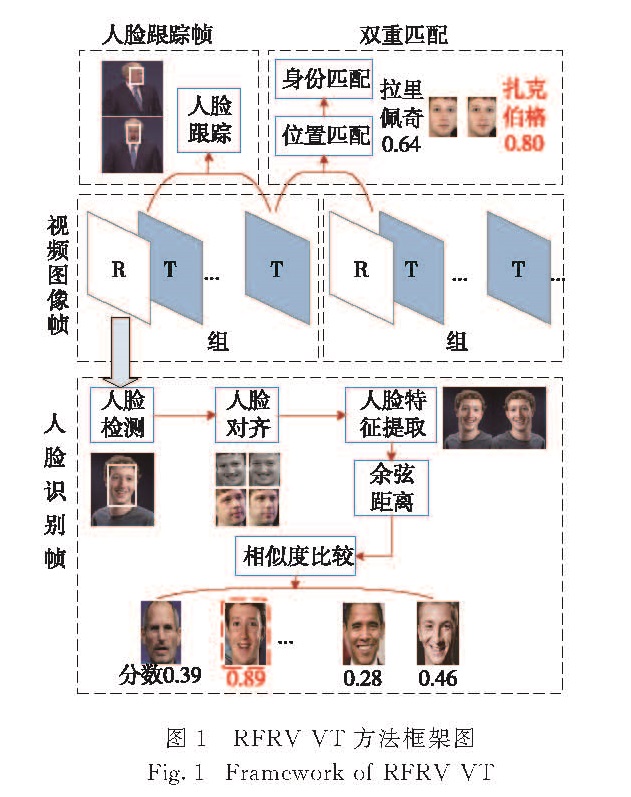
1.1 人脸识别
在人脸识别帧中,首先使用多任务级联CNN(MTCNN)[20]来实现视频图像帧中的人脸检测; 其次,对MTCNN检测到的人脸按照人脸框分割,并使用lightened CNN提取分割出来的人脸图像的特征; 最后,对提取出的特征采用余弦距离进行度量,从而实现人脸匹配.
1.1.1 人脸检测
人脸检测在图像中检测到人脸并返回人脸框坐标的过程,往往容易受到图像质量、光照、人脸转动的等因素的影响.深度学习中,CNN可以在人脸检测中获取更高层次的语义信息,与传统的基于手工特征的检测方法相比,基于CNN的算法更具有鲁棒性.人脸图像经过CNN中的卷积操作,可以产生大量的人脸候选窗口,将人脸候选框输入到softmax分类器,能够得到其是否为人脸的分类结果,从而实现人脸检测.
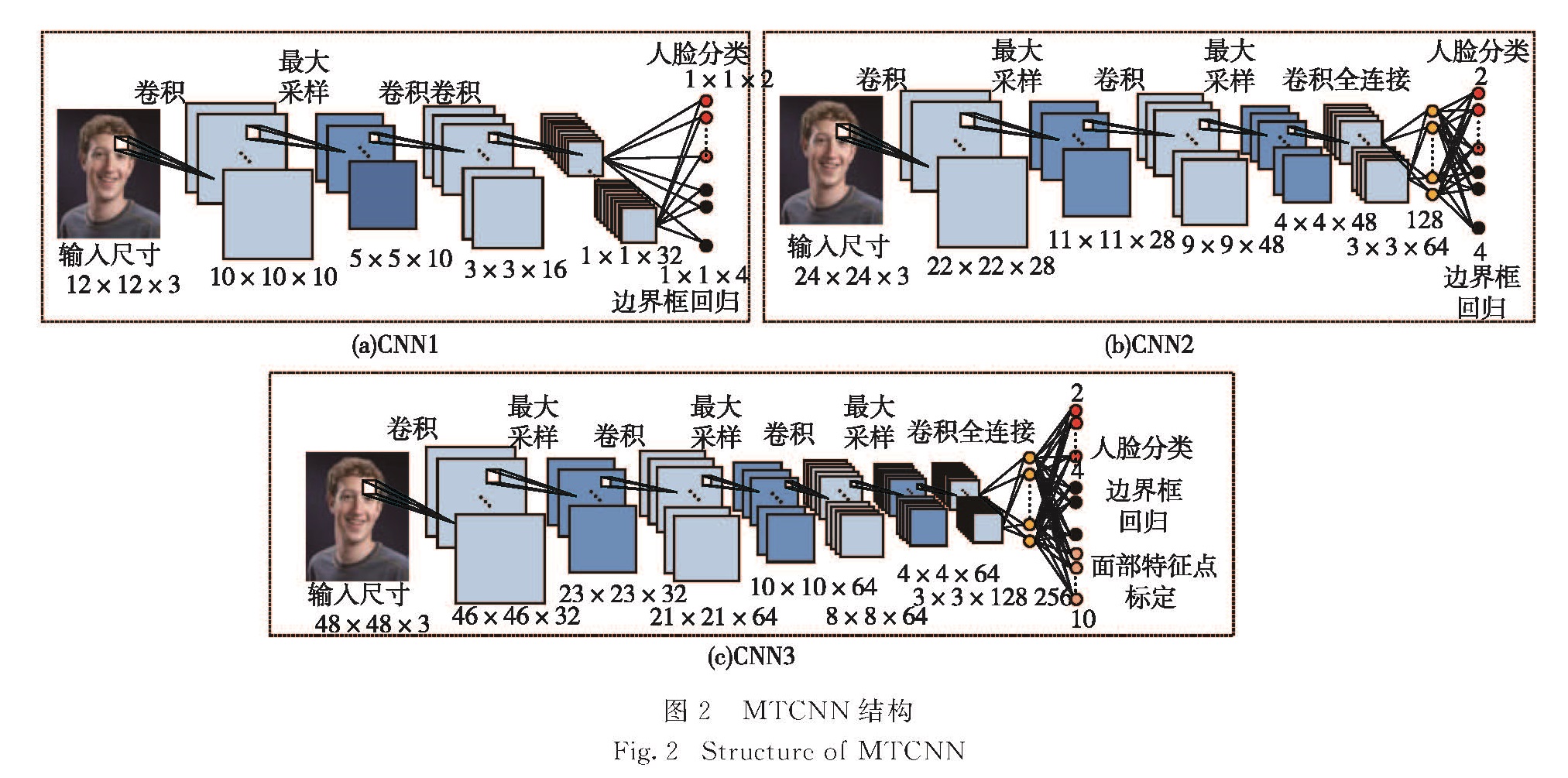
本文中使用的MTCNN人脸检测方法由如下4步构成.首先,对视频帧中的图像进行不同尺度采样,作为卷积神经网络结构的输入; 其次,使用包含3个卷积层的全卷积网络粗略获取一部分人脸窗口候选集,并使用非最大抑制方法来提高检测结果的准确性,如图2(a)所示; 然后将其送入一个4层的卷积神经网络,该网络在第一个网络的基础上增加了一个全连接层,用来去掉更多非人脸的区域,如图2(b)所示; 最后将结果输入到一个5层的卷积神经网络做精细的处理,并输出人脸检测框坐标和人脸5个关键点的位置,如图2(c)所示.MTCNN使用3个CNN级联的方式,实现了由粗到细的算法结构,每个CNN网络是一个分类器,能够得到最有可能的人脸区域.该方法通过减少滤波器数量、设置小卷积核和增加网络结构的深度,实现了使用较少的运行时间获得更好的性能,在人脸转动、光照变化和部分遮挡等情况下能够得到很好的人脸检测结果.
图3 lightened CNN结构
Fig.3 Structure of lightened CNN
图2 MTCNN结构
Fig.2 Structure of MTCNN
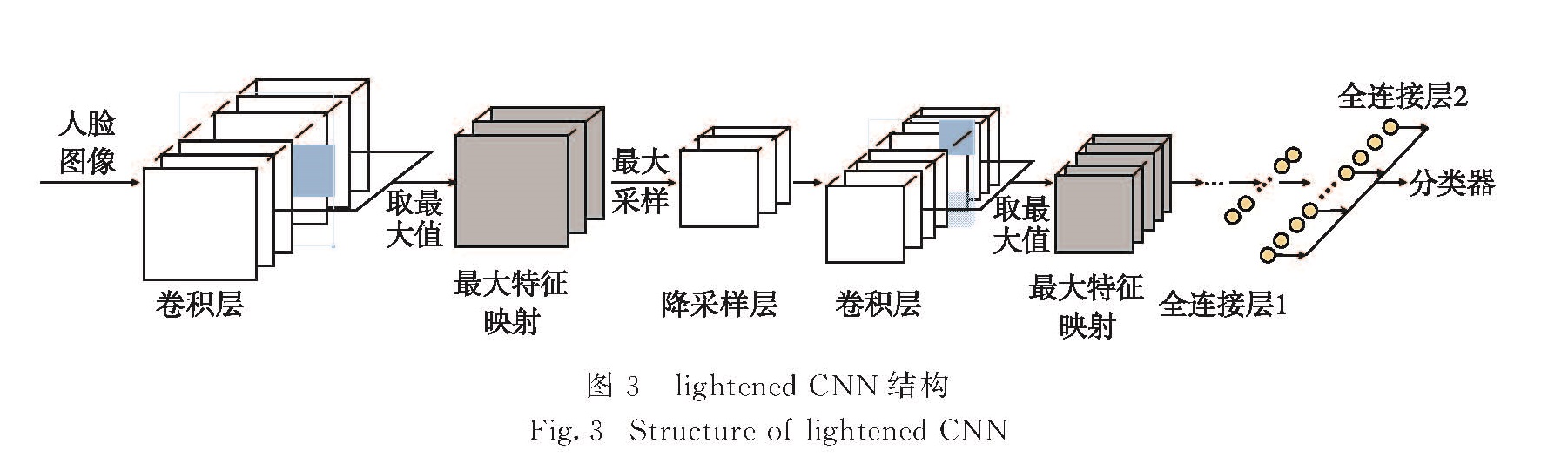
1.1.2 人脸特征提取及其改进
人脸特征提取目的是为了提取出人脸的深层抽象特征,这个抽象特征能够具有区分两个不同人脸的特性.本研究基于lightened CNN[14]来提取人脸的深层特征.如图3所示,模型中包含4个卷积层、4个最大采样层以及2个全连接层,全连接层输出256维的特征向量.模型中使用MFM激活函数,它在输入的卷积层中选择两层,取相同位置的最大值作为输出.假设有输入卷积层C∈Rh×w×2n,MFM激活函数的数学表达式为
lkij=max1≤k≤n(Ckij,Ck+nij),(1)
其中,输入卷积层的通道数为2n,1≤i≤h,1≤j≤w,l∈Rh×w×n.
根据式(1),激活函数的梯度可以表示为
(lkij)/(Ck'ij)={1,Ckij≥Ck+nij,
0,其他,(2)
其中,k'为常数,1≤k'≤2n,并且有
k={k',1≤k'≤n,
k'-n,n+1≤k'≤2n.(3)
由式(2)可以看出,激活层有50%的梯度为0,MFM激活函数能够得到稀疏的梯度.MFM选择2个卷积特征图候选节点之间的最大值,采用聚合统计的方法得到最紧凑的特征表示,而且实现了变量选择,比常用Relu激活函数的高维稀疏梯度更具优点.Lightened CNN采用轻量的结构,在取得比较好的人脸识别效果的同时,加快了识别速度,减小了存储空间的占用,对于监控视频的实时人脸识别具有良好的效果.
为了进一步加快人脸识别速度和提高人脸识别准确度,本研究提出了一种特征融合的新方法.
首先,使用人脸识别图像中人脸区域图像和其水平旋转180°的人脸镜像图像,分别输入到lightened CNN中,得到两个256维的向量.在一般图像任务的神经网络模型训练过程中,将训练数据集中的图像进行镜像、旋转等,能够产生更多的有效数据,提高模型的推广能力.受此启发,在本研究中,使用人脸原图像和镜像图像提取特征,以期得到更丰富的人脸信息,有提高识别准确率.
接着,使用特征融合函数将两个特征向量每一维的最大值融合形成一个新的特征向量,具体的特征融合函数为
hx=max(ax,bx),x=1,2,…,m,(4)
其中,x表示第x维,m是特征向量的维数.
最后,在人脸特征提取中,提取的特征维数太多会导致特征匹配时过于复杂,消耗系统资源,为了降低运算复杂度,本研究使用PCA算法将融合得到的256维特征向量进行压缩降维,最后得到128维的特征向量,在后续特征匹配中能够大大加快计算速度,对本研究中要求的算法实时性具有重要意义.
1.1.3 人脸匹配
本研究使用余弦距离来度量人脸比对结果.两个人脸分别提取出128维特征向量,计算两个特征向量的余弦距离,代表两个人脸的相似程度,如果余弦距离超过某个阈值则认为是同一个人的人脸.当一个人脸与多个人脸进行比对,如果超过阈值的有多张人脸,则取相似度最高的为最终结果.
1.2 人脸跟踪
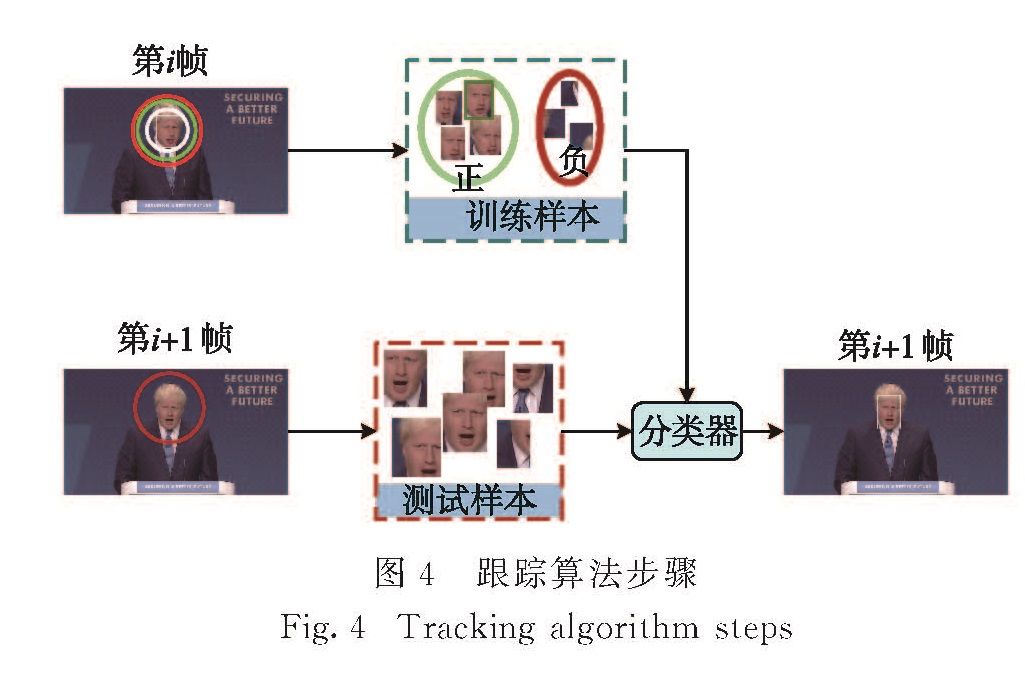
人脸跟踪过程是已知在某一帧中检测到人脸,并标记脸部区域,然后在后续视频帧中继续跟踪标记的脸部位置.在人脸跟踪帧中,本研究使用基于核相关滤波的高速跟踪方法(KCF)[15],将跟踪问题当作一个二分类问题,从而找到目标与背景的边界.
如图4所示,KCF实现目标跟踪的步骤为:假设在视频图像序列i帧中有目标对象,其位置坐标为L(i).首先,在L(i)附近采集负样本,L(i)作为正样本,训练一个目标检测器,将图像样本输入检测器,能够得到该样本的一个检测响应值; 接着,在视频图像序列i+1帧中,在L(i)附近进行采样,并将样本输入目标检测模型中,得到每个样本的检测响应值,即其是人脸区域的概率值; 最后,取响应值最大的样本位置为i+1帧的目标位置L(i+1).
在采集样本的步骤中,KCF利用循环矩阵的性质,将图像候选区域像素矩阵乘以一个循环矩阵,用来表示候选框上下左右移动后新样本的窗口,这样可以快速制造大量新的样本,更多的样本数量能够训练更好的检测器.训练目标检测器时,KCF使用脊回归算法进行训练,计算相邻两个视频帧之间的相关性,算法过程中利用循环矩阵在傅里叶域可对角化的特点,将时域上的卷积运算转换为频域上向量的点乘,这样能够大大减少计算量,如果使用方向梯度直方图(HOG)特征来跟踪,KCF能够达到172帧/s的跟踪速度,并且有很高的准确率.
图4 跟踪算法步骤
Fig.4 Tracking algorithm steps
1.3 视频组间匹配
本研究中人脸识别以视频组为单位独立进行,为了实现相邻组间的信息连接,本研究提出一种双重匹配方法.
相邻的两个视频帧序列组gi和gi+1之间,标记gi中的最后一帧为fgn,gi+1组中的第一帧为fg+11,本研究使用双重匹配方法实现相邻组的连接.
1)位置匹配.算法过程中保存fgn 中所有人脸的框的位置,当在fg+11 中完成人脸检测算法时,计算fg+11 中每个人脸和fgn 中每个人脸的欧氏距离,如果距离小于某个阈值,则认为是同一个人的人脸.若fg+11中有某一人脸与fgn 中所有人脸的欧氏距离都大于设定的阈值,则判定为新出现的人脸.
2)身份匹配.fg+11 帧完成人脸识别过程后,比较fg+11 和fgn 相对应的人脸身份信息.如果不相同,则需要比较两个身份的相似度大小,取相似度比较大的结果为最终识别结果.如果相同,则不需要更新.
通过上述的双重判别方法,两个视频帧序列组gi和gi+1之间实现了连接,同时,身份匹配能够对前一次的人脸识别结果进行矫正,提高人脸识别的准确率.