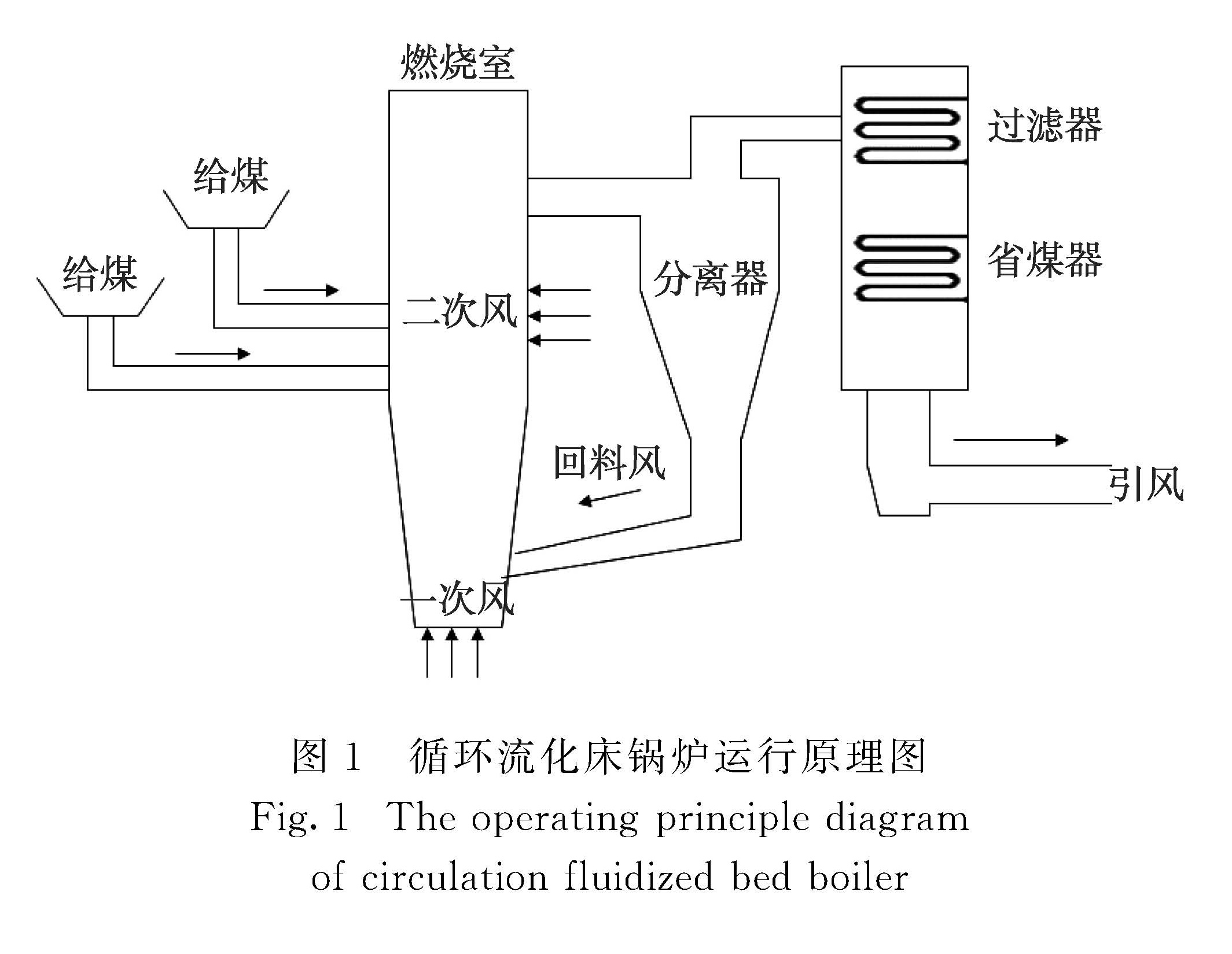
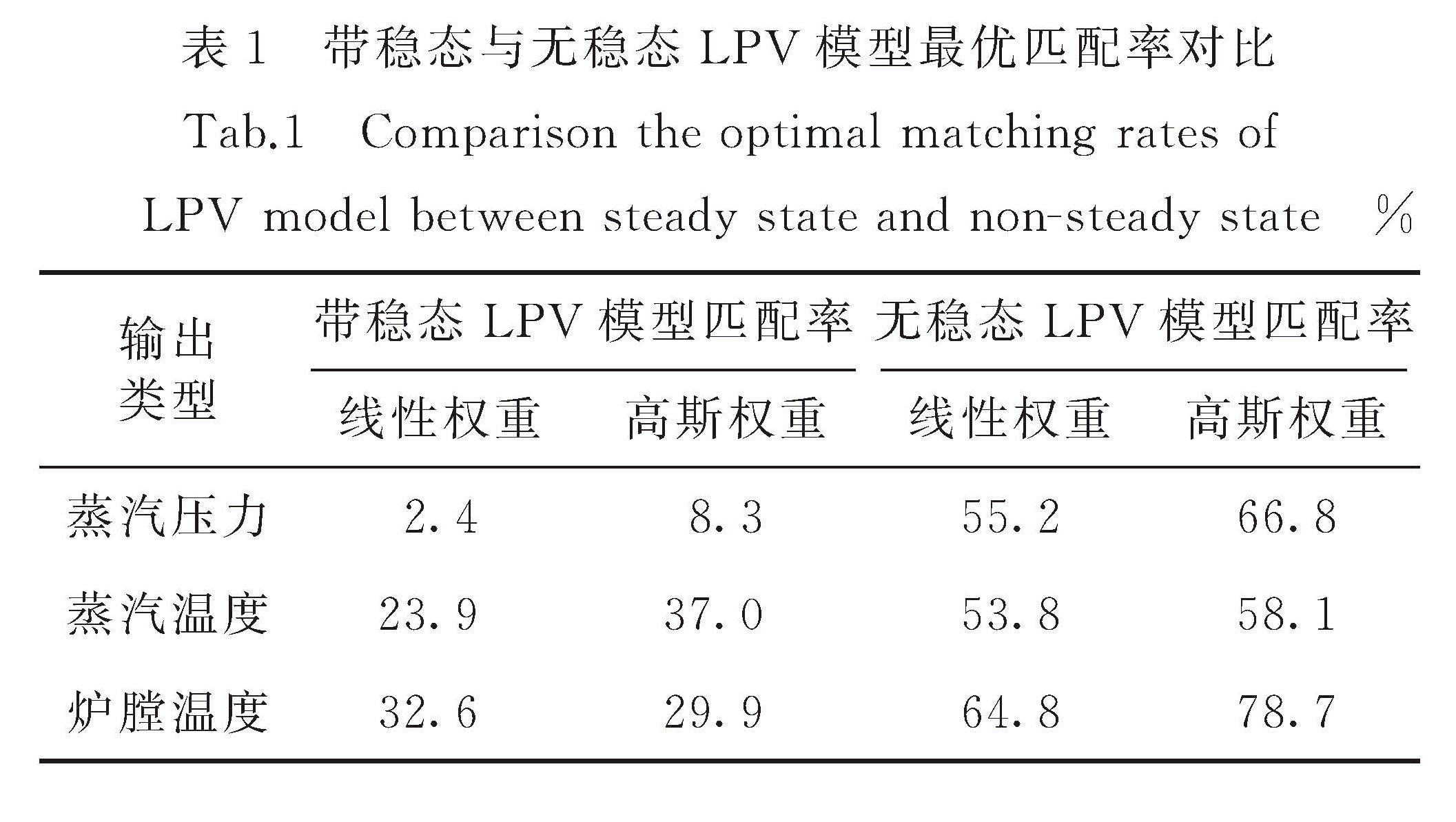
Zhu等[8]提出了一种简化的基于多模型插值的LPV模型结构.其主要思想是:若建模对象的操作轨迹由若干稳态阶段及过渡阶段构成,假定稳态阶段系统模型可近似为线性模型,则系统LPV模型由各稳态阶段的线性模型插值构成.模型权重取决于当前系统运行状态,并由“操作变量”定量描述,所选操作变量是系统中可测或可算变量,要求能够充分反映系统运行状态,即在稳态阶段,其值近似恒定; 在过渡阶段,其值逐渐过渡到另一个相对定值.实践中根据建模对象的非线性复杂程度,一般选择1~2个操作变量进行建模.以m个输入单输出系统为例,记w1(t)和w2(t)为系统的两个操作变量t时刻的取值,假设该系统运行轨迹上共有n1×n2个相对稳态(工作点),其中wi1(i=1,2,…,n1)表示w1(t)上第i个稳态值,wj2(j=1,2,…,n2)表示w2(t)上第j个稳态值.则所有工作点处对应的操作变量值分别为:
[w11,w12],[w11,w22],…,[w11,wn22],…,
[wn11,wn22].
对于带稳态的非线性系统,基于多模型插值的LPV模型输出(^overy)(t)由式(1)计算:
(^overy)(t)=∑n1i=1∑n2j=1αi,j(wi1,wj2)(^overy)i,j(t),(1)
其中,模型权重αi,j(wi1,wj2)是关于两个操作变量的实函数,(^overy)i,j(t)为在稳态工作点[wi1,wj2]处辨识得到的局部线性模型输出.为方便讨论,进一步假设同工作点上的所有线性模型分母相同,且分子分母阶次均为r,将(^overy)i,j(t)细化为式(2):
(^overy)i,j(t)=(^overG)i,j1(q)u1(t)+…+(^overG)i,jm(q)um(t)=
1/(Ai,j(q))[Bi,j1(q)u1(t)+…+Bi,jm(q)um(t)],(2)
其中,(^overG)i,jk(k=1,2,…m)为输出与输入uk(t)之间的传递函数; Ai,j(q)和Bi,jk(q)分别为(^overG)i,jk 的分母和分子,q为单位滞后因子,且满足式(3):
Ai,j(q)=1+ai,j1 q-1+…+ai,jr q-r,
Bi,jk(q)=bi,j,k1 q-1+…+bi,j,kr q-r,(k=1,2,…,m).(3)
此类LPV模型的最大优点在于:根据线性系统叠加定理,只要局部线性模型稳定,则可以保证LPV模型的全局稳定性; 同时,确定局部线性模型后,后续无需对其进行迭代优化,大大降低了辨识难度.但该算法也存在明显局限性,即要求建模对象运行轨迹必须包含相对稳态阶段,才能辨识局部线性模型.对于无稳态过程的对象,如Batch过程,此算法将失效.本研究在此基础上,采用相同的LPV模型结构,探讨无稳态非线性系统的LPV模型辨识问题.
线性函数、多项式函数和高斯函数是最常见的3种LPV模型权重形式.其中,传统多项式权重由于没有对权重值做限制,容易造成插值后LPV模型增益方向错误.虽然这个缺点可以通过增加约束解决[11],但辨识过程中引入了若干拉格朗日乘子,加大了寻优难度,若用于无稳态系统的LPV模型中,将使LPV模型的权重部分和局部模型部分均面临复杂寻优问题,为保证辨识算法的实用性,本研究只讨论基于线性权重和高斯权重的LPV模型辨识算法.
1.1 线性权重LPV模型辨识
对于无稳态非线性系统,局部线性模型无法通过稳态点上数据辨识确定,需进行寻优.双操作变量LPV模型的线性权重形式已在文献[12]中进行推导并给出计算公式,在此不做赘述.线性权重中无待定参数,可直接由当前操作变量值w1(t)、w2(t)确定,所以,辨识无稳态对象的线性权重LPV模型仅需对局部线性模型进行寻优.在式(2)和(3)中,记θ=[a1,11 …a1,1r,b1,1,11 …bn1,n2,mr]为待定参数序列,N为采样数据长度,则θ可通过极小化LPV模型的输出误差εOE(t)来求解:
(^overθ)=argminθ ∑Nt=r+1εOE(t)2=
argminθ∑Nt=r+1[y(t)-(^overy)(t)]2,(4)
其中,y(t)为系统实际输出,将式(1)和(2)代入(^overy)(t)可得
y(t)-(^overy)(t)=y(t)-∑n1i=1∑n2j=1αi,j(wi1,wj2)(^overy)i,j(t)=y(t)-∑n1i=1∑n2j=1αi,j(wi1,wj2)1/(Ai,j(q))
[Bi,j1(q)u1(t)+…+Bi,jm(q)um(t)]=y(t)-∑n1i=1∑n2j=1αi,j(wi1,wj2)
([(bi,j,11 q-1+…+bi,j,1r q-r)u1(t)+…+(bi,j,m1 q-1+…+bi,j,mr q-r)um(t)])/(1+ai,j1 q-1+…+ai,jr q-r).(5)
从式(5)可看出,由于线性权重没有待定参数,所有待定参数均集中在局部线性模型中,并且,ai,jk(k=1,2,…,r)与εOE呈非线性关系,必须采用非线性数值计算方法求解式(4)的优化命题.在此采用高斯牛顿法[13]和最小二乘法相结合的方法进行迭代求解.在每一次迭代中,令式(4)中的εOE(t)在局部最优解附近进行近似泰勒展开,通过求偏导实现待定参数和输出误差之间关系的线性化,随后进行最小二乘解的计算确定下一组待定参数,直至输出误差小于某阈值.具体算法如下:假设(^overθ)kModel 是第k次迭代获得的模型参数序列[a1,1(k)1 …a1,1(k)r,b1,1,1(k)1 …bn1,n2,m(k)r],且接近全局最优解.忽略泰勒展开式中的高次项,则输出误差可近似为
εOE(t,θModel)≈ε(t,(^overθ)kModel)+
(ε(t,θModel))/(θTModel)〖JB>2|〗θ=(^overθ)k(θModel-(^overθ)kModel)=
ε(t,(^overθ)kModel)+φk(t)(θModel-(^overθ)kModel)=
-[φk(t)(^overθ)kModel-ε(t,(^overθ)kModel)]+φk(t)θModel,(6)
其中,
φk(t)=(ε(t,θModel))/(θTModel)〖JB>2|〗θModel=(^overθ)kModel=
[(ε(t,θModel))/(a1,11 )〖JB>2|〗(^overa)1,1(k)1…(ε(t,θModel))/(an1,n2r )〖JB>2|〗(^overa)n1,n2(k)r(ε(t,θModel))/(b1,1,11 )〖JB>2|〗b1,1,1(k)1…(ε(t,θModel))/(bn1,n2,mr )〖JB>2|〗bn1,n2,m(k)r]=
[α1,1(w11,w12)(B1,1(k)1(q)u1(t-1)+…+B1,1(k)m(q)um(t-1))/(A1,1(k)(q)2)
αn1,n2(wn11,wn22)(Bn1,n2(k)1(q)u1(t-r)+…+Bn1,n2(k)m(q)um(t-r))/(An1,n2(k)(q)2)
-α1,1(wn11,wn22)1/(A1,1(k)(q))u1(t-1)
-αn1,n2(wn11,wn22)1/(An1,n2(k)(q))um(t-r)]T.(7)
处理后,ai,jk(k=1,2,…,r)与εOE(t)呈线性关系,可直接用最小二乘法求解.将式(6)~(7)代入式(4),结合最小二乘解式,推导得待定参数序列的下一步估计值为
(^overθ)k+1Model=
[∑Nt=r+1[φk(t)]Tφk(t)]-1∑Nt=r+1[φk(t)]T
[φk(t)(^overθ)kModel-ε(t,(^overθ)kModel)]=(^overθ)kModel-
[∑Nt=r+1[φk(t)]Tφk(t)]-1∑Nt=r+1[φk(t)]Tε(t,(^overθ)kModel).(8)
数次迭代之后,当输出误差小于某个设定的阈值时,即可停止迭代.
上述算法的有效性很大程度取决于待定参数的初值.若初值能够尽可能接近局部最优解,则式(6)的近似误差较小,能够在有限次数内结束迭代.若初值与最优解偏差较大,则难以保证算法的收敛性.在实际应用时,为提高初始局部模型的精度,在无稳态阶段的情况下,应尽量截取所选工作点附近的数据片段进行辨识.常规的线性模型辨识手段均可用于局部模型的初始建模.
1.2 高斯权重LPV模型辨识
双操作变量的高斯权重可记为
αi,j(wi1,wj2)=exp[-1/2(((w1(t)-wi1)/(σ1i,j ))2+
((w2(t)-wj2)/(σ2i,j ))2)],(9)
其中σ1i,j 和σ2i,j是分别对应2个工作点变量的待定分离系数.
与线性权重不同,高斯权重中含有待定参数,故若继续采用式(4)进行参数寻优,则待定参数包含2部分,一部分在权重函数中,另外一部分在局部模型中,且高斯权重的待定参数在指数函数的分母上,显著加大了求解难度.针对此问题,可采用Narendra-Gallman算法[14]求解.该方法的基本思想是,根据待定参数与优化命题的关系,将待定参数分为线性部分和非线性部分,每次迭代分为2步:先固定非线性部分,优化线性部分; 再固定线性部分,优化非线性部分.已有文献证明该方法是处理复杂线性、非线性混合优化命题的有效方法,且具有鲁棒性强、收敛性强的优点.本研究将其应用于无稳态系统的高斯权重LPV模型辨识中,具体步骤如下:
1)确定待定参数初值、迭代结束阈值.
待定参数包括各工作点处的高斯函数分离系数,以及局部线性模型的分子分母系数.其中,根据高斯函数图像特性以及LPV模型的结构特点,分离系数初值设为相邻操作变量值的1/3,如σ11,1 的初值设为(w21-w11)/3; σ21,1 的初值设为(w22-w12)/3.对各组局部线性模型的初值,则选择对应工作点附近的数据进行辨识.设置足够小的正数ε作为迭代结束阈值,当LPV模型输出误差小于ε时停止迭代.设置迭代计数器初值nCount=1.
2)固定优化命题的非线性部分,优化线性部分.
同样采用式(4)作为优化命题.所有待定参数中,局部模型分子上的参数[b1,1,11 …bn1,n2,mr]与εOE呈线性关系,权重参数[σ11,1,σ21,1,…σ1n1,n2,σ2n1,n2]以及局部模型分母参数[a1,11 …a1,1r]与εOE呈非线性关系.按照Narendra-Gallman算法思路,保持非线性部分不变,仅优化线性部分.记当前局部模型分子参数序列为(^overθ)(k)B=[b1,1,1(k)1,…,bn1,n2,m(k)r],直接采用最小二乘法进行优化,得:
(^overθ)(k+1)B=[ΦTΦ]-1ΦTY,(10)
其中,
Y=[y(r+1)
y(r+2)
y(N)],Φ=[(α1,1(w11,w12)u1(r))/(A1,1(k))(α1,1(w11,w12)u1(r-1))/(A1,1(k))…(αn1,n2(wn11,wn22)um(1))/(An1,n2(k))
(α1,1(w11,w12)u1(N-1))/(A1,1(k))(α1,1(w11,w12)u1(N-2))/(A1,1(k))…(αn1,n2(wn11,wn22)um(N-r))/(An1,n2(k))].
3)固定优化命题的线性部分,优化非线性部分.
从理论角度,应保持2)计算出的(^overθ)(k+1)B不变,同时优化剩余的高斯权重参数和局部模型分母参数.然而,经过多次实验表明,由于没有对局部模型分母参数做约束,寻优过程中难以保证局部模型的稳定性,从而影响了插值后LPV模型的稳定性.为确保各局部模型的稳定性,在此仅优化权重参数.很多数值计算方法都可以用来优化权重参数,如最速下降法等.在本步骤中进行内层迭代,每次迭代通过对权重参数序列求偏导,计算负梯度向量并由此确定搜索方向.
4)用式(4)计算LPV模型输出误差VNOE.若VNOE<ε则停止迭代; 反之令nCount=nCount+1,返回2).
值得注意的是,若系统仅含有一个操作变量,1.1节和1.2节的所有算法和步骤依然适用.辨识时仅需删去权重函数的其中一维,减少对应的待定参数即可.