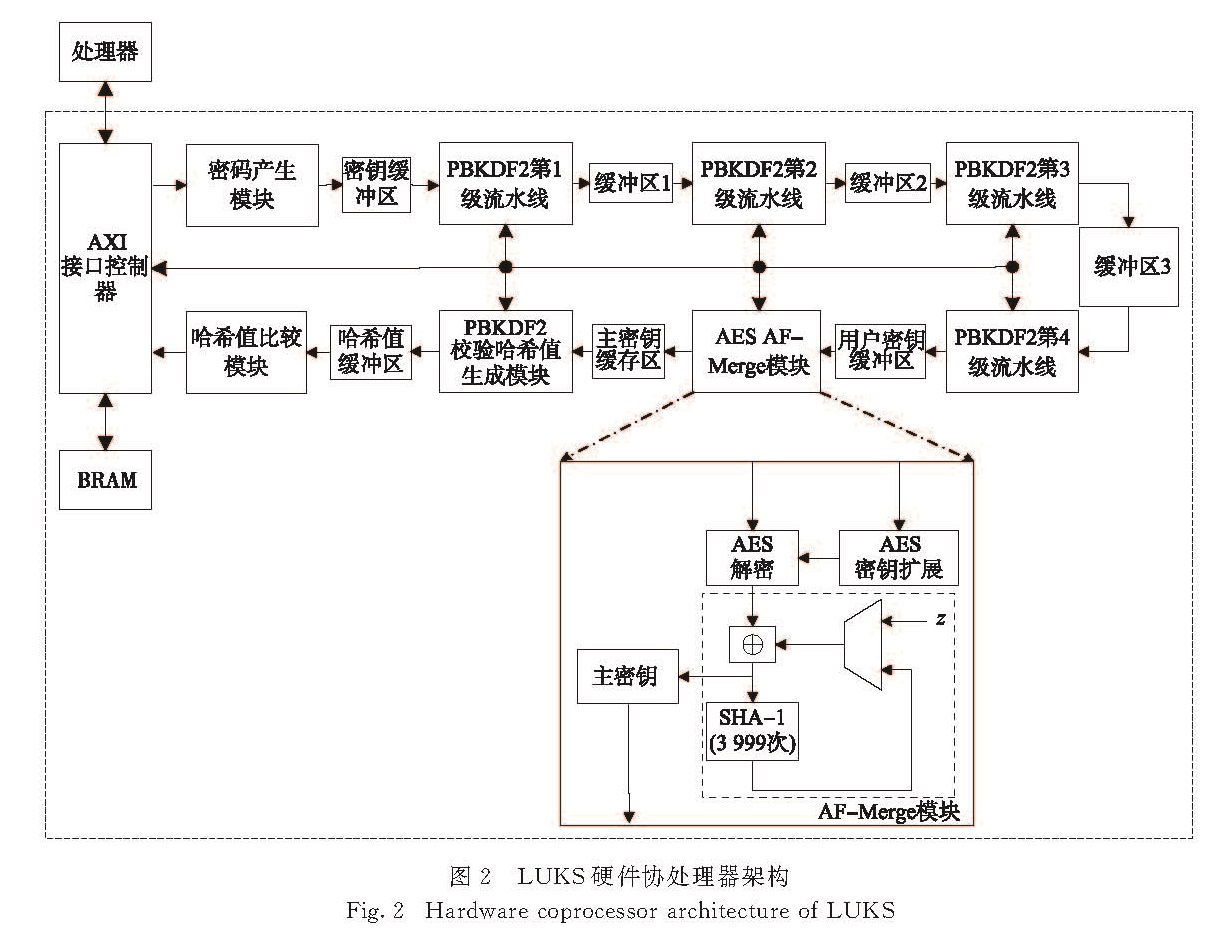
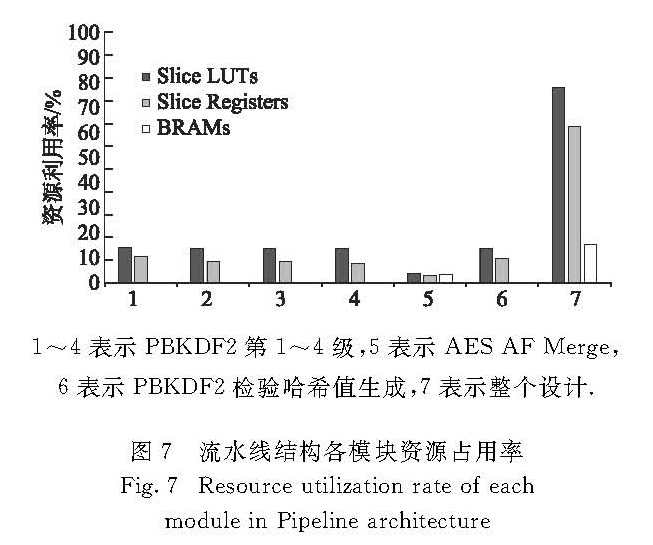
以时延(单位为时钟周期clock,1 clock=1/(f),f为频率)为标准,合理分配各模块的资源是提高吞吐率的有效手段.在LUKS认证算法中,通常PBKDF2的迭代次数为163 682,校验哈希值生成的迭代次数为41 125[9],故生成用户密钥所需的迭代次数是生成校验哈希值的迭代次数的4倍,因此本设计将生成用户密钥模块的数量设计为校验哈希值生成模块数量的4倍,以平衡各级之间的运算时延,进而实现流水线结构较高的工作频率.这个工作流的前4个PBKDF2模块以流水线的工作模式生成用户密钥,第5个PBKDF2模块生成待校验哈希值.单个PBKDF2模块是8级流水线,一次迭代所需时间为82个clock.当系统工作时,密码生成器会给具有8级流水线的第一个PBKDF2模块8个密码,然后前4个PBKDF2模块每个都会完成约1/4的迭代次数.AES AF-Merge模块的作用是获取主密钥.其中AES密钥扩展模块首先将前面PBKDF2所派生的用户密钥进行扩展,并作为AES的轮密钥.AES解密模块再解密主密钥,它的时延为10个clock.最后AF-Merge将AES解密的结果作为输入,进行迭代运算,需要41个clock.故AES AF-Merge模块前面输入的8个密码,需分别经过4 000次AES解密和3 999次SHA-1操作,即需8×(4 000×10+3 999×41)=1 631 672个clock便可以获得主密钥.最终,主密钥的哈希值将在哈希值比较模块中与加密镜像中储存的哈希值进行比较,需1个clock.各模块的时延如表1所示.
表1 流水线结构LUKS中IP核各模块的时延
Tab.1 Amount of delayed for each module of IP core in LUKS pipeline architecture
图2 LUKS硬件协处理器架构
Fig.2 Hardware coprocessor architecture of LUKS
基于以上各模块运算时钟数的分析,本研究设计了如图2所示的硬件协处理器架构,包括1个密码产生模块、5个PBKDF2模块、1个AES AF-Merge模块、1个主密钥校验哈希值比较模块和1个顶层AXI控制模块,模块之间通过缓存进行连接.接到主控处理器给出的控制指令后,开始认证算法的密钥验证过程:1)由密码产生模块生成用户密钥并输入到密钥缓冲区; 2)第1~4级流水线的PBKDF2模块从前一级缓冲区中取得输入并将处理后的数据输入到后一级的缓冲区; 3)AES AF-Merge模块用前面生成的用户密钥去解密和重新组合保存在BRAM中被分割加密的主密钥数据,恢复出主密钥并将其存入主密钥缓冲区中; 4)PBKDF2模块利用输入的主密钥生成校验哈希值并存入哈希值缓冲区; 5)哈希值比较模块对比哈希值缓冲区中待校验哈希值与输入的主密钥校验哈希值,两者相等则向控制模块返回认证通过的信号,不相等则继续密码认证过程.
2.2 SHA-1流水线设计与实现
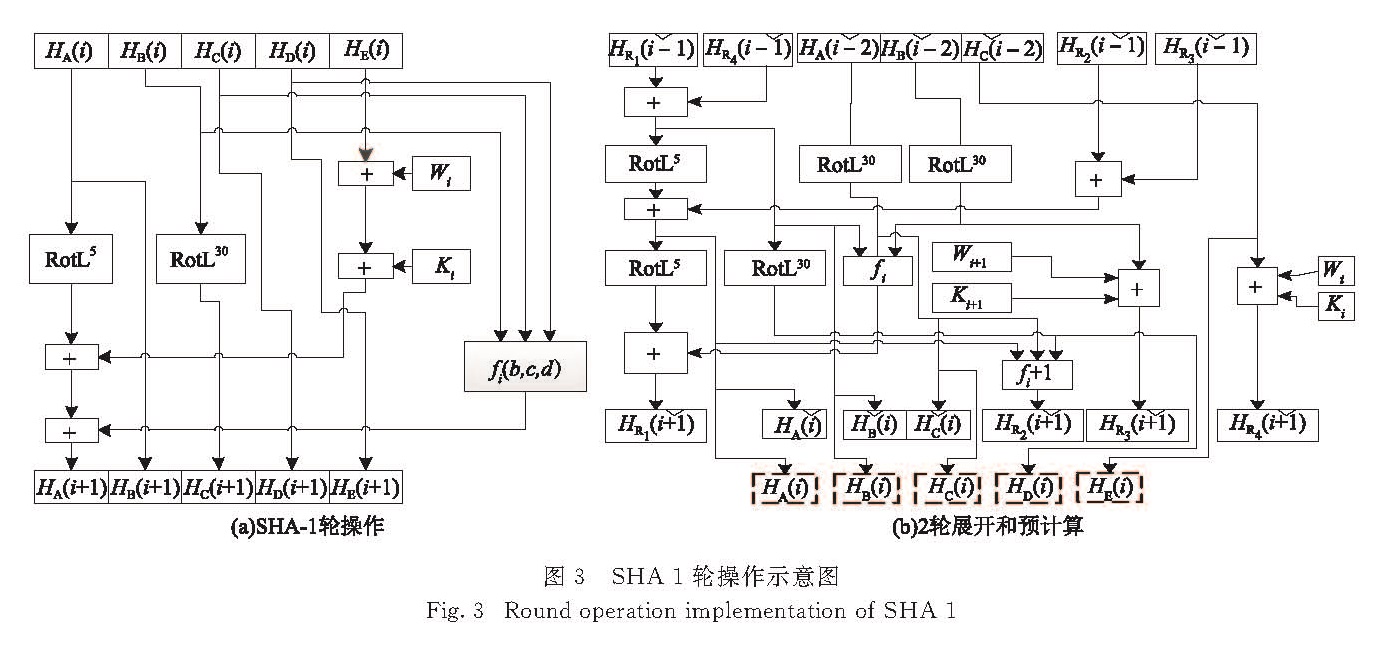
SHA-1算法以512 bit为单位进行处理,并输出长度为160 bit的散列值.计算过程中,用寄存器A、B、C、D、E分别存储一轮运算的中间结果,即5个状态变量HA、HB、HC、HD、HE.第1组分组数据为SHA-1算法规定的初始常量值H0~H5,在其余分组计算中,HA~HE为上一分组计算出的摘要值.每个状态变量的大小为32 bit,以容纳160 bit的数据[10].图3(a)给出了SHA-1其中一轮操作的示意图.图中:Ki是常量,fi是非线性函数,具体的取值根据80轮中的轮数i有所不同; Wi为由输入数据分组计算所得的变量[10],RotLx表示将数据循环左移x位.
如果使用最基础的SHA-1硬件,一个clock使用SHA-1的1轮运算,那么执行整个SHA-1算法就需要80个clock,这样的设计性能不佳.因此,本文中对SHA-1的运算进行组合,使用了2轮展开,将80轮运算的每2轮运算合并在一起变为1轮运算,新的1轮运算能够在一个clock内完成[11].同时还采用了预计算的手段,提前计算出下1轮所要用到的值,并写入R1~R4这4个寄存器中,等待下1轮使用.由于每轮的中间运算结果HA(i),HB(i),HC(i),HD(i),HE(i),可以由HR1(i-1),HR2(i-1),HR3(i-1),HR4(i-1),HA(i-1),HB(i-1)和HC(i-1)得出,所以在一轮计算的过程中,中间值HD(i)和HE(i)无需用寄存器存储,只在最后一轮才需要引出,因此在中间运算电路实现时,将寄存器D和E移除,以进一步节省资源,如图3(b)所示.在首轮中对R1,R2,R3,R4这4个寄存器初始化公式如下.
图3 SHA-1轮操作示意图
Fig.3 Round operation implementation of SHA-1
图4 4级流水线SHA-1
Fig.4 Four-stage pipeline SHA-1
{HR1(0)=f0(HB,HC,HD)+RotL5(HA)
HR2(0)=f1(HA,RotL30(HB),HC),
HR3(0)=W1+K1+HD,
HR4(0)=W0+K0+HE.(2)
其中,K0和K1分别为SHA-1中的常量.即便如此,SHA-1的1轮操作也需要花费大量的时间.因此将SHA-1的模块设计为4级流水线结构,每级流水线完成20轮的计算,如图4所示.SHA-1的4个核分别处理4级流水线的4个阶段.因为第一轮需要预计算,因此第一个核需要经过11个clock才能够计算出结果,至于其他核,则分别只需要10个clock.每2个核间的寄存器用于存放前一个核的输出(即10轮运算结束后的状态变量值),而这些值将作为下一个核的状态变量输入.在最后一个核中,还需要将运算结果与前一分组数据块的摘要值HA、HB、HC、HD、HE相加,以得到最后的摘要值.
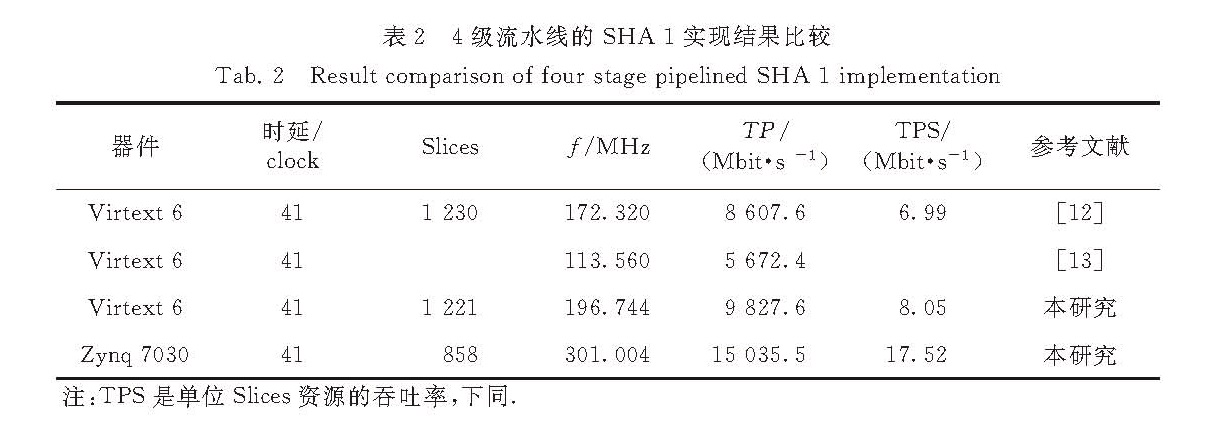
表2列出了本研究与其他文献数据的吞吐率对比,吞吐率TP的计算公式如下:
TP=(B×f×P)/L,(3)
其中,P代表流水线的级数,B表示进入一级流水线的数据块的长度,f表示系统所能达到的最大工作频率,L表示一个数据块从输入到计算完毕总共需要经过的时延.对比文献[12]和[13],本研究的设计有着较大的工作频率、吞吐率和TPS,并且所使用的资源较少.由表2可知,采用基于28 nm工艺的Zynq系列7030 FPGA可以实现比基于40 nm工艺的Virtex 6更高的吞吐率和单位资源吞吐率.本研究设计的工作频率达到了301 MHz,TPS达到了17.52 Mbit/s.
2.3 流水线PBKDF2设计与实现
本研究的流水线PBKDF2的导出密钥值
DK=PBKDF2(PRF,P,salt,iteration,dklen).(4)
表2 4级流水线的SHA-1实现结果比较
Tab.2 Result comparison of four-stage pipelined SHA-1 implementation
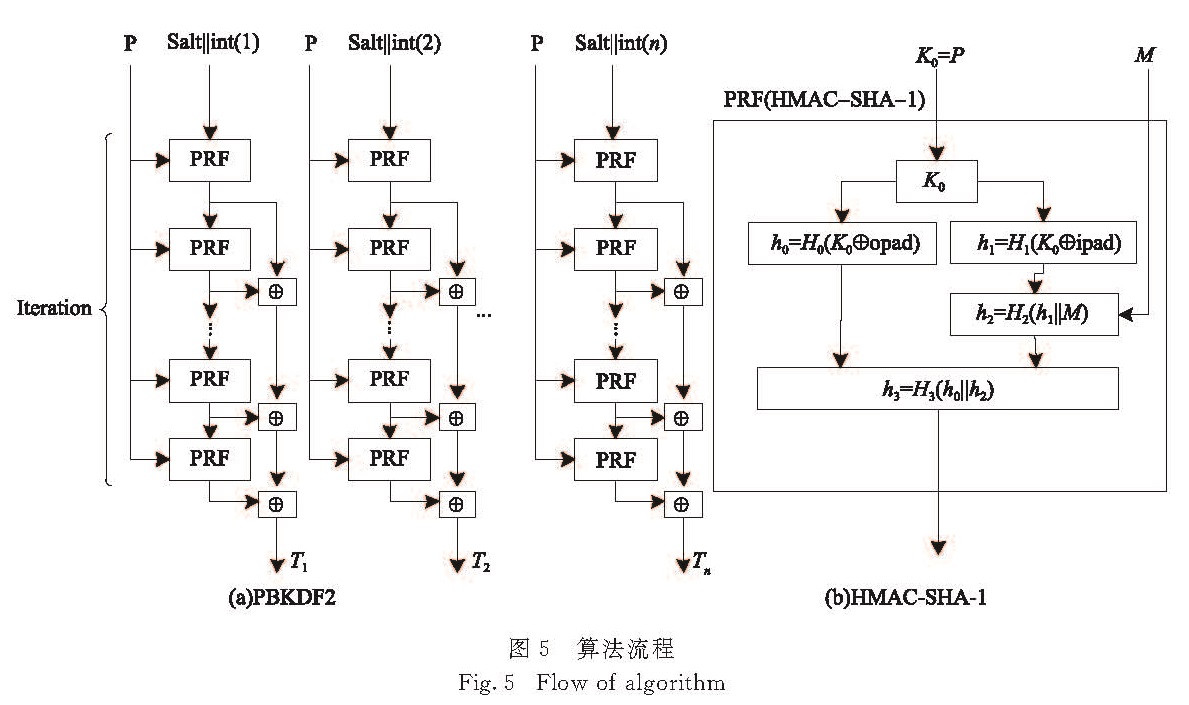
图5 算法流程
Fig.5 Flow of algorithm
其中:PRF表示伪随机函数,本研究选用HMAC-SHA-1; P代表密码; salt是随机生成的盐值,长度为32 bit; iteration表示伪随机函数循环的次数; dklen是导出密钥DK的长度.导出密钥被分为多个块计算,每一块的结果值Tn由PRF函数经过循环迭代计算得出,最后得到的DK由T1…Tn连接而成.
PBKDF2及其HMAC的底层函数框图如图5所示,图中ipad和opad表示两个固定常量,int(n)表示整数n的4字节十六进制数.图5(b)给出了HMAC-SHA-1函数所进行的具体计算步骤,其中的H函数表示SHA-1运算,K0与图5(a)中的P相对应,M则表示图5(a)中的Salt‖int(n)(第n次迭代)或者是上一个PRF函数的输出.HMAC函数中的摘要h0和h1会分别被计算iteration次,考虑到HMAC函数的输入不变,每次h0和h1的计算结果均不变,故只需计算一次h0和h1,并存于寄存器中,即可将PBKDF2中SHA-1的执行次数从4×iteration次下降到2+2×iteration次.
考虑到在LUKS认证算法中需要大量的PBKDF2算法迭代,在此采用流水线架构来实现[14],其架构如图6所示.每个PBKDF2中包含2个SHA-1的模块,而每个SHA-1模块采用4级流水线架构,所以整个PBKDF2-HMAC-SHA-1采用8级流水线的架构,需要82个clock完成一次迭代.其中寄存器1~8存放8个不同的h1值,而寄存器9~16存放8个不同的h0值.HMAC摘要寄存器用于累计每次HMAC-SHA-1函数的输出摘要h3,经iteration次迭代后,该寄存器内的值即为PBKDF2函数的输出密钥.
图6 PBKDF2-HMAC-SHA-1架构
Fig.6 PBKDF2-HMAC-SHA-1 architecture
表3 PBKDF2占用资源及其性能对比
Tab.3 Resource utilization and performance in PBKDF2
将本研究流水线架构实现的和文献[15]中恢复WiFi保护访问(WPA)/WPA2密钥的PBKDF2-HMAC-SHA-1性能进行比较,如表3所示.本研究的8级流水线PBKDF架构仅使用3 800个Slice资源,而文献[15]的20级流水线结构使用了6 381个Slice资源.并且本研究的PBKDF2构架完成8级流水只需88个clock,而文献[15]完成20级流水需要384个clock,可见本研究的构架在完成每级流水平均所需的clock数上占优势.在相同时钟频率的条件下,本研究的吞吐率高达6 982 Mbit/s,而文献[15]的吞吐率为4 680 Mbit/s,可见本研究的8级流水线架构比20级流水架构的吞吐率还要高出许多.从资源利用率的角度看,本研究的TPS参数为1.84 Mbit/s,而文献[15]中仅为0.74 Mbit/s.
2.4 AES-128的设计与实现
由于SHA-1和PBKDF2算法实现中采用流水线结构,占用了较多的LUT资源,因此在实现AES算法时,采用ST-box映射表的架构,并利用FPGA片内BRAM资源来实现.通过对AES轮运算(前9轮)的变换,可以得出以下公式:
ej=T-10[a0,j]T-11[a1,j+1]
T-12[a2,j+2]T-13[a3,j+3]kj,(5)
其中,T-1i对应的是逆T-box映射表,ai,j表示状态矩阵中第i行与j列的字节数据,kj为每一轮的轮密钥,ej为每轮运算后新状态矩阵的列.经过这样的变换后,可使AES中大部分关键的变换通过简单的查表来实现,减少LUT资源的占用.最后一轮由于没有逆列混合操作,因此需要逆S-box.本研究将逆S-box和逆T-box都存储在BRAM中,每个BRAM中存放一对.
根据式(5),本设计将AES-128解密算法的一轮操作分为3个部分:前端行移位部分、中部ST-box表部分和后端轮密钥加密部分.AES-128解密算法的输入为16 B的数据,分别对应于式(5)中状态矩阵ai,j,存放在16个寄存器中.将这些寄存器依据行移位规则连接到中部ST-box表部分的BRAM上,寄存器中的值就可以作为BRAM的地址,BRAM的输出端则输出对应地址的内容,完成式(5)中的行移位和逆T-box的代换.最后,再将状态矩阵中的1列所需的4个逆T-box代换的值与该列对应的轮密钥一同进行异或操作,就可以得到新的状态矩阵中所对应的列.
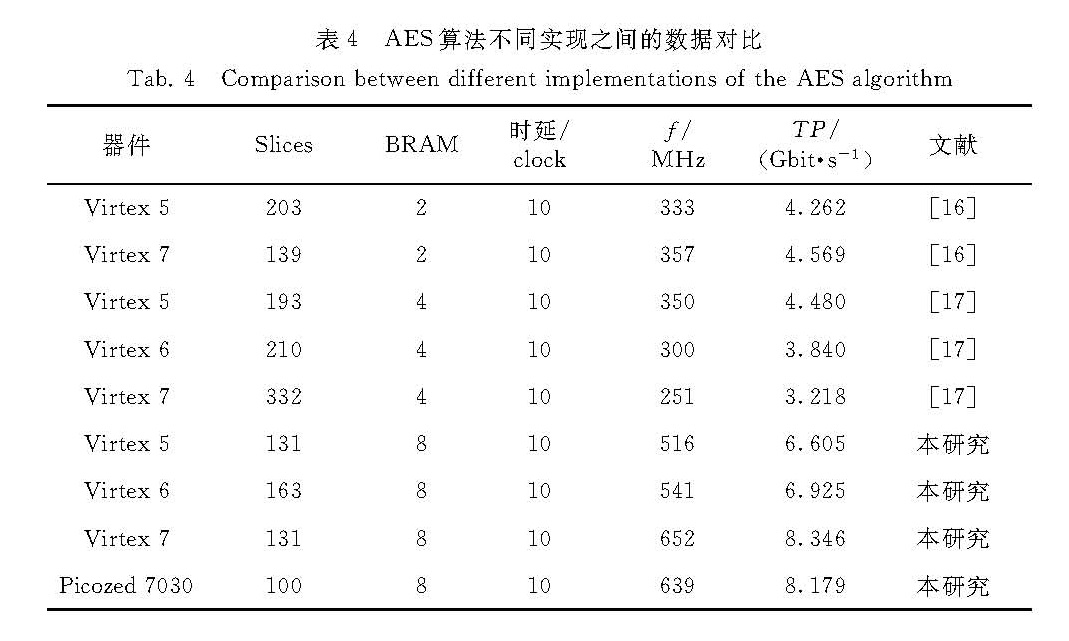
表4列出了本研究设计的AES架构的数据与其他文献的对比.文献[16]和[17]在时延(每处理一个数据块所需clock数)方面与本研究相同,但是本研究的AES架构在各平台都能达到较高的工作频率,在Virtex-7平台中,本研究的工作频率接近文献[16]中的2倍,且获得了最高的吞吐率8.346 Gbit/s.另外,本研究架构在7030平台上实现所需Slice数最少.在各种平台下,文献[16]和[17]分别使用了2和4个BRAM资源,而本研究使用了8个BRAM,可以节约Slice资源,不抢占PBKDF2模块的Slice资源,并且工作频率高,整体的LUKS认证算法电路的频率并不会因AES模块受到限制.综上所述,8个 BRAM的AES架构兼顾了时序和资源的需求,适合本研究的LUKS认证算法设计.
表4 AES算法不同实现之间的数据对比
Tab.4 Comparison between different implementations of the AES algorithm