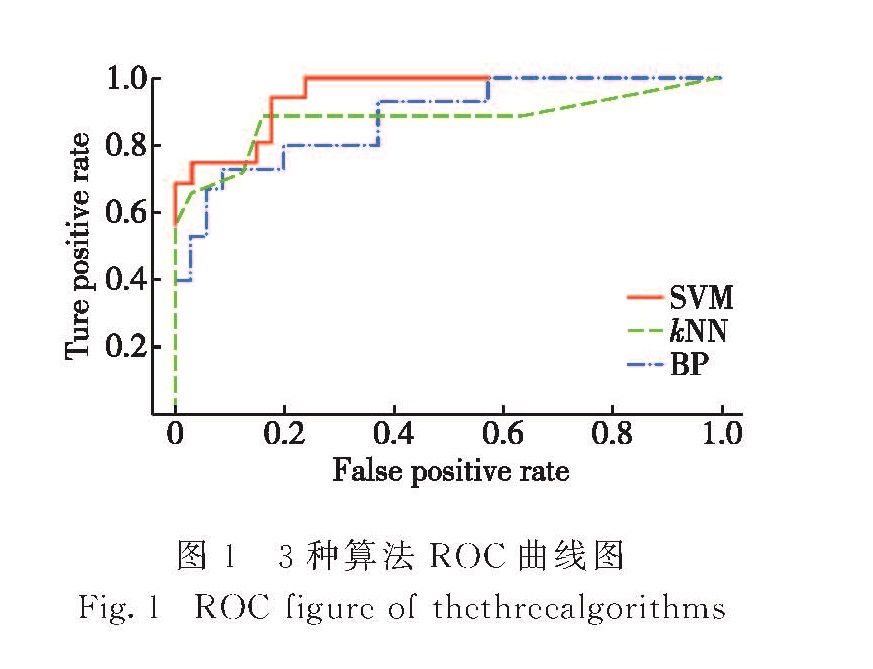
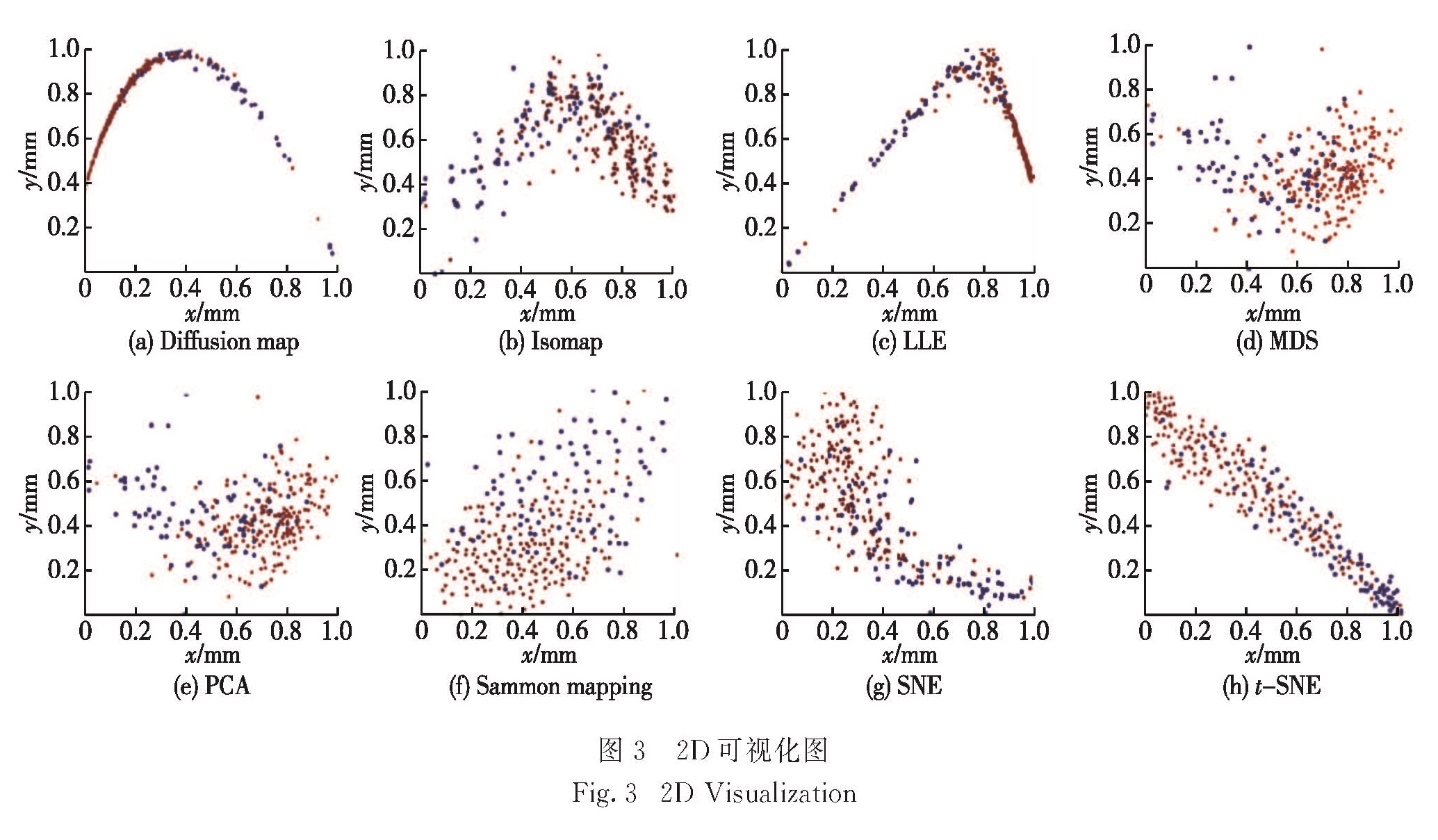
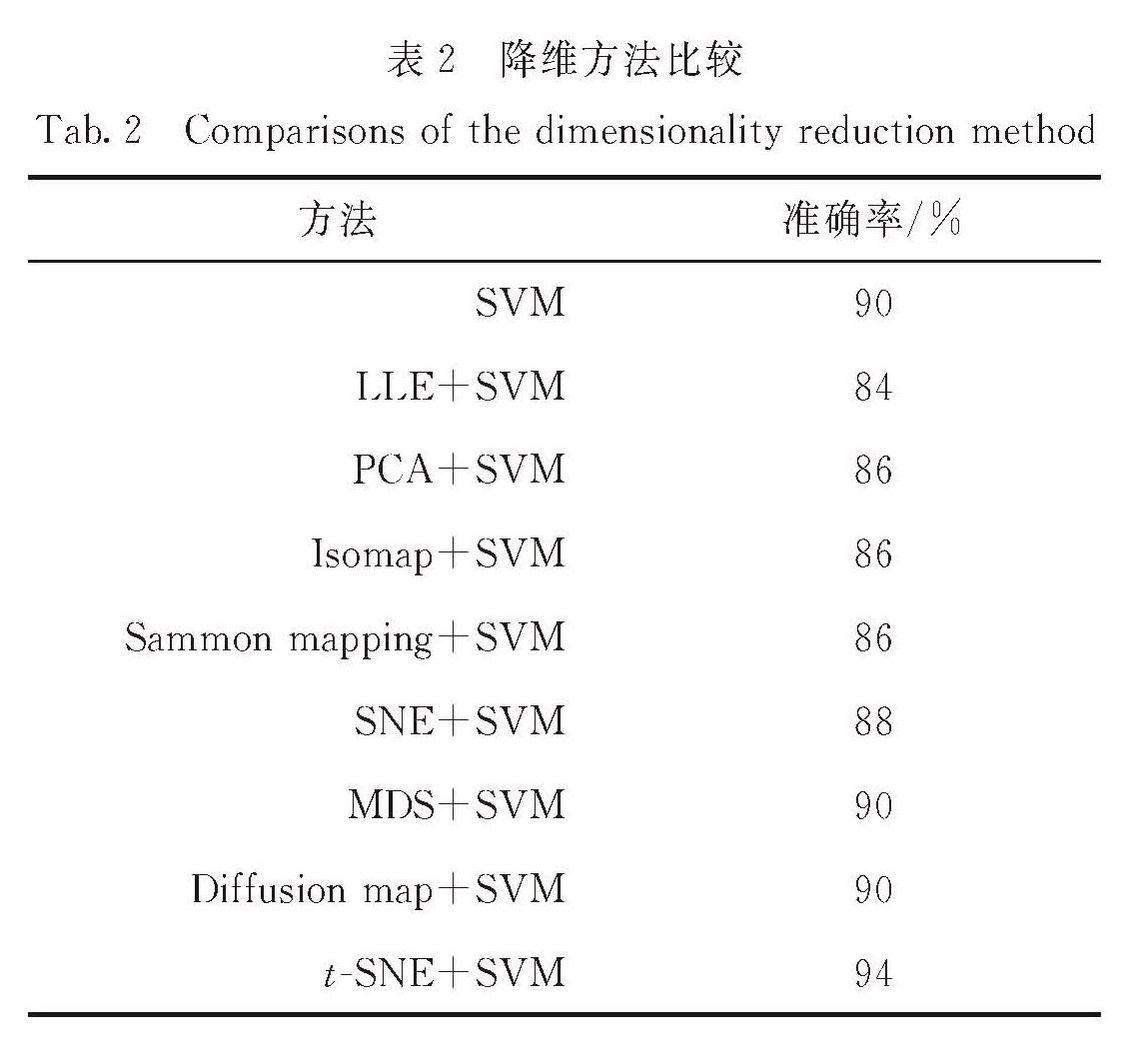
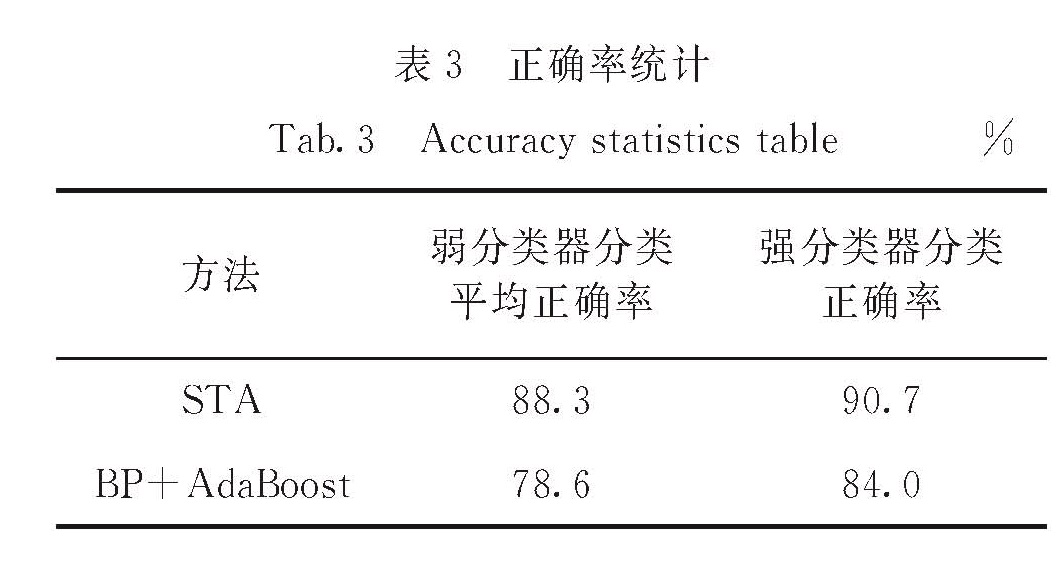
1.1 SVM算法
SVM算法于1995年由Cortes等[6]首先提出,它是基于结构风险最小化原理和VC维(Vapnik-chervonenkis dimension)理论的经典分类算法,可用于解决线性或非线性数据的二分类问题.SVM可将原线性不可分的数据映射到较高的维度上,在高维空间搜索一个最佳分类超平面作为决策曲面,使得两类数据的隔离边缘被最大化[7].
SVM分类算法相对比较复杂,为了提升SVM分类器的性能,需要调节相关参数(比如核函数参数g、惩罚函数c),同时选择最佳核函数.本研究用到K折交叉验证(K-CV)的方法:训练集被均分为K个子集,每个子集需分别做一次验证集,同时其余的K-1组子集数据需作为训练集,由此可得到K个模型,于是用这K个模型的平均分类准确率作为分类器性能指标.对于参数的优化,让g和c在一定范围内取值,利用K-CV方法得到每组g和c下的平均分类准确率,最终选择使得训练集验证分类准确率最高的那组c和g做为最佳的参数.
1.2 t-SNE算法
1.2.1 维数约简
本研究将维数约简的原因有以下两点:1)SVM等机器学习算法的性能和效率经常会受冗余信息以及噪声的影响.为了改进SVM学习性能,可通过维数约简来消除或弱化冗余信息的影响,去除噪声影响.2)SVM可将低维非线性的数据映射到高维空间进行分类,但是本研究用到的AD诊断数据样本集维数并不低.与本次学习任务密切相关的可能是数据的某个低维分布,即高维空间中的一个低维“嵌入”.
维度约简的原则是低维数据要保存原始数据尽可能多的信息,比如本质结构信息.PCA通过搜索最能代表数据的正交向量进行降维,虽然它应用非常广泛,但是它只适用于线性数据集.通过初期实验发现,当48维的AD诊断数据通过PCA降维处理后,再用SVM或BP算法进行分类,并不能提升分类准确率,反而会因为丢失原始数据信息而导致准确率下降,所以该AD诊断数据的结构是复杂非线性的.用非线性映射或许才能找到恰当的低维嵌入,即应该尝试使用非线性降维方法.非线性降维方法包括扩散映射(diffusion map)、等度量映射(isometric mapping,Isomap)、局部线性嵌入(locally linear embedding,LLE)、多维尺度变换(multiple dimensional scaling,MDS)、Sammon mapping、SNE、t-SNE等.
t-SNE由Maaten等[8]提出,它是SNE算法的改进版.t-SNE是一种基于信息论的非线性降维技术,它能从高维采样数据恢复低维流形结构,属于流形学习.t-SNE算法既能撷取原始高维数据的局部信息,同时也能揭示全局簇结构.t-SNE以其优良的降维功能越来越受到学者们的关注,它在数据挖掘、计算机视觉等领域的应用与研究不断拓宽.如Gisbrecht等[9]将t-SNE算法用在多种细菌的基因序列可视化研究中,Cheng等[10]将t-SNE算法用于帮助人的行为识别问题的研究.Yi等[11]结合t-SNE和AdaBoost算法用于人脸表情识别问题的研究.
1.2.2 算法步骤
t-SNE将低维流形嵌入到观测空间,使得在观测空间复杂分布的点在局部具有欧式空间的性质,这不仅使距离计算变得容易,同时也能建立降维映射关系,设法将局部映射关系推广到全局.t-SNE算法步骤如下:
首先计算原始数据集χ={x1,x2,…,xn}在观测空间的相似度.将观测空间中两点间的欧氏距离转化为条件概率pj|i(式(1)),pj|i表示在以xi接受xj作为“邻居”的可能性,它的计算依托以xi为中心的高斯分布的概率密度函数,σ是以点xi为中心的高斯分布的方差.观测空间任意两点xi、xj的相似度量用局部对称联合概率分布pij表示,pij为pi|j和pj|i的平均值(式(2)).pii置为0.
pj|i=(exp(-=xi-xj=2/2σ2i ))/(∑k≠iexp(-=xi-xk=2/2σ2i )),(1)
pij=(pj|i+pi|j)/(2n).(2)
χ通过降维得到对应的y集合,这个寻找最优y集合的过程需要在特定的低维嵌入空间进行多次迭代.SNE等算法都存在的一个常见问题是:在低维空间中,和那些原数据中各点距离较远的点相比,距离更近的更相似的数据点会因为空间容积小的原因而无法得到很好地表示[8].因此需要在低维嵌入空间给各点一个“斥力”,使各个点之间距离变大,特别是使那些不相似的点之间的距离变得更大.一个解决方法是将在低维嵌入空间中的y集合的概率分布置为重尾分布,用不匹配的尾来形成所谓的“斥力”[8].t-SNE使用学生t分布作为重尾分布,将嵌入空间中的点与点之间的欧氏距离以学生t分布为核的联合概率qij
qij=((1+=yi-yj=2)-1)/(∑k≠l(1+=yk-yl=2)-1),(3)
来表示嵌入空间上两个点的相似度,这样能为那些小范围成对的相似点提供更大的空间以便进行更精确地建模.t-SNE能形成长程的“引力”拉进相似点,同时消除不相似的点之间的“引力”,很好地解决了拥挤问题.t-SNE使用相对熵作为目标优化函数,并使用梯度下降法来最小化样本点条件概率P和维数约减后的样本点条件概率分布Q的相对熵[8-9].
1.3 AdaBoost算法
集成学习是提升分类效果的有效方法,其通过让多个学习器(弱分类器)参与学习,共同解决目标问题,从而提高分类器的泛化能力.典型的集成学习算法包括AdaBoost、RandomForest等.AdaBoost算法主要提供一种框架,可以选择使用各种分类器作为基分类器.它的主要思想是[12]:每迭代一次,增大被错误分类的样本权重,减小被正确分类的样本权重; 最终结果是由各个弱分类器的结果加权投票得出,正确率高的弱分类器权重更高,正确率低的弱分类器权重更低.本研究中改进的AdaBoost算法具体实现步骤如下:
1)数据导入,初始化训练数据(N个样本)的分布权重Dt(i)=1/N,设置迭代总次数为S.
2)优先选择权重大的前P个样本进行抽样,然后通过训练得到弱分类器模型,计算该模型误差率为et,et=∑iDi(i),i=1,2,…,N.
3)计算弱分类器权重at:
at=1/2ln((1-et)/(et)),t=1,2… K.(4)
4)调整样本权重.调整公式如式(5)所示,Zt是样本分权值的归一化因子,yi是期望分类结果,gt(xi)是预测分类结果.
Dt+1(i)=(Dt(i))/(Zt)exp[-atyigt(xi)],
i=1,2,…,N.(5)
5)判断迭代次数是否达到S次,‘是'则执行6),否则,返回2).
6)训练S次后得到S组弱分类函数f(gt,at),可计算强分类函数,表达式为式(6),得到结果.
h(x)=sign[∑St=1at·f(gt,at)].(6)