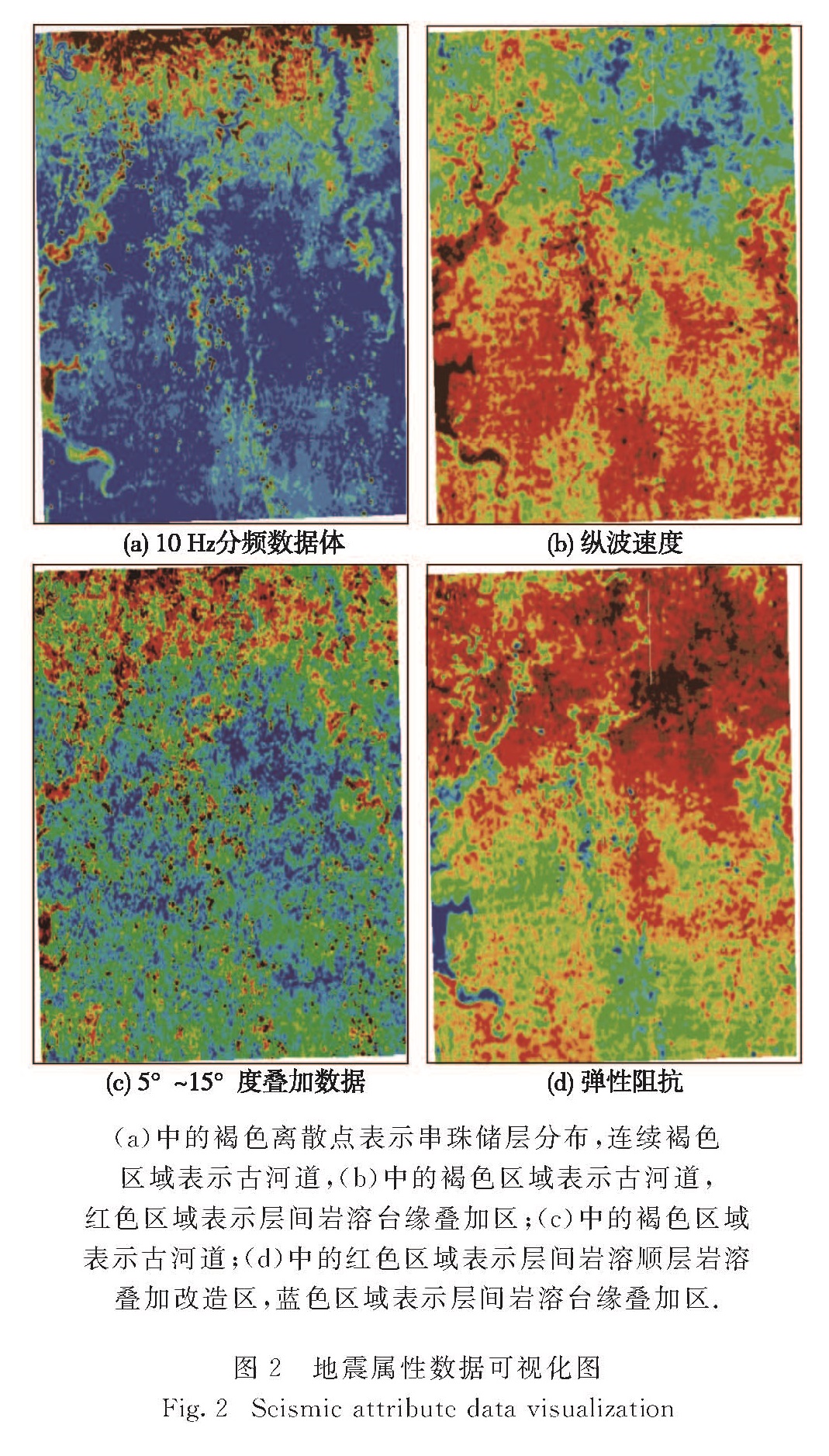
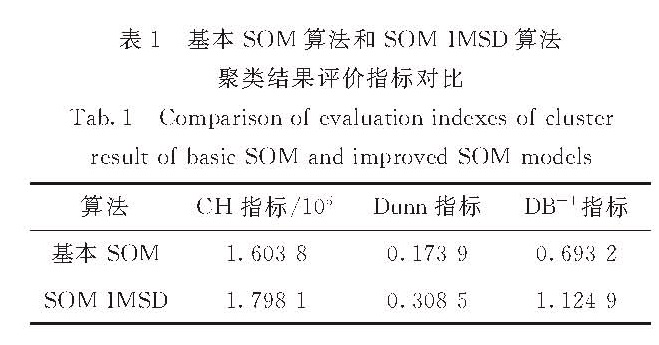
为了解决自组织映射(Self-organization map,SOM)神经网络算法部分神经元过度利用和欠利用的问题,提出基于类内最小相似度的SOM算法(SOM based on intraclass minimun similarity degree,SOM-IMSD),将类内相似度这一评价指标引入SOM神经网络学习过程中,通过调整类内最小相似度来指导SOM神经网络学习,使得平均类内最小相似度最大,提高SOM神经网络的聚类结果质量.将SOM-IMSD算法应用于储层预测,并与基本SOM算法进行对比,实验结果表明,SOM-IMSD算法的聚类结果更为准确.
Intra-Class similarity degree is a commonly used evaluation index to evaluate the quality of the clustering results.It can also be used to weigh the cluster result.In order to solve the problem of excessive use and less use of some neurons,we propose a self-organizing map algorithm based on intra-class minimum similarity degree(SOM-IMSD),which introduce intra-class similarity degree into the process of SOM neural network learning.Adjust IMSD to guide SOM neural network learning,which makes the average IMSD maximum and improves the quality of cluster result.Apply the SOM-IMSD and basic SOM to reservoir prediction and compare the results.The experiment shows that it has improved the clustering results.