1.1 混合树结构模型
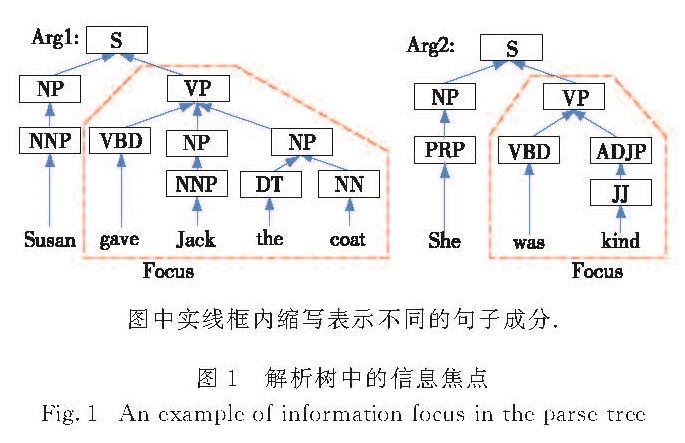
在语法中,谓词一般是句子的信息焦点,它往往决定了整个句子的主体含义.谓词在句子中有特定的表现形式,如连系动词+表语构成复合谓词出现在句子中.例1中“my favorite pet”和“a cat in the pan”就是表语性的名词短语,与前面的系动词在句子中共同充当谓语,影响整个句子意思; 或者通过系动词+形容词构成形容词谓语,例2中“kind”是一个形容词表语,与系动词“was”一起构成形容词谓语.
例1 Arg1:Ada is my favorite pet.
Arg2:It is a cat in the pan.
例2 Arg1:Susan gave Jack the coat.
Arg2:She was kind.
成分树是通过将句子不断按主语-谓语的方式分裂,得到一棵解析树.因此,使用成分树结构构建神经网络来计算两个文本单元的句子向量时,能够更加方便增强谓语在整个句子中的作用,即成分树可以提高动词表语、名词表语或形容词表语对句子向量的影响程度.如图1中虚线框中信息是两个文本单元中需要关注的部分,这部分对句子语义起着重要作用.因此,若构建一个知识向量模型能够区别对待句子中的信息焦点和非信息焦点,则能够准确地获取句子的语法语义信息进而提高篇章关系的识别效果.为了解决上述问题,本研究采用Tree-LSTM神经网络[30]来获取每个篇章单元的语法语义含义.
图中实线框内缩写表示不同的句子成分.
图1 解析树中的信息焦点
Fig.1 An example of information focus in the parse tree
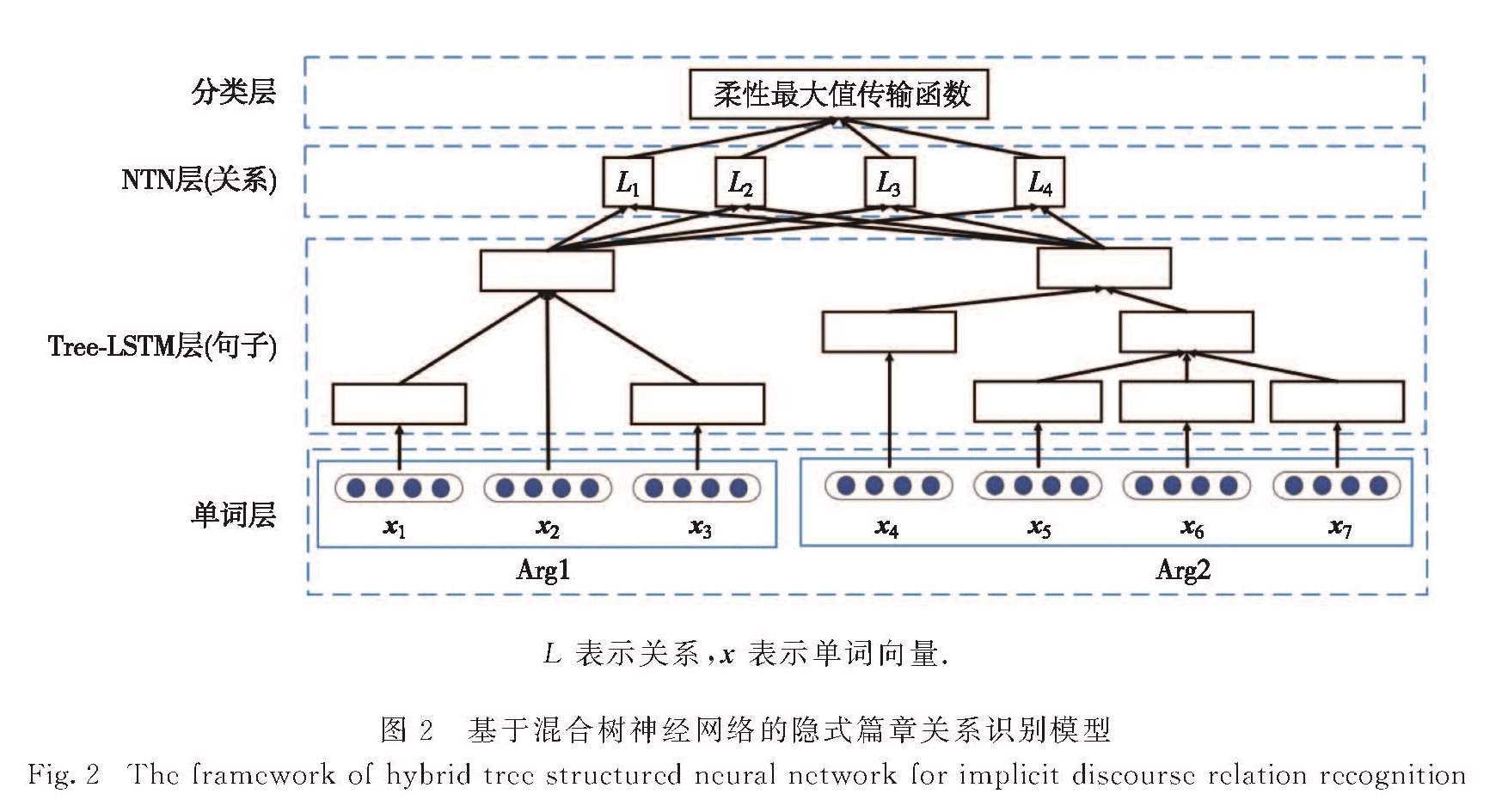
另外,本研究还采用了神经张量网络(neural tensor network,NTN)模型计算两个文本单元句子向量之间的关系.与标准的NTN模型不同,本研究对该模型做了一些修改,使得NTN不再单纯依赖于两个文本单元的句子向量,而是可以融入特征向量提升篇章关系识别的效果.
L表示关系,x表示单词向量.
图2 基于混合树神经网络的隐式篇章关系识别模型
Fig.2 The framework of hybrid tree structured neural network for implicit discourse relation recognition
图2为本研究提出的基于混合树结构神经网络的隐式篇章关系识别模型,图中Arg1和Arg2分别表示隐式篇章关系候选实例中的两个文本单元.第一层是将Arg1和Arg2中的单词转换为低维单词向量,一般单词向量可以随机初始化或者利用大量无标准语料库通过神经网络学习得到.因为这个不是本研究的重点,所以使用Lai等
[32]训练好的word2Vec作为初始单词向量,并将该单词向量作为Tree-LSTM模型的输入,计算句子向量.后续章节将详细介绍该神经网络如何能够学习良好的句子向量和进行篇章关系识别.
1.2 句子向量的语义获取
本研究采用Tai等[30]提出的Tree-LSTM神经网络作为句子语义学习模型,以单词向量作为输入并自底向上学习得到句子向量.在句子语法解析树中非叶子节点的值是以其孩子节点和单词向量作为输入计算得到.相比于RNN神经网络,Tree-LSTM能够解决两方面问题:首先引入了记忆单元能够解决长序列梯度信息反向传播的丢失问题; 另外加入了遗忘门能够选择性地组合孩子节点信息,因此可以加强信息焦点在整个句子中的作用.
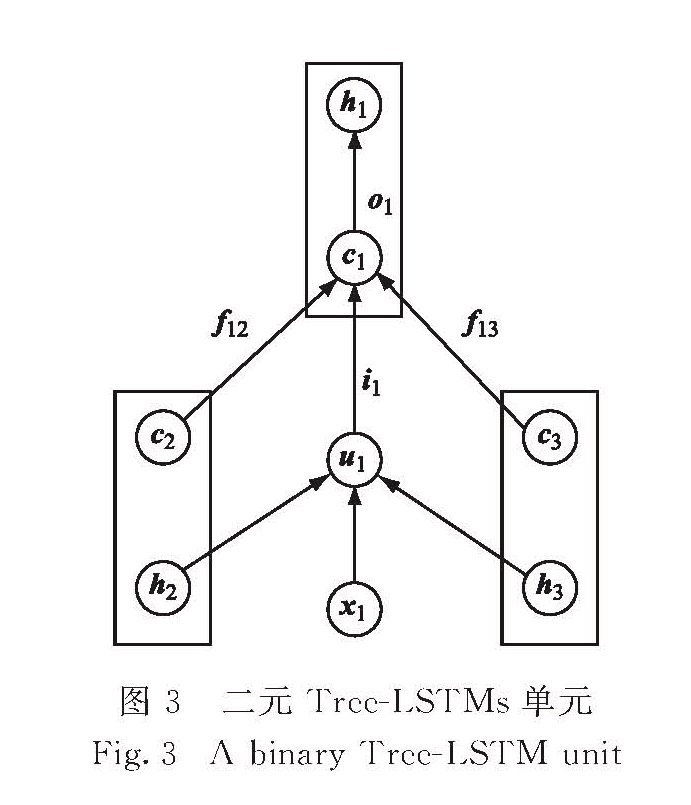
与标准的LSTM一样,Tree-LSTM[33]中第j个节点包含一个记忆单元cj、隐含状态hj、输入门ij和输出门oj.不同的是Tree-LSTM是根据语法解析树结构构建,每个单元的状态值依赖于其多个孩子,如图3所示,单元1的c1值依赖于其两个孩子的c2和c3.对于每个孩子节点k,单元j都有一个对应的遗忘门fjk,可以通过调节遗忘门fjk的值关注信息焦点.
对于任意一个二元Tree-LSTM单元j,cjk、hjk分别表示其第k个孩子节点的记忆单元和隐含状态,因为这里采用成分树来构建二元Tree-LSTM网络,故k取值为1或2,二元Tree-LSTM网络的转换公式如下:
图3 二元Tree-LSTMs单元
Fig.3 A binary Tree-LSTM unit
i
j=σ(W
(i)x
j+∑
2k=1U
(i)kh
jk+b
(i)),
fjk=σ(W(f)xj+∑2l=1U(f)klhjl+b(f)),
oj=σ(W(o)xj+∑2k=1U(o)khjk+b(o)),
uj=tanh(W(u)xj+∑2k=1U(u)khjk+b(u)),
cj=ij⊙uj+∑2k=1fjk⊙cjk,
hj=oj⊙tanh(cj),
其中:σ是sigmoid函数; b(i)、b(f)、b(o)、b(u)表示偏置项; U(i)k、U(f)kl、U(o)k、U(u)k表示孩子节点隐含值的权重,l表示第k个孩子节点的第l个孩子节点; W(i)、W(f)、W(o)、W(u)分别表示输入向量在不同结构中的权重; ⊙表示向量中对应元素相乘.模型中每个单元节点最多只有两个孩子节点,当计算模型中的任何一个单元时,其两个孩子节点分别采用不同的参数矩阵,以实现对其孩子节点的更小细粒度的调节,例如,左孩子节点对应名词,右孩子节点对应动词,那么通过训练可以增大右孩子节点的权重使模型更加关注动词信息.从模型空间复杂度分析,其参数数量规模仅为O(4|h|2),|h|表示节点隐含状态的向量长度,因而该模型体系具有一定的可行性.最后将通过二元Tree-LSTM模型逐步训练得到的两个句子向量传递给NTN模型作为输入进一步识别两个文本单元的篇章关系.
1.3 隐式篇章关系的识别
NTN模型由Socher等[32]提出并成功地应用在实体关系的识别中.受该工作的启发,本研究将两个文本单元的句子向量(s1,s2)作为输入,使用NTN判断两个文本单元之间是否存在某种隐式篇章关系Lr及对应的概率大小.如图4所示,直观地显示了NTN的结构,NTN中引入了一个二元线性张量积将2个句子单元用矩阵相乘的方式紧密关联在一起,代替了传统神经网络直接将两个输入向量首尾相连的方式.根据下面的NTN模型公式,可以计算两个文本之间的篇章关系属于第r个关系(Lr)的概率值.
图4 NTN的结构视图
Fig.4 Visualization of NTN for discourse relation classificationg
r(s
1,L
r,s
2)=U
rρ(s
T1W
rs
2+V
r[s
1s2]+br),(1)
式中:ρ为非线性函数tanh; Wr∈Rd×d×k表示神经张量Ur∈R1×2、Vr∈R2×2d和br∈R2×1神经网络调节参数.
gr(s1,Lr,s2)=Urρ(sT1Wrs2+
Vr[s1
s2]+MrF+br),(2)
其中,Mr表示特征的参数,F是特征向量.式(2)是NTN函数的改进,增加了MrF项,使得NTN模型可以引入特征向量.因此利用该改进的NTN,可以将近年来研究的特征加入到模型中,进一步提高识别效果.根据相关工作的研究成果,模型中加入了有效的特征:单词对特征、依赖树规则、产生式规则和布朗聚类.
模型的最顶层采用softmax分类器来识别两个文本单元的篇章关系.如果在PDTB 4个隐式篇章关系中属于关系(s1,Lr,s2)的概率最大,则文本单元之间的关系定义为Lr,否则不属于Lr.当使用两种隐式篇章关系做分类时,多元分类器会变为二元分类器.
1.4 训练目标
训练目标的目的是使正确篇章关系具有更大概率.模型的所有参数设为θ,所有参数需要通过学习得到.这些参数一部分来自NTN模型:{Ur,Wr,Vr,br}.另一部分参数来自Tree-LSTM:{b(o),W(o),U(o),b(i),W(i),U(i),b(f),W(f),U(f)}.g(i)r=g(s(i)1,Lr,s(i)2)表示第i个文本单元对或样本通过混合树结构神经网络模型计算得到在关系Lr上的分值.通过最小化下面的目标函数来训练模型:
J(θ)=λ‖θ‖22-
1/N[∑Ni=1∑Rr=11{y(i)=Lr}log(eg(i)r)/(∑Rr=1eg(i)r)],
式中:λ是正规项的参数以避免模型出现过度拟合; N表示训练数据的数量; R表示隐式篇章关系集合的个数; y(i)表示样本i在语料库中对应的关系.