1.1 稀疏自编码器(autoencoder,AE)
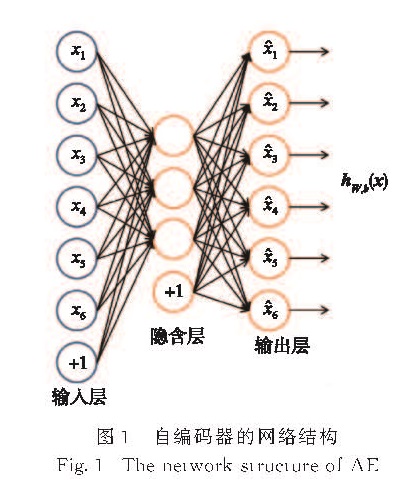
AE是一种无监督学习图像特征表示的方法,它期望神经网络的输出与输入相同,即(^overx)=x,其网络结构如图1所示.
图1 自编码器的网络结构
Fig.1 The network structure of AE
AE的目标是拟合恒等函数hW,b((^overx))≈x,其中,hW,b((^overx))=f(W(^overx)+b),W为权重,b为偏置量.拟合恒等函数看似意义不大,但如果在拟合过程中给网络加入某些限制条件,比如限制隐含层的神经元数目,就可以得到输入数据的结构.比如:假设输入x是一个大小为10×10的灰度图(即n=10),隐含层包含50个神经元,输出(^overx)与x应当有相同的维度; 但由于该网络仅包含50个隐含节点,所以它会强制将输入进行压缩表示,而输出层需要从这个压缩表示中重构包含100个节点的输入x.当输入数据具有结构性,即输入数据的某些特征具有关联性,AE则可以求解出这种结构性.当隐含层的节点数目小于输入节点数时,AE的隐含层学习到的特征是输入数据的低维表示,因此可用于降维.如果AE网络包含一个隐含层,并且使用平均方差损失函数训练网络,那么它的K个隐含节点相当于将输入映射到输入数据的前K个主成分,与主成份分析(PCA)类似.如果隐含层是非线性的,那么AE可以拟合到输入数据的多模表示.当使用多层的AE时,这种不同将更加明显,AE的优势也将更加显著.当隐含层节点数大于输入节点数时,通过对隐含层加入稀疏性限制,可使隐含层节点中大部分神经元处于“抑制”状态,只有少部分处于“激活”状态.这种向自编码器加入稀疏性限制的网络称为“稀疏AE”(sparse AE).
在自编码器网络结构中,若a2j 表示第j个隐含节点的激活值,则第j个隐含节点在训练数据上的平均激活值表示为
(^overρ)j=1/m∑mi=1a2j xi.(1)
加入稀疏性限制(^overρ)j=ρ,使第j个隐含层神经元的平均激活值接近于ρ,ρ表示稀疏性参数.为了满足这个限制,大多数情况下该神经元的激活值接近0.
为了达到稀疏性目标,还需要在目标函数中加入一个额外的惩罚项,用于惩罚那些明显远离ρ的(^overρ)j.稀疏AE的惩罚项具体形式如式(2)所示:
KL(ρ‖(^overρ)j)=∑s2j=1ρlogρ/((^overρ)j)+(1-ρ)log(1-ρ)/(1-(^overρ)j),(2)
其中s2代表隐含层神经元数目.由于惩罚项是基于相对熵(KL divergence)的,因此也可写成 ∑s2j=1KL(ρ‖(^overρ)j).式(2)是以ρ和(^overρ)j为均值的伯努利分布的变量的相对熵,用来衡量两个不同分布的差异性.这个惩罚项具有如下属性:当(^overρ)j=ρ时,KL(ρ‖(^overρ)j)=0; 当(^overρ)与ρ两者的差异增加时,KL(ρ‖(^overρ)j)也随之增大.因此最小化惩罚项可以使(^overρ)j非常接近ρ.稀疏AE的目标函数表示为
Jsparse(W,b)=J(W,b)+β∑s2j=1KL(ρ‖(^overρ)j).(3)
其中:J(W,b)表示自编码器的目标函数; 参数β为用来控制稀疏惩罚项的权重;(^overρ)j依赖于参数W和b,因为它是隐含节点j的平均激活值; 而隐含节点的激活值依赖参数W和b.
1.2 栈式自编码器(SAE)
SAE即多层的AE,它把前一层AE的输出作为后一层AE的输入,即把多个AE的编码部分叠加起来,然后再叠加对应AE的解码部分,这样就形成了一个含有多个隐含层的SAE.
SAE的编码步骤如下:
a(l)=f(z(l)),(4)
z(l+1)=W(l,1)a(l)+b(l,1),(5)
其解码步骤为
a(n+l)=f(z(n+l)),(6)
z(n+l+1)=W(n-l,2)a(n+l)+b(n-l,2).(7)
其中:a(n)是最深层隐藏单元的激活值,是对输入值的更高阶的表示; W(k,1),W(k,2),b(k,1),b(k,2)分别表示第k个自编码器对应的W(1),W(2),b(1),b(2)参数,n为神经元数,l为神经网络的层数.
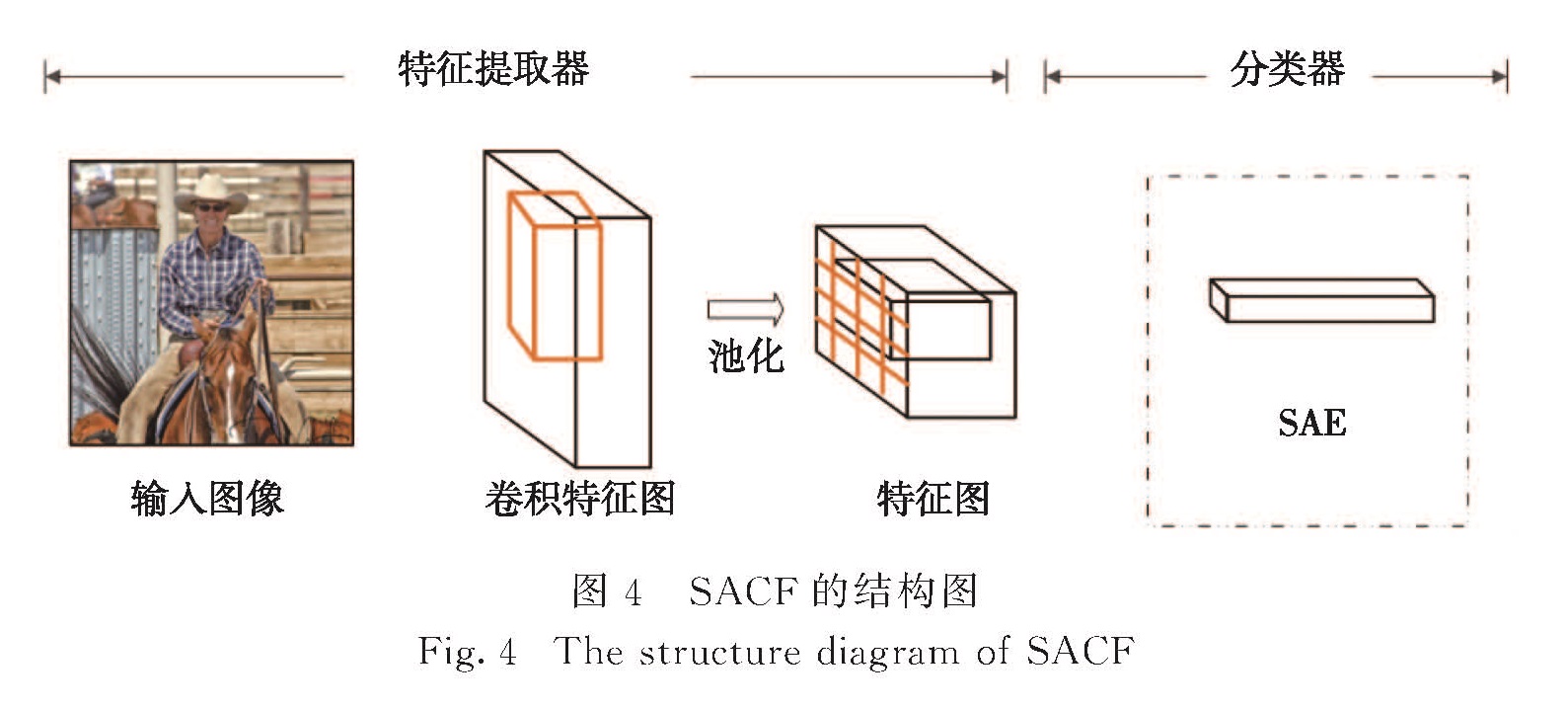
如果把最后一个自编码器的隐含层作为输入数据的高阶特征表示输入到softmax分类器,就可以实现分类.SAE网络结构如图2所示.
图2 SAE的网络结构
Fig.2 The network structure of SAE
由于SAE包含多层,整个网络的参数非常多,如果采用端到端(end-to-end)的训练方法,很容易过拟合.因此,为了防止过拟合现象,在网络训练时,从前到后依次对每一层的AE单独训练,每次只训练一个隐含层.在训练每一层参数时,其他各层参数保持不变.逐层训练将参数训练到快要收敛时,通过反向传播算法调整所有层的参数以改善结果.
AE可以学习到数据的特征表示; SAE则具有深度网络的所有优点,可以学习到更强大的表达能力.SAE第一层可以学习到一阶特征,更高层可以学习到更加抽象的特征表示.对于图像而言,第一层可以学习到边缘,第二层可以学习到由边组合形成的轮廓,更高层次可以学习到更形象、更有意义的特征.