2.1 ACF模型
第2行中浅色方框标注的为需要被检测到的人脸,深色方框标注的是被标注为“ignore”的人脸.
图2 Face++人脸检测器标注训练集(第1行)和手工标注测试集(第2行)中有标注的图像
Fig.2 Annotated images from the training set annotated automatically by Face++(first row)and test set annotated manually(second row)
ACF模型是一个基于图像的ACF[12]学习到的分类模型.ACF中最基本的结构是通道,通道对应原始RGB图像的一种线性或非线性映射.通过集合10种通道(3个LUV颜色通道,1个梯度大小通道和6个梯度方向通道),ACF能够融合颜色和梯度信息,因此可以有效地表示人脸样本.从原始的RGB图像到通道的转换如下.
首先,将像素值从RGB颜色空间映射到国际照明委员会(CIE)XYZ颜色空间:
[X
Y
Z]=1/(b21)[b11 b12 b13
b21 b22 b23
b31 b32 b33][R
G
B]=
1/(0.176 97)[0.49 0.31 0.20
0.176 97 0.812 4 0.010 63
0.00 0.01 0.99][R
G
B].(1)
然后,从CIE XYZ颜色空间转换到LUV颜色空间,就得到了ACF模型中的3个颜色通道:
L*=
{((29)/3)3Y/Yn, Y/Yn≤(6/(29))3,
116(Y/Yn)1/3-16, Y/Yn>(6/(29))3,
U*=13L*·(U'-U'n),
V*=13L*·(V'-V'n),(2)
其中,{U'=(4X)/(X+15Y+3Z)
V'=(9Y)/(X+15Y+3Z)是色度坐标,(U'n,V'n)和Yn分别为参照白光的色度坐标和亮度.
在计算每一个像素点的梯度幅值和梯度方向之前,先要计算每一个像素点的水平梯度和垂直梯度:
Gx(x,y)=I(x+1,y)-I(x-1,y),(3)
Gy(x,y)=I(x,y+1)-I(x,y-1),(4)
其中,Gx(x,y)和Gy(x,y)分别表示像素点(x,y)处的水平梯度和垂直梯度,I(x,y)表示对应的灰度值.点(x,y)处的梯度幅值和梯度方向由式(5)~(6)确定:
G(x,y)=(Gx(x,y)2+Gy(x,y)2)1/2,(5)
α(x,y)=tan-1((Gy(x,y))/(Gx(x,y))).(6)
对幅值进行平滑及归一化处理可得到梯度幅值通道.将[0,2π)范围内的梯度方向角均分成6个方向,统计Qθi(x,y)=G(x,y)·1θi[Θ(x,y)=θi],即可得到6个梯度方向通道.其中,θi(i=1,2,…,6)和Θ(x,y)表示量化后的梯度方向,1θi表示指示函数.
给定输入图像,ACF的计算过程为:1)对图像进行平滑,并计算出图像的10个通道; 2)对每一个通道,用一个固定大小的窗口(本文中窗口大小为4×4)在通道图上进行无重叠滑窗,对窗口内的值进行平均池化,得到新的通道图; 3)对新的通道图进行平滑,把所有通道所有位置的值串联成一个向量,即图像的ACF.
ACF模型的分类器是一个由多决策树构成的soft cascade AdaBoost分类器,其结构与Viola-Jones人脸检测器相比有2个不同点:1)该分类器所采用的弱分类器是深度为2的决策树,而不是单层的决策树桩,这样的弱分类器能学到特征的不同维度之间的关系,有利于ACF模型更好地区分人脸和非人脸,提高检测精度; 2)该分类器是软级联的,而不是由多个AdaBoost构成的硬级联分类器,这样的结构有利于检测时快速抛弃负窗口,提高检测速度.
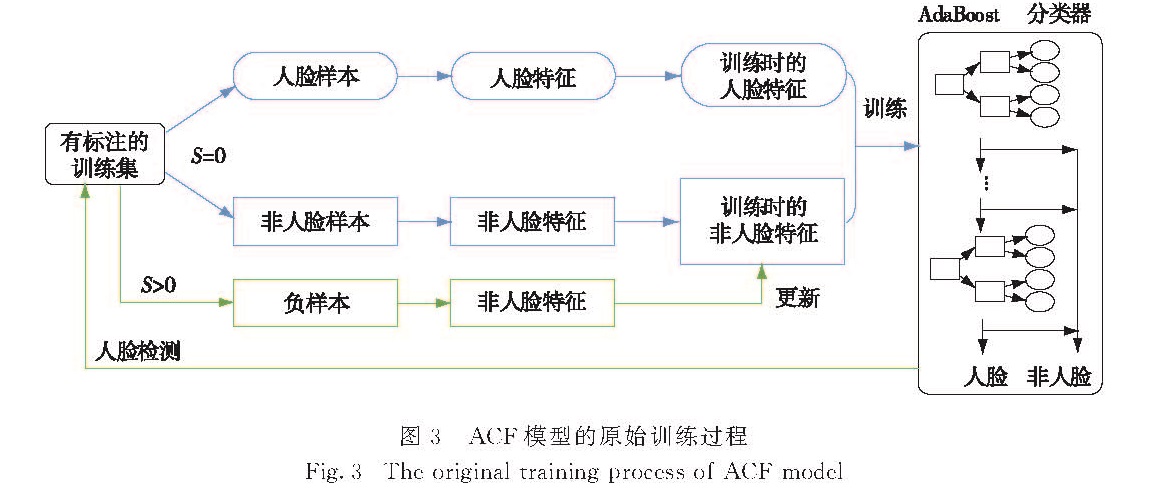
图3 ACF模型的原始训练过程
Fig.3 The original training process of ACF model
ACF模型的原始训练过程如图3所示.1)S=0时,基于已标注的训练集,截取人脸和非人脸样本,并分别提取ACF构建人脸和非人脸特征集作为训练过程的输入,然后训练一个AdaBoost分类器.2)将训练得到的AdaBoost分类器用于有标注训练集上的图像进行人脸检测.3)利用标注信息得到该分类器难以区分的负样本(hard negatives),然后对这些新的负样本提取ACF; 用所有负样本的特征更新训练时输入的非人脸特征集,更新特征集时,新的非人脸特征随机地取代旧的特征集中等量的旧特征; 接着训练新的AdaBoost分类器.4)迭代若干次“检测—更新非人脸特征集—训练分类器”的过程,得到最终的ACF人脸检测模型.
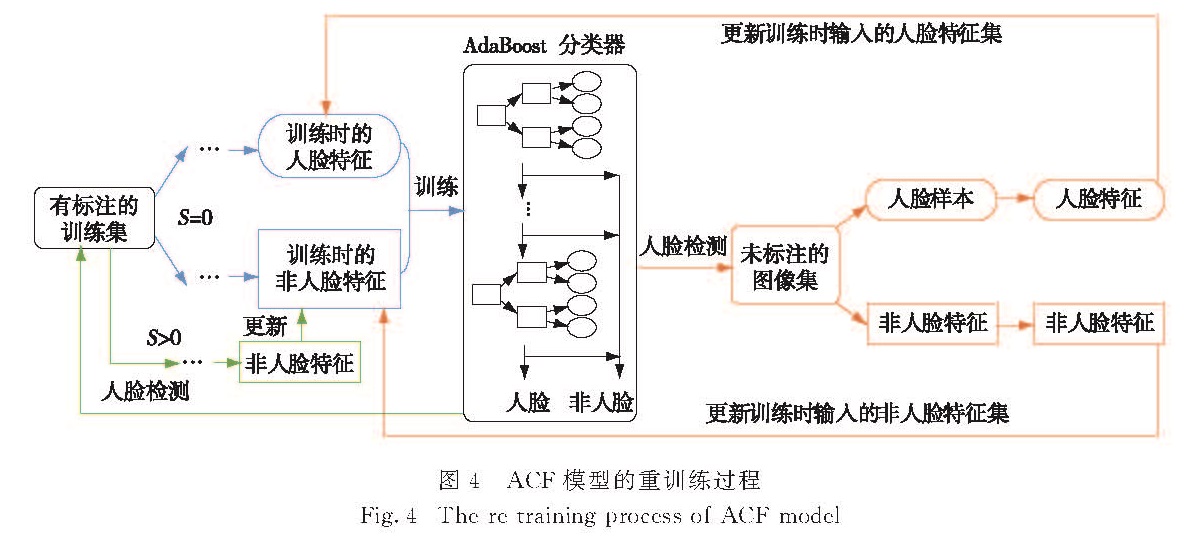
图4 ACF模型的重训练过程
Fig.4 The re-training process of ACF model
其中,利用标注信息收集负样本的具体过程为:首先用训练所得分类器对训练图像进行人脸检测,将每幅图像上置信值最高的若干(本文中为4)图像块收集起来,接着把所收集的图像块中与标注的人脸区域的重叠度(IoU)大于0.1的图像块排除掉,剩下的图像块即为训练所得分类器的负样本.
2.2 模型重训练方法
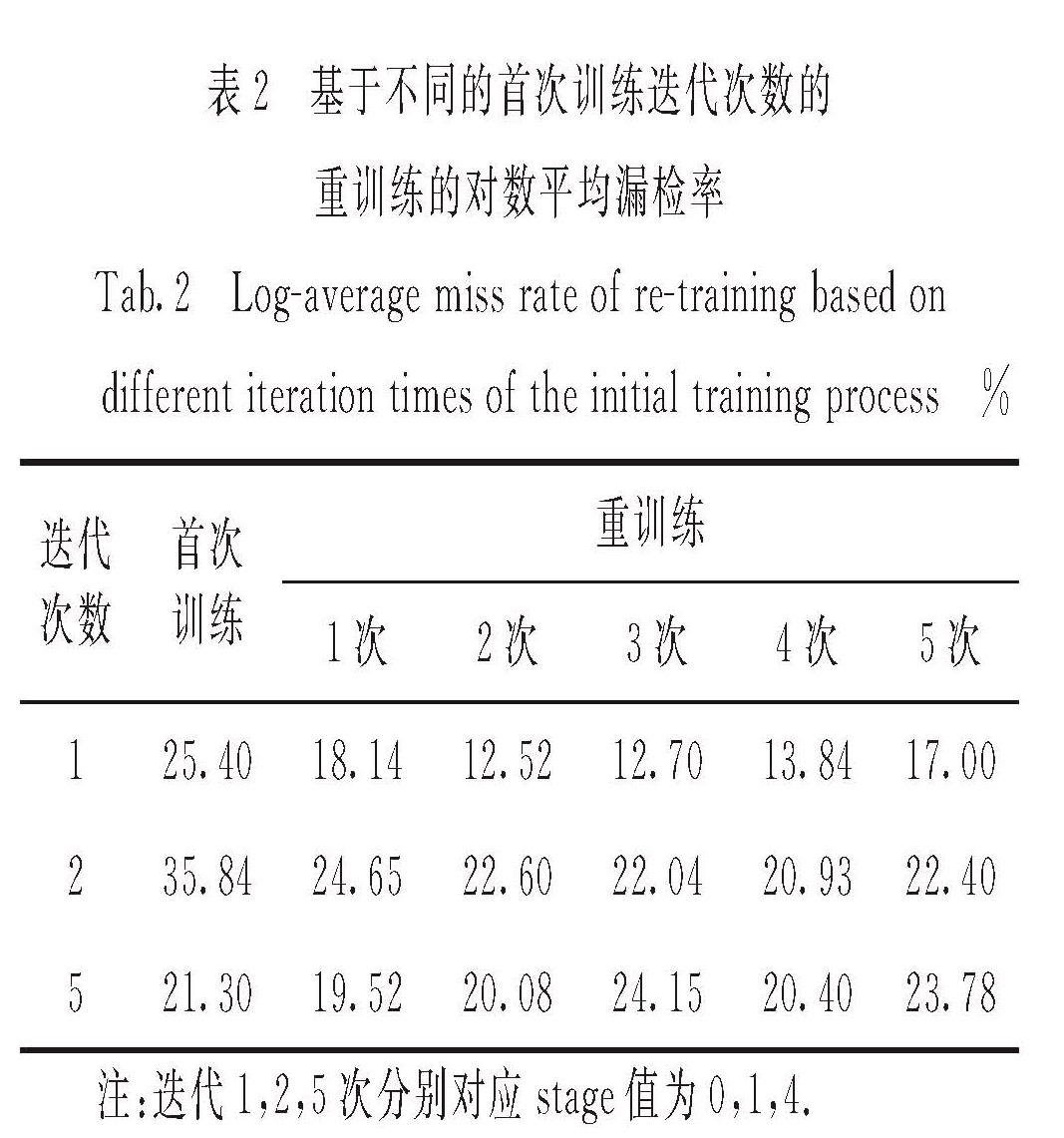
ACF模型的训练过程,本质上是通过多轮的boosting不断地从给定的有标注的训练集中学习人脸知识的过程.为了将ACF模型更好地迁移到新的应用场景,本研究允许对训练集进行扩展,即允许ACF模型自适应地从新场景下未标注的数据中选取新样本,然后重训练.
ACF模型的重训练过程如图4所示.1)如图4左半部分,基于已标注的训练集,训练一个ACF模型(在这里,ACF模型可以是只训练一次的结果,即S=0时训练得到的AdaBoost分类器).2)将训练得到的模型用于未标注图像进行人脸检测; 利用分类器的分类结果从这些图像中收集新的人脸样本和非人脸样本; 然后对这些新的正、负样本分别提取ACF.3)用所有的人脸和非人脸特征分别更新训练时输入的人脸和非人脸特征集; 接着训练新的AdaBoost分类器.4)迭代若干次“检测—更新人脸和非人脸特征集—重训练分类器”的过程,得到最终的ACF人脸检测模型.
其中,利用分类器的分类结果收集新的人脸样本的具体过程为:首先对20 000张未标注图像进行人脸检测,然后对被检测的每张图像收集分类器返回的置信值最高的3个图像块,再把全部60 000个图像块中置信值最高的5 000个作为新的人脸样本.
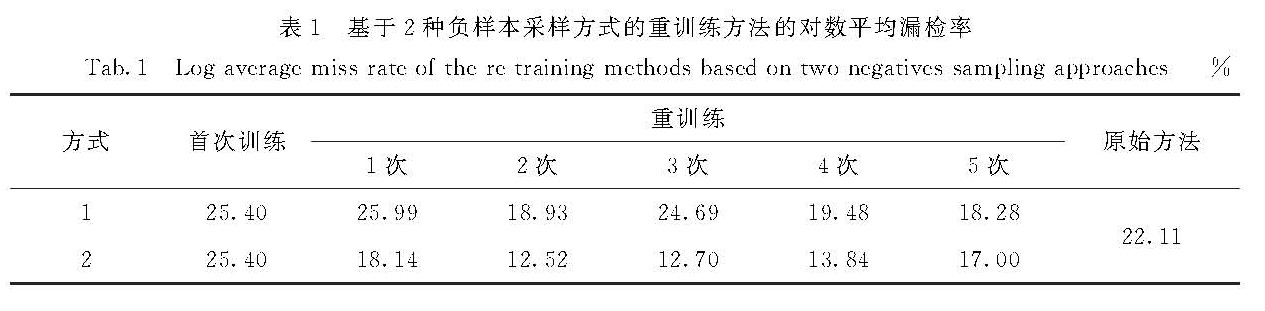
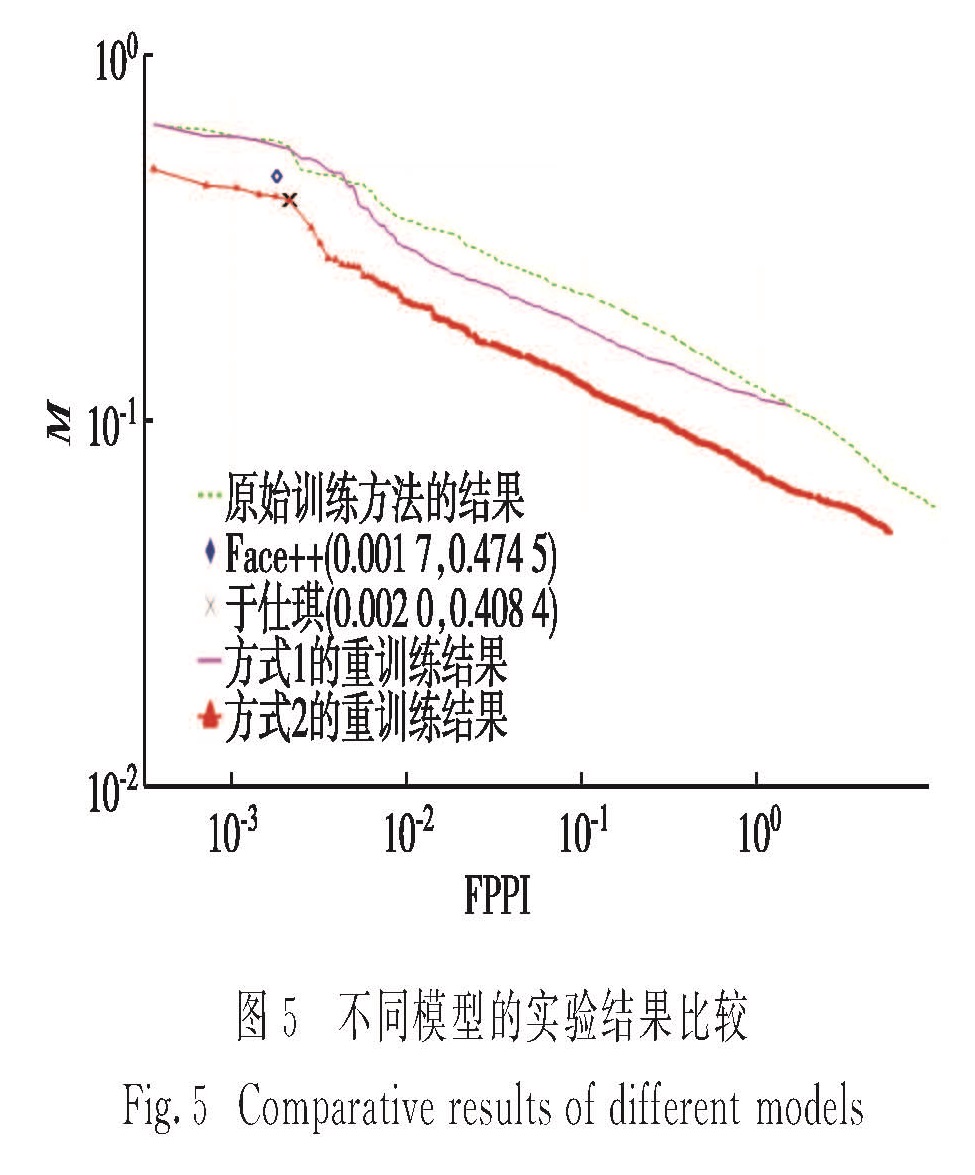
表1 基于2种负样本采样方式的重训练方法的对数平均漏检率
Tab.1 Log-average miss rate of the re-training methods based on two negatives-sampling approaches%
方式 首次训练 重训练1次 2次 3次 4次 5次 原始方法1 25.40 25.99 18.93 24.69 19.48 18.28 2 25.40 18.14 12.52 12.70 13.84 17.00 22.11
新的非人脸样本在同一过程中(对20 000张未标注图像进行人脸检测)选取.从被检测的每张图像中收集非人脸图像块有2种方式:方式1,直接选取分类器的置信值最低的10个图像块; 方式2,模拟选取分类器的负样本,即先排除掉分类器返回的所有图像块中置信值最高的5个,再去掉与这5个图像块中IoU大于0.1的那部分,接着从剩下的图像块中选出置信值最高的10个.然后从全部的200 000个图像块中选取置信值最高的20 000个作为新的非人脸样本.
重训练与原始训练过程存在两点区别:1)在重训练过程中,训练好的分类器被用于对没有标注信息的图像进行人脸检测,以选取新样本,实现无监督的样本更新; 2)该重训练方法不只更新负样本,同时也更新正样本,以使训练时输入的人脸样本更接近真实环境中的样本分布,提高模型在特定场景下的性能.理论上,如果想使得分类器更加鲁棒,应该选择得分较低的正样本来重新训练分类器,然而由于本研究的样本更新过程是无监督的,为了保障正样本的正确性,故选取分类器打分较高的样本来更新正样本.事实上,每一次使用的新的正样本仅占训练时输入样本总数的四分之一,在训练出一个效果更好的分类器后,再基于新的分类器选择新的正样本,即正样本是逐渐更新的,随着更新次数的增加,本研究所使用的正样本会具备一定的多样性.