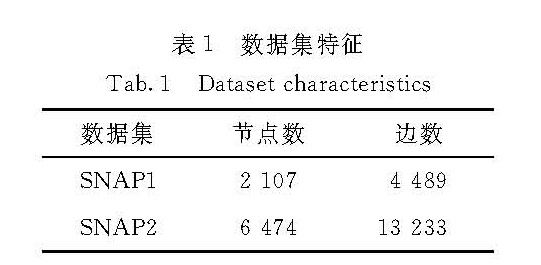
为了同时考虑网元连接关系的重要性和承载业务的重要性,首先需要弄清重要网元的特征.从大规模复杂网络运维实际出发,网元的重要性主要体现在以下两方面:1)重要网元与其他网元的直接连接或间接连接的关系较密切,体现在重要网元与其他网元之间的连通路径较多,一旦重要网元发生故障,可能会影响其他网元之间的通信或服务交互.2)重要网元所承载的业务的数量较多,级别也较高.一旦重要网元发生故障,会影响到承载同样业务的其他网元服务的稳定性.
根据重要网元的特征,本研究将业务转换为图模型上的节点,再利用邻域影响度捕捉节点的连接关系,进而将连接关系的重要性和承载业务的重要性统一起来.本文中的网络基础设施用图模型G=〈V,E〉表示,其中V是所有网元节点vi所组成的集合,E表示网元之间连接关系的集合,即图上两个节点之间的边ei的集合.
对于用图模型G表示的网络基础设施,令A表示有权重图的邻接矩阵.A(i,j)表示边eij=(vi,vj)上的权重.基于随机游走的概念,在图G上的影响力扩散是指从某一节点v0出发,并按一定概率在图上沿节点和边随机移动.假设目前第vs步的随机游走在节点s+1上,则第s+1步将以概率Pst移动到vs的某一相邻节点vt上,即vt∈N(vs),其中N(vs)表示节点vs在图G上的所有相邻节点的集合,其转移概率Pst=A(s,t)/∑vk∈N(vs)A(s,k),所经过的节点路径组成一个马尔科夫链.令D表示一个对角矩阵,其中对角线上某个值d(s)=∑vk∈N(vs)A(s,k),则对应的马尔科夫链的转移概率矩阵P的矩阵表示为P=D-1A.从节点vj到节点vk的长度为l的概率Qjk可以通过转移矩阵P经过l次乘积后相应位置上的对应元素来表示,故Q=(Qjk)=Pl.
当G为非二项图时,由于马尔科夫链的无记忆性,从任何节点出发,经过无限步的影响度最后落在同一个节点vk的概率只和最终节点的度的大小有关.可以通过返回概率c,将影响度倾向于在出发节点的周围的局部的连接关系,同时只考虑长度为l的随机游走,即邻域影响度所能达到的节点与出发的节点的最短路径长度不超过l.值得注意的是,本文中提出的算法可以根据不同需要自由地增大l以扩大邻域的范围.
定义1 邻域影响度:若随机游走的长度为l,则节点vj到节点vk的邻域影响度(影响力)为
Πjk=∑τ:vj,…,vk; le(τ≤l)P(τ)c(1-c)le(τ),
其中,0<c<1,τ是从节点vj到节点vk的一条路径,le(τ)表示路径τ的长度,P(τ)为节点vj到节点vk的转移概率.
由此可知邻域影响度的矩阵可表示为:
Π=∑lγ=1c(1-c)γPγ.(1)
根据邻域影响度(影响力)矩阵,重要网元节点的重要性可定义为
S(vj)=∑vk∈VΠjk,(2)
其中,重要性分值S(vj)表示节点vj的影响力.是根据重要节点对其他节点的影响力,即邻域影响度长度的总和来决定.
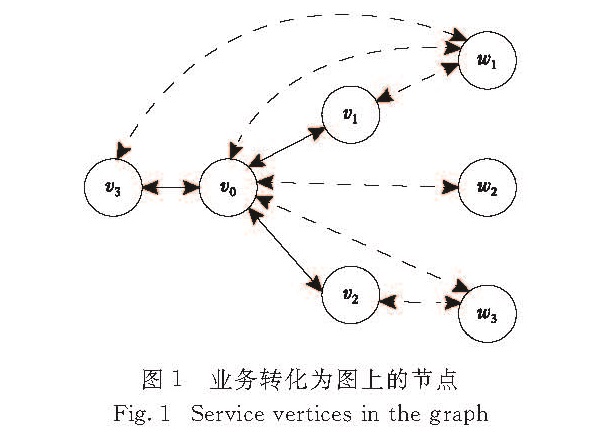
式(2)定义网络基础设施图模型G上的重要性,为了同时考虑承载业务的重要性,本文中提出将业务也转换为图模型上的点,如图1所示.假设网络基础设施中的业务有{w1,w2,w3,…}.每种业务wj在图上都映射相应的节点wj.如果某网元承载某业务,则在图上增加连接网元对应节点vi到业务对于节点wj的一条边e(vi,wj).这样生成的包括业务信息的图模型用G'表示.在图G'上利用邻域影响度来统一衡量节点的重要性,可同时衡量连接关系的重要性和关于业务的重要性.对于业务的级别,可以通过给边e(vi,wj)赋予相应的权重,为简化描述,本文中假设所有业务级别都一样,即相应的边的权重为1.下文中将不区分G'和G,两者都表示包括业务信息的图模型.
图1 业务转化为图上的节点
Fig.1 Service vertices in the graph
网元节点重要性评估算法步骤为:
1)计算转移概率矩阵P.将业务转化为图上业务节点,利用图上网元节点的邻接关系和网元承载业务情况得到邻接矩阵A,根据P=D-1A计算转移概率矩阵P.
2)计算影响力距离矩阵Π.设置合适的随机游走长度l和随机游走的重启概率c,根据式(1)计算Π.
3)根据式(2)计算网元节点的重要性分值.
4)生成重要网元节点列表.重要性分值大于ξ的网元节点称为重要节点,其中ξ表示重要网元节点重要性的阈值.图2所示的是基于本文中实验部分数据集的网络基础设施图G上的网元重要性的分布情况.通过对网元节点影响力的曲线拟合,可见网元节点影响力分布曲线与幂律分布函数y=1.72x-0.06-1的曲线基本吻合,遵循幂律(power law)分布,因此确定重要节点的重要性的阈值ξ并不是绝对的,而是相对的.在下文3.2节对ξ的取值进行了讨论.
图2 网元节点影响力分布曲线
Fig.2 The curve of vertex influence distribution
由于评估节点重要性需要对两个矩阵进行乘积,所以整体的时间复杂度是O(ln3),其中n是图中的网元个数.在实际应用中,可以利用快速稀疏矩阵乘法来代替通常的矩阵相乘算法以加快计算速度.