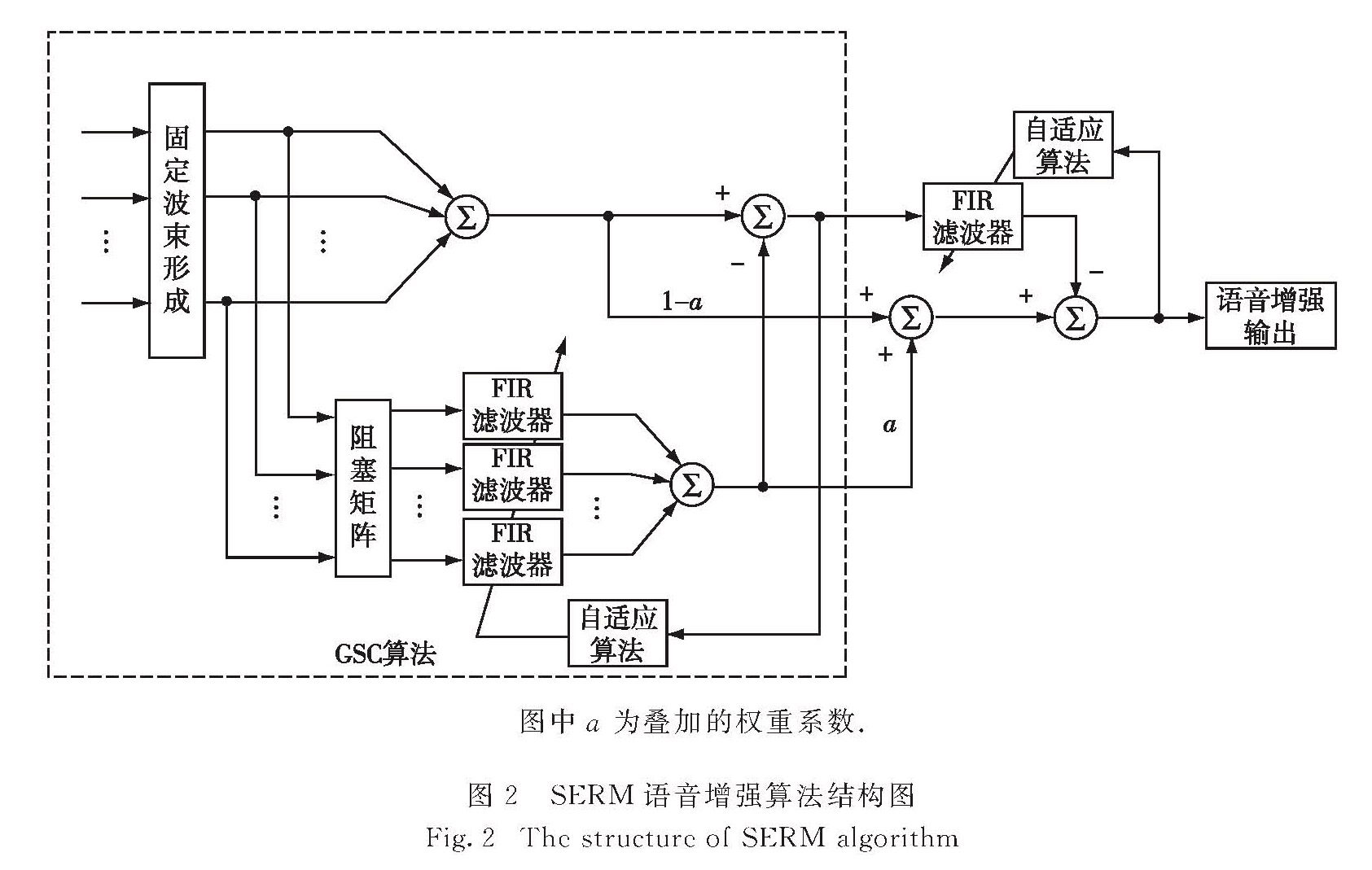
2.1 实验设置
为了验证SEMR算法的有效性,在混响较为严重的室内环境中进行了抗混响语音增强实验.实验房间为典型的办公室,大小为9.6 m×7.8 m×3 m,墙壁为普通水泥抹灰墙面.房间混响时间T60用赛宾公式[22]近似估算为3.5 s.实验采用7元麦克风均匀圆形阵列,阵列直径为15 cm.实验语音信号由0.5~4 kHz的扫频信号和TIMIT标准语音信号[23]组合,其中扫频信号用于测量实验环境的房间传输响应,TIMIT标准语音信号用于评估麦克风阵列输出的语音信号质量,其原始语音信噪比为28.06 dB.播放测试语音的采样率为16 kHz,使用DELL AD211蓝牙扬声器进行播放.
实验中首先通过声源定位算法来获取目标声源的方向信息,以保证算法的性能不受麦克风阵列和目标声源相对位置变化的影响.同时本研究SEMR算法的波束形成方法采用filter-sum方法[12],并比较了其与单麦克风采集语音、filter-sum波束形成算法[12](下文简称波束形成算法)的抗混响性能,其中单麦克风采用的是本文中7元阵列中位于0°方向的麦克风.
表1 实验参数设置
Tab.1 The parameters of experiment
信号采样率/kHz 固定波束形成器阶数 N1,N2 μ1 μ2 0°方向声源相对位置/m a 16 120 32 0.03 0.01 5 0.5
实验中用到的各算法参数如表1所示:波束形成的滤波器抽头系数由声源相对位置来设定,同时为保证语音信号处理实时输出,波束形成器阶数设置为120阶,两部分自适应滤波器阶数N1,N2均设置为32阶.步长因子μ1,μ2选取LMS算法的收敛速度和控制稳态性最优时的值,具体分析见下文.
2.2 实验结果与讨论
将单麦克风和不同抗混响方法处理获得的扫频信号分别进行相关分析,可以得到对应的房间传输响应如图3所示.从图3(a)单麦克风采集语音可以看出,直达声信号在图中约18.75 ms处,在20~40 ms区域以及47 ms处,存在几处较为明显的早期混响成分; 从图3(b)和(c)可以看出,波束形成算法和SEMR算法处理后的语音信号对几处明显的混响成分均有较为明显的抑制效果.实验中进一步进行抗混响效果的量化比较、分析.
图3 房间归一化传输响应
Fig.3 The normalized transmission response of the room
直达混响比[24]RDR是一个衡量房间混响程度的声学参数,定义为直达声信号与混响的能量比值,其计算公式为:
RDR=10lg((h2(t))/(∑t/Δt-1n=0h2(n)+∑L/Δt-1n=t/Δt+1h2(n))),(15)
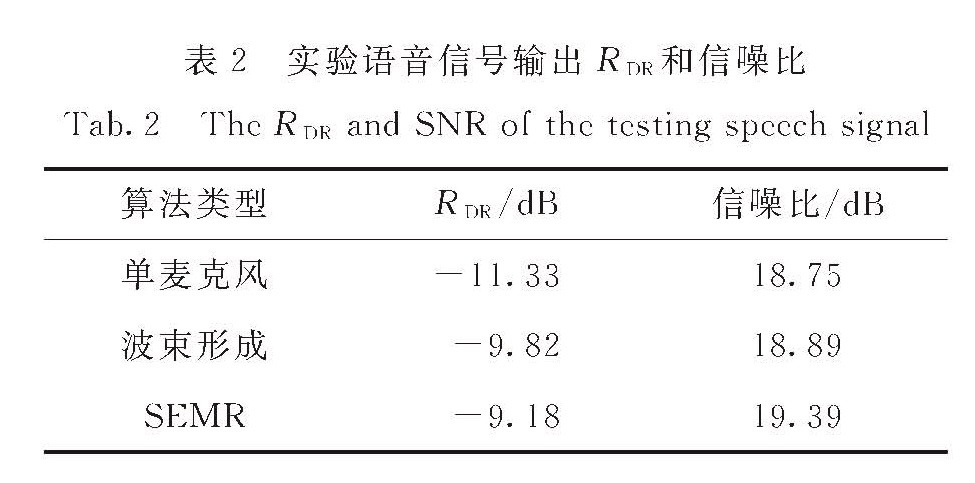
其中:h(n)为语音信号在n时刻的房间传输响应值; t为直达声信号对应的时刻; Δt为采样时间间隔; L为计算时间长度,取值为50 ms,即为早期混响时间段.实验计算3种输出信号在早期混响时间长度下的RDR如表2所示.从表中可以看出,相对于单麦克风输出语音信号的RDR,波束形成算法输出语音信号的RDR提高了1.51 dB,SEMR算法输出语音信号的RDR提高了2.15 dB.作为参考,表2同时列出了测试语音的信噪比,相对于单麦克风输出语音信号的信噪比,波束形成算法输出语音信号的信噪比提高了0.14 dB,SEMR算法输出语音信号的信噪比提高了0.64 dB.可见,SEMR算法的抗混响性能优于波束形成方法.
表2 实验语音信号输出RDR和信噪比
Tab.2 The RDR and SNR of the testing speech signal
图4 语音信号波形图和频谱图
Fig.4 The waveform and spectrogram of the speech signal
图4为语音信号的波形频谱图.可以看出,与原始语音相比,噪声和混响干扰造成单麦克风、波束形成及SEMR算法语音信号不同程度的质量下降; 同时,从图4(a)、(c)、(e)、(g)方框内波形可以看出,SEMR算法输出语音时域波形得到了较好的增强.为了更好地进行性能比较,进一步对实验语音进行语音音质量化评估.
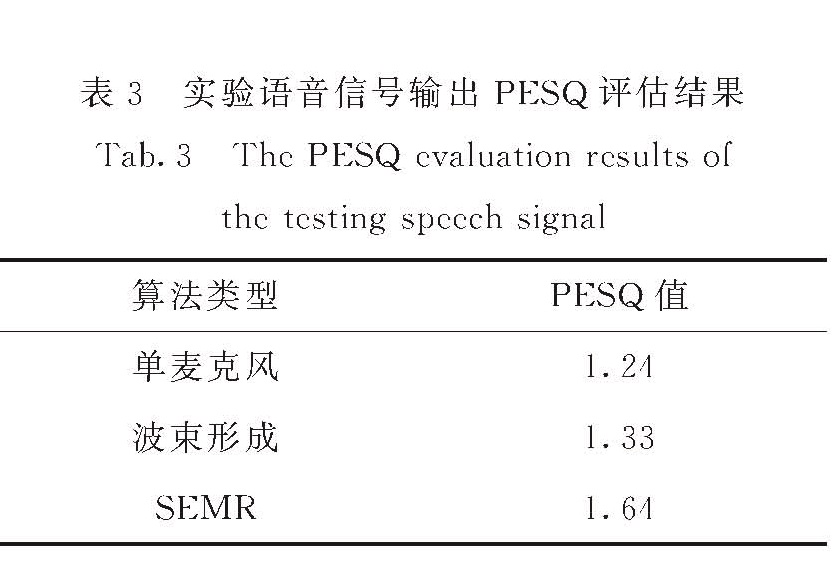
感知语音质量评价(PESQ)是一种采用改进型认知模型技术和听觉模型技术的语音质量客观评价算法[25].其满分为4.50分,得分越高则说明信号质量越好.本文中实验PESQ评估测试的语音信号为国际TIMIT标准语音库的语音片段.3种算法输出语音的PESQ量化评估结果如表3所示.从表3可以看出,波束形成输出的语音信号质量与SEMR算法输出的语音质量均优于单麦克风语音,但SEMR算法输出语音的PESQ得分值更高.可见,SEMR算法输出的语音质量优于波束形成方法输出.
表3 实验语音信号输出PESQ评估结果
Tab.3 The PESQ evaluation results of the testing speech signa
语音识别是目前麦克风阵列的热门研究方向之一,语音识别效果是衡量麦克风阵列性能的一个重要标准,也是本研究算法主要的实际应用背景.本文中对波束形成输出语音和本研究算法输出语音输出进行了初步识别测试.实验采用HTK语音识别工具箱[26]作为识别端,将麦克风阵列输出语音通过声卡以16 kHz采样率输入PC,由PC上运行的HTK识别端进行语音识别.识别实验分别由测试者A和B进行,测试者均位于麦克风阵列0°方向,3 m距离处,测试指令词共40个,实验测试结果如表4所示.从表4可以看出,测试者A和B基于SEMR算法输出识别率相对于固定波束形成语音输出识别率分别提高了10和5个百分点.
表4 麦克风阵列识别性能测试结果
Tab.4 The results of the recognition performance of the microphone array
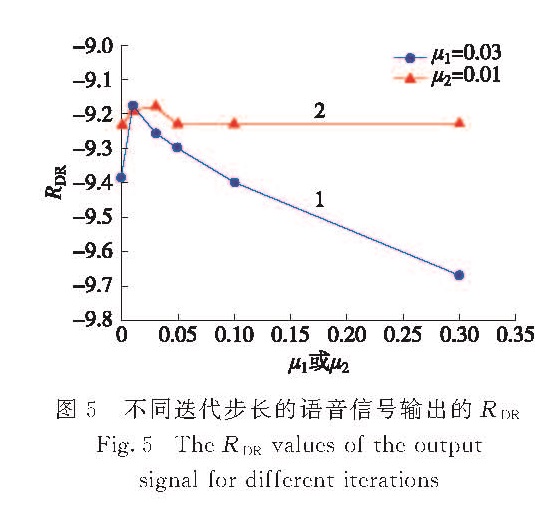
在SEMR算法中,步长因子μ1,μ2是控制LMS自适应算法的收敛性能和稳态失调的重要参数[27],步长因子需适当设置以保证算法性能的充分发挥.实验中测试了SEMR算法中不同步长因子μ1,μ2的语音信号输出RDR如图5所示,其中曲线1表示当步长因子μ1为0.03时不同步长因子μ2的语音信号输出RDR,曲线2表示当步长因子μ2为0.01时不同步长因子μ1的语音信号输出RDR.从图5可以看出,在一定范围内SEMR算法性能对于步长因子μ1具有较好的稳健性,而相对步长因子μ2则较为敏感; 同时从图5可以看出,SEMR算法中步长因子μ1=0.03,μ2=0.01时,算法输出的语音信号RDR较高,抗混响性能较好.
图5 不同迭代步长的语音信号输出的RDR
Fig.5 The RDR values of the output signal for different iterations
![图1 房间传输响应[18]<br/>Fig.1 The room impulse response[18]](2017年05期/pic104.jpg)