收稿日期:2016-12-21 录用日期:2017-05-27
基金项目:国家自然科学基金(61303082); 厦门大学大学生创新创业训练计划项目(2016Y1131)
通信作者:robin@xmu.edu.cn
基金项目:国家自然科学基金(61303082); 厦门大学大学生创新创业训练计划项目(2016Y1131)
通信作者:robin@xmu.edu.cn
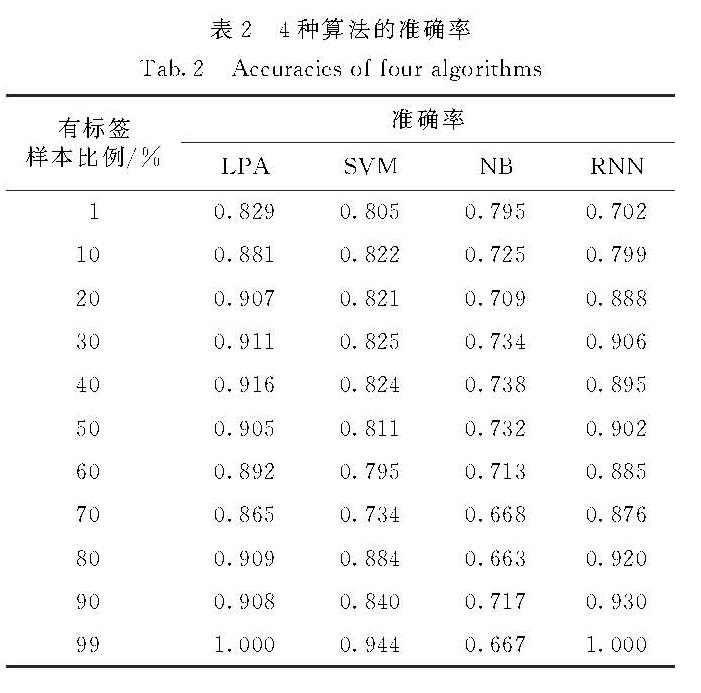
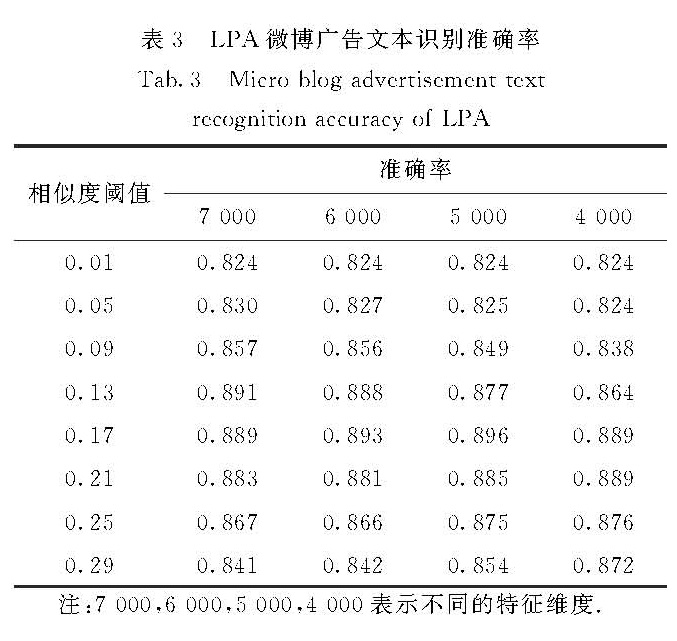
大量的微博广告影响了微博数据分析模型的使用.针对微博广告文本识别问题,利用基于图的半监督的标签传播算法,指导计算机从大量的非结构化的微博文本中自动识别出微博广告.通过对实验数据的评测,结果显示,当已有标签样本较少时,基于图的半监督的标签传播算法能够获得比有监督的支持向量机和朴素贝叶斯算法更好的性能.
Many advertisements in micro-blog affected the use of micro-blog data analysis models.Aiming at implementing micro-blog advertisement text recognition,this paper investigates a graph-based semi-supervised learning algorithm,that is,the label propagation,to recognize micro-blog advertisement from a large number of micro-blog texts.Experimental results on the large-scale data shows that this method achieves a better performance than supervised learning algorithm,such as support vector machine and naive Bayes,do when only very few labeled examples are available.