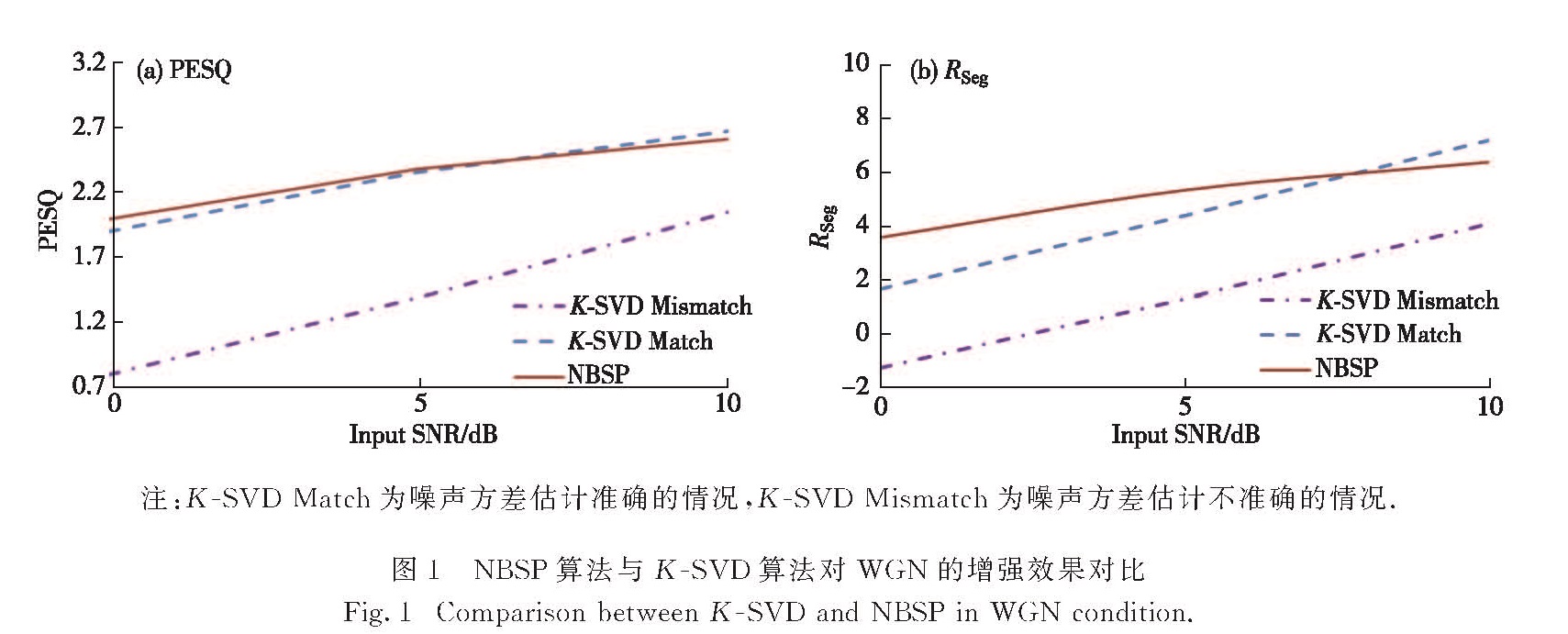
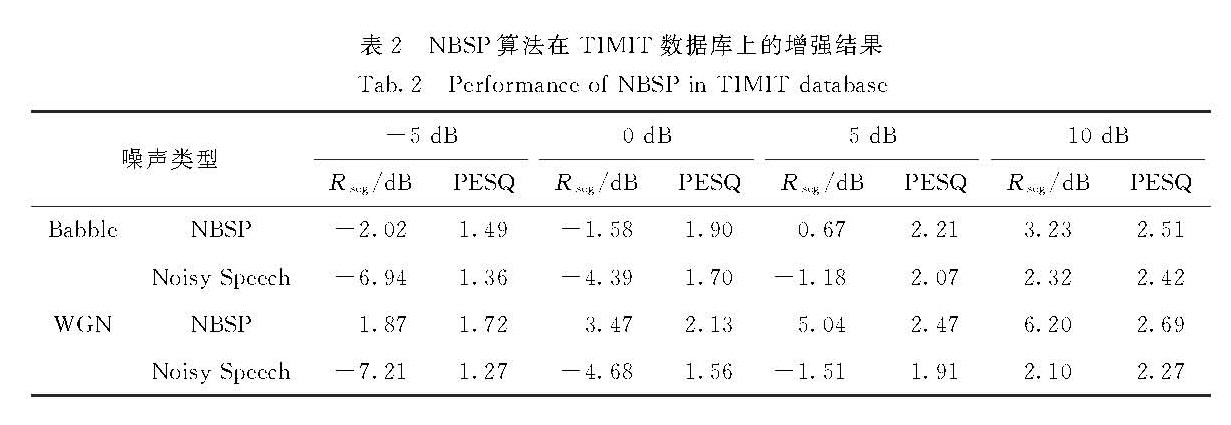
提出一种基于非参数贝叶斯理论的语音增强算法,在稀疏表示的框架下,把字典学习、稀疏系数表示和噪声方差估计融合成一个贝叶斯后验估计的过程,并利用Spike-Slab先验加强稀疏性.首先,将带噪语音分解为干净语音、高斯噪声和残余噪声3个子信号,分别对该3种子信号采用不同的先验概率模型表达,接着采用马尔科夫链-蒙特卡洛算法计算出3个模型中每个参数对应的后验概率,最后基于稀疏表示的框架重构出干净语音.实验数据使用NOIZEUS语音库,采用PESQ和SegSNR作为质量评价指标,分别在信噪比为0,5和10 dB的高斯白噪声、火车噪声和街道噪声上验证了其可行性,并与多种常用语音增强方法进行对比,发现其在低信噪比非平稳噪声情况下的增强效果更为理想.
A new speech enhancement strategy is proposed by utilizing a nonparametric Bayesian method with Spike-Slab priori(NBSP).As a sparse representation framework,the dictionary learning,sparse coefficients representation and noise variance estimation are replaced by a single procedure of Bayesian posterior estimation.First,the noisy speech is divided into clean speech,Gaussian noise and rest noise.Then,each part is modeled with a certain priori distribution.Finally,upon the adoption of Markov Chain Monte Carlo sampling algorithm,the posterior distribution can be obtained,as the clean speech and all other parameters.Without knowing the noise variance,NBSPcould be performed directly on the noisy speech to infer the sparsity of the speech.Experiments were executed on NOIZEUS database.Experiments are executed on noisy speeches from NOIZEUS database with SNR ranging from 0 dB to 10 dB,which contain three types of noise(white,train and street).And the subjective and objective measures like PESQ score and the output SegSNR are implemented to evaluate the performance of NBSP and the other state-of-the-art methods.Corresponding results show that NBSP achieves better performances,especially in conditions of non-stationary noise with low input SNR.